

Tabla de Contenidos
En un artículo previo, les comenté como se puede hacer uso del Java Caching System JCS de Apache Commons. En esta nueva entrega les explicaré como poder usar AWS Elasticache cuando tenemos nuestros servicios ejecutándose en AWS.
En primer lugar, debemos saber que AWS ElastiCache es un servicio administrado de dos de los más populares proyectos open-source de cache distribuido: Memcached y Redis.
Al ser un servicio administrado, nosotros como desarrolladores no tenemos que preocuparnos por instalar el software, gestionar el cluster y todos esos temás administrativos. Por el contrario, nos enfocamos en hacer uso del servicio para atender la necesidad especifica de nuestro desarrollo.
Dicho lo anterior, seguidamente les explicaré como pueden usar Memcached en un desarrollo en Java. El primer paso es ingresar a la consola de AWS y seleccionar la opción de ElastiCache; ahí debemos crear nuestro cluster, como se ilustra seguidamente.
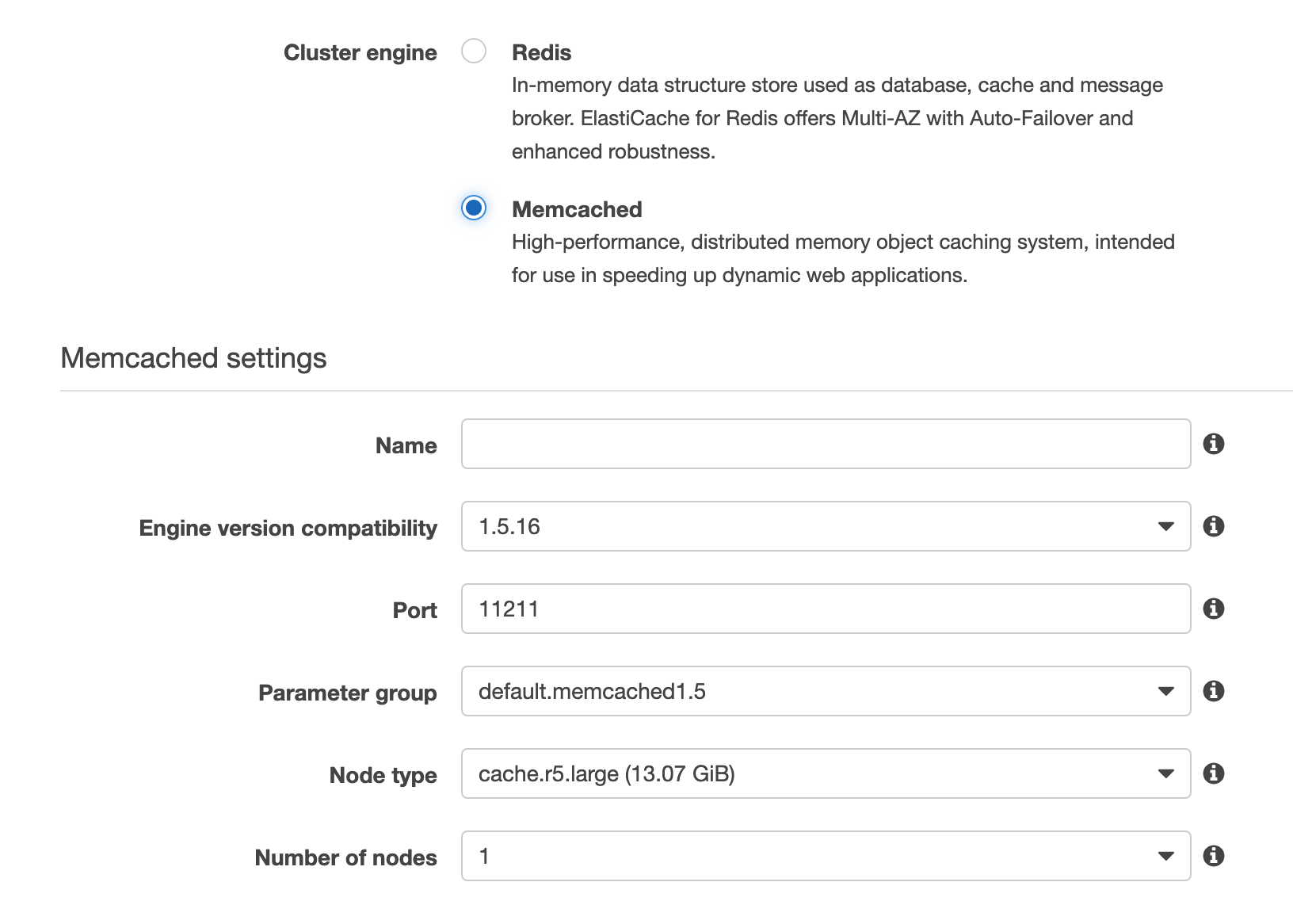
Debemos brindar un nombre para nuestro cluster, versión y otros atributos cómo el tipo de nodo (el cual nos dice que tanto RAM tiene disponible para el cache) y cuantos nodos deseamos que tenga el cluster.
Una vez creado, podemos observar que se nos brinda un endpoint, el cual necesitaremos después al momento de establecer la comunicación al cluster desde Java.
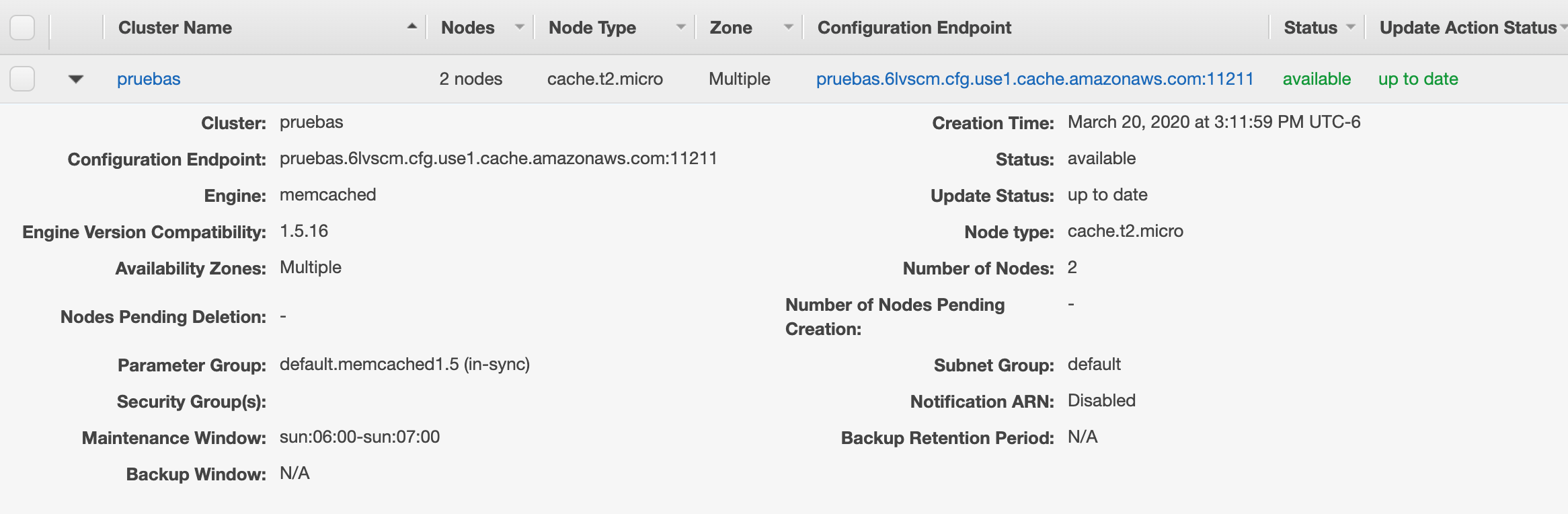
Algo importante que deben saber, es que pueden usar cualquier cliente en Java para memcached. Pero si desean hacer uso de la función de autodescubrimiento de nodos en el cluster, deben descargar la versión de Java que esta disponible en esa misma pantalla.
¿Qué es autodescubrimiento?
Esto quiere decir que si en el transcurso del tiempo necesitan agregar nuevos nodos al cluster o dar de baja algunos, no tienen que ir a editar una lista estática de endpoints para cada nodo en nuestro código.
Dicho esto, vamos a crear un EJB Stateless para gestionar nuestro cache.
@Stateless
public class CacheService implements Serializable {
private static final Logger LOG = Logger.getLogger(CacheService.class.getName());
private MemcachedClient memCachedClient = null;
public CacheService() {
}
@PostConstruct
public void init() {
try {
memCachedClient = new MemcachedClient(
new BinaryConnectionFactory(ClientMode.Dynamic),
AddrUtil.getAddresses("pruebas.6lvscm.cfg.use1.cache.amazonaws.com:11211"));
} catch (Exception ex) {
LOG.log(Level.SEVERE, "Error al conectar a memcached", ex);
}
}
...
}
Observen que indicamos el ClientMode.Dynamic y la dirección de nuestro endpoint.
Ahora, para guardar un elemento en el cache crearemos un método en nuestro EJB que recibe una llave y el objeto a almacenar.
@TransactionAttribute(TransactionAttributeType.SUPPORTS)
public void guardar(String key, MiObjeto bean) {
try {
// Expira en 1 hora (60 * 60)
memCachedClient.set(clave, 3600, bean);
} catch (Exception ex) {
LOG.log(Level.SEVERE, "Error al guardar en cache ", ex);
}
}
En este ejemplo, indicamos que la vigencia de ese objeto en el cache es de 1 hora. Dependiendo de cada caso puede ser más o menos tiempo.
Y para recuperar un objeto hacemos lo siguiente:
@TransactionAttribute(TransactionAttributeType.SUPPORTS)
public MiObjeto recuperar(String key) {
// Tratamos de obtener el valor por a lo más 500 ms,
// caso contrario abortamos
MiObjeto myObj = null;
Future<Object> f = memCachedClient.asyncGet(key);
try {
myObj = (MiObjeto) f.get(500, TimeUnit.MILLISECONDS);
// puede arrojar InterruptedException, ExecutionException
// o TimeoutException
} catch (Exception e) {
// Cancelamos el procesamiento
LOG.log(Level.SEVERE, "Dio timeout al traer " + clave);
f.cancel(true);
myObj = null;
}
return myObj;
}
Para buscar nuestro objeto en el cache observaran que usamos un Future y una llamada asincrónica al cache. Si no obtenemos una respuesta en menos de 500 ms cancelamos el proceso y retornamos. Si la llave que buscamos no está en el cache, este nos regresa un null.
Y eso sería todo lo que necesitamos para integrarnos con un ElastiCache, desde la consola podríamos agregar nuevos nodos al cluster o retirarlos y nuestro cliente de memcached dinámicamente se ajustaría sin depender de ajustes de nuestra parte.
Conclusión
La integración con ElastiCache es un proceso muy sencillo y al ser un servicio administrado nos permite concentranos en la necesidad de nuestra aplicación de una manera más eficiente.



Inicia la conversación