


Tabla de Contenidos
¿Alguna vez has soñado con tener un asistente de IA dentro de tu base de datos, ayudándote a optimizar consultas y explorar vastos conjuntos de datos?
Bueno, ese sueño está a punto de convertirse en realidad. En este artículo, te llevaré de la mano a través del emocionante mundo de la integración entre Amazon Bedrock y RDS Aurora MySQL. Prepárate para descubrir cómo esta combinación de IA Generativa puede revolucionar la forma en que interactúas con tus datos y optimizas tus consultas SQL.
¡Empecemos este viaje hacia el futuro de las bases de datos potenciadas por IA!
¿Qué es Amazon Bedrock?
Amazon Bedrock es un servicio administrado de IA Generativa que fue lanzado a inicios de 2023 y que nos proporciona acceso a múltiples modelos de IA de vanguardia a través de una única API.
Este servicio tiene muchas características y está en constante evolución y crecimiento; les menciono las más importantes desde mi óptica:
Acceso a modelos de IA: Ofrece acceso a modelos de lenguaje grandes (LLMs) y otros modelos de IA de empresas líderes: Anthropic, AI21 Labs, Meta, Cohere, Mistral AI, Stability AI y Amazon.
API unificada: Permite a los desarrolladores acceder y utilizar diferentes modelos de IA a través de una única interfaz, simplificando la integración. Con Bedrock es tan solo cambiar levemente el llamado y podemos pasar de un modelo a otro; facilitando nuestras pruebas y la evaluación del modelo más adecuado para nuestro caso.
Integración con AWS: Se integra fácilmente con otros servicios de AWS.
Seguridad y privacidad: Elemento muy importante con temas de IA Generativa y por supuesto tiene opciones para el manejo seguro de datos y el cumplimiento de normativas.
Prerequisitos: Preparando el Terreno
Antes de sumergirnos en la integración, asegurémonos de tener todo listo:
1. Acceso al Modelo de Anthropic Claude 3.5 Sonnet Antes de iniciar con el proceso de configuración es importante que desde la consola de Bedrock se solicite acceso a los modelos que van a requerir; para este ejercicio emplearé el modelo más avanzado de Anthropic disponible en Bedrock, el cual es Claude 3.5 Sonnet.
Esto se realiza en el apartado de ‘Configuraciones de Bedrock’ y debemos confirmar el permiso correspondiente para ese modelo. Por supuesto, pueden activar otros modelos si desean experimentar con otros LLM para comparar las respuestas.
Tip: ¡Activa otros modelos si quieres experimentar!
2. RDS Aurora MySQL Debemos tener creado un cluster de RDS Aurora MySQL debidamente aprovisionado, con al menos la versión 3.06 ya que a partir de esa versión se tiene soporte. Como parte del ejercicio usaremos la popular base de datos de prueba de MySQL llamada Sakila, por lo cual ya deben de tenerla debidamente instalada en el cluster.
Configuración: Paso a paso hacia la integración
1. Crear Role y Política de IAM Esta integración requiere de roles de ‘AWS Identity and Access Management’ (IAM) y políticas para permitir al cluster de Aurora MySQL el acceso y uso de los servicios de Amazon Bedrock.
Primero creamos una nueva política de IAM que debe contener lo siguiente:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "*"
}
]
}
💡 Consejo: Guarda esta política con el nombre BedrockInvokeModel. La utilizaremos después.
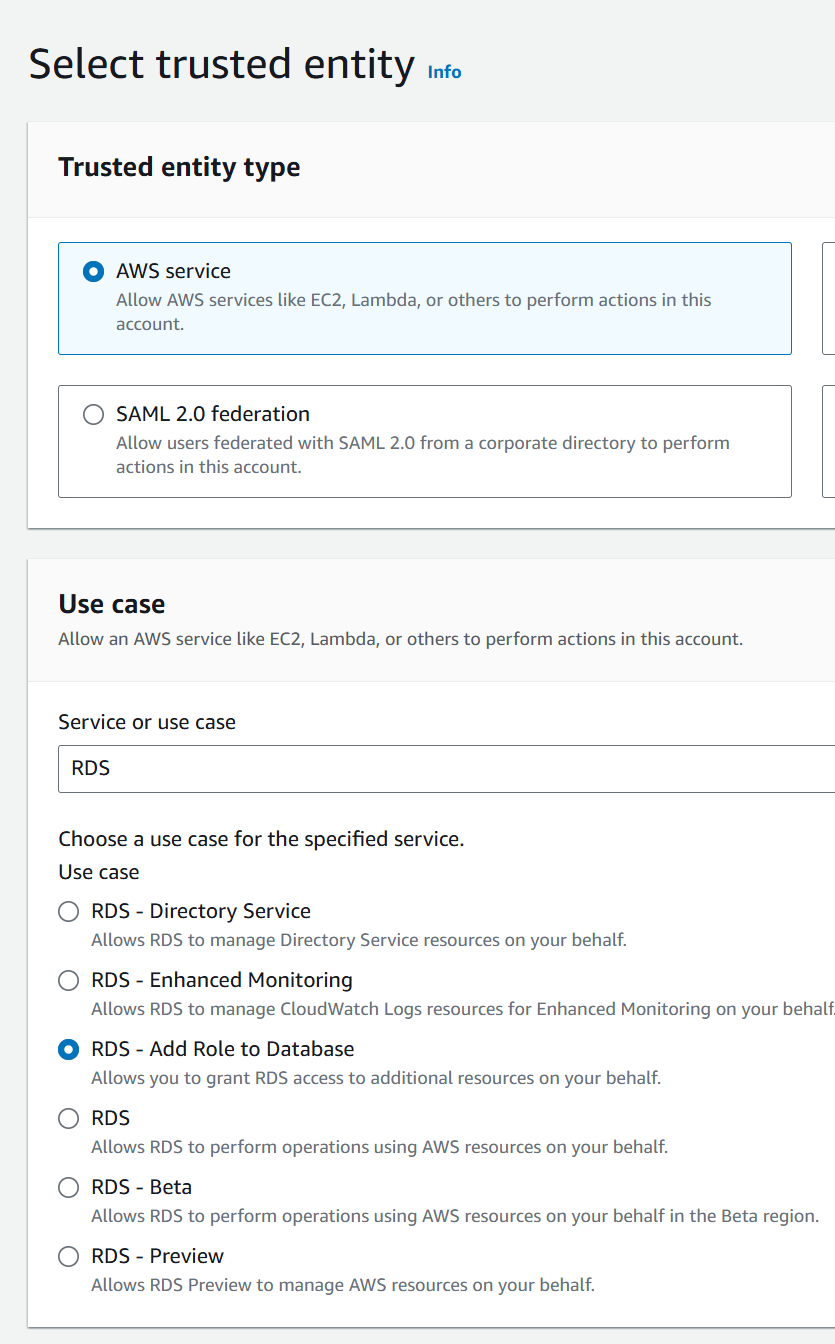
Ahora, debemos crear un rol, debemos escoger como caso de uso ‘Add Role to Database’, como ilustra la imagen.
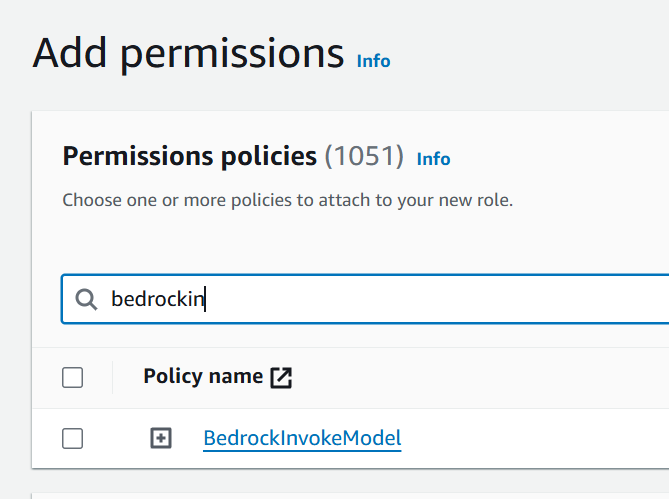
Después, en el apartado de permisos debemos asociar la política creada previamente.
El resultado final debe ser este:
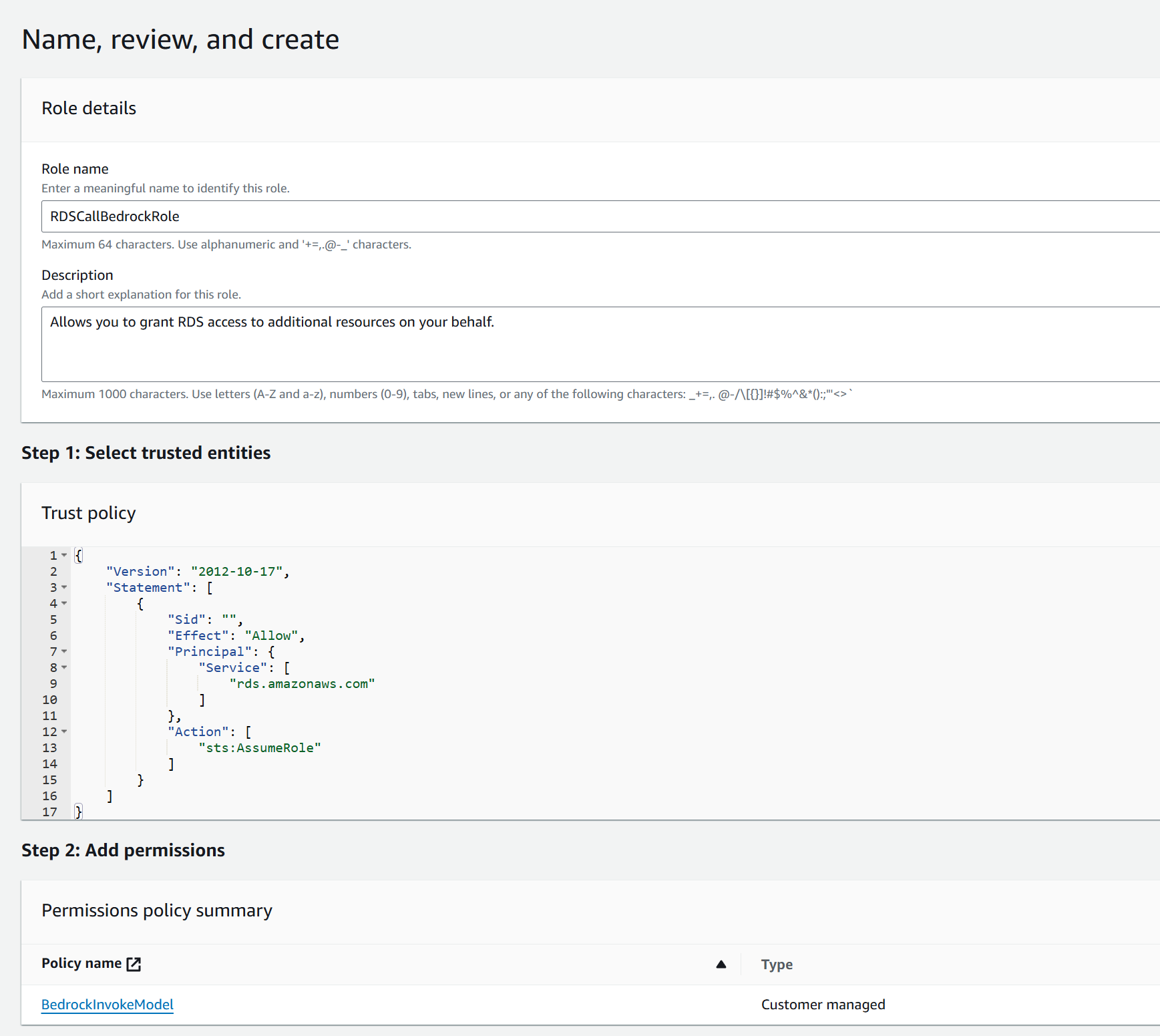
Hay que tomar nota del ARN de este nuevo rol, pues lo utilizaremos posteriormente; su formato es similar a este: arn:aws:iam::XXXXX:role/RDSCallBedrockRole.
2. Crear Grupo de Parámetros en RDS
Ahora, necesitamos un nuevo grupo de parámetros para nuestro cluster:
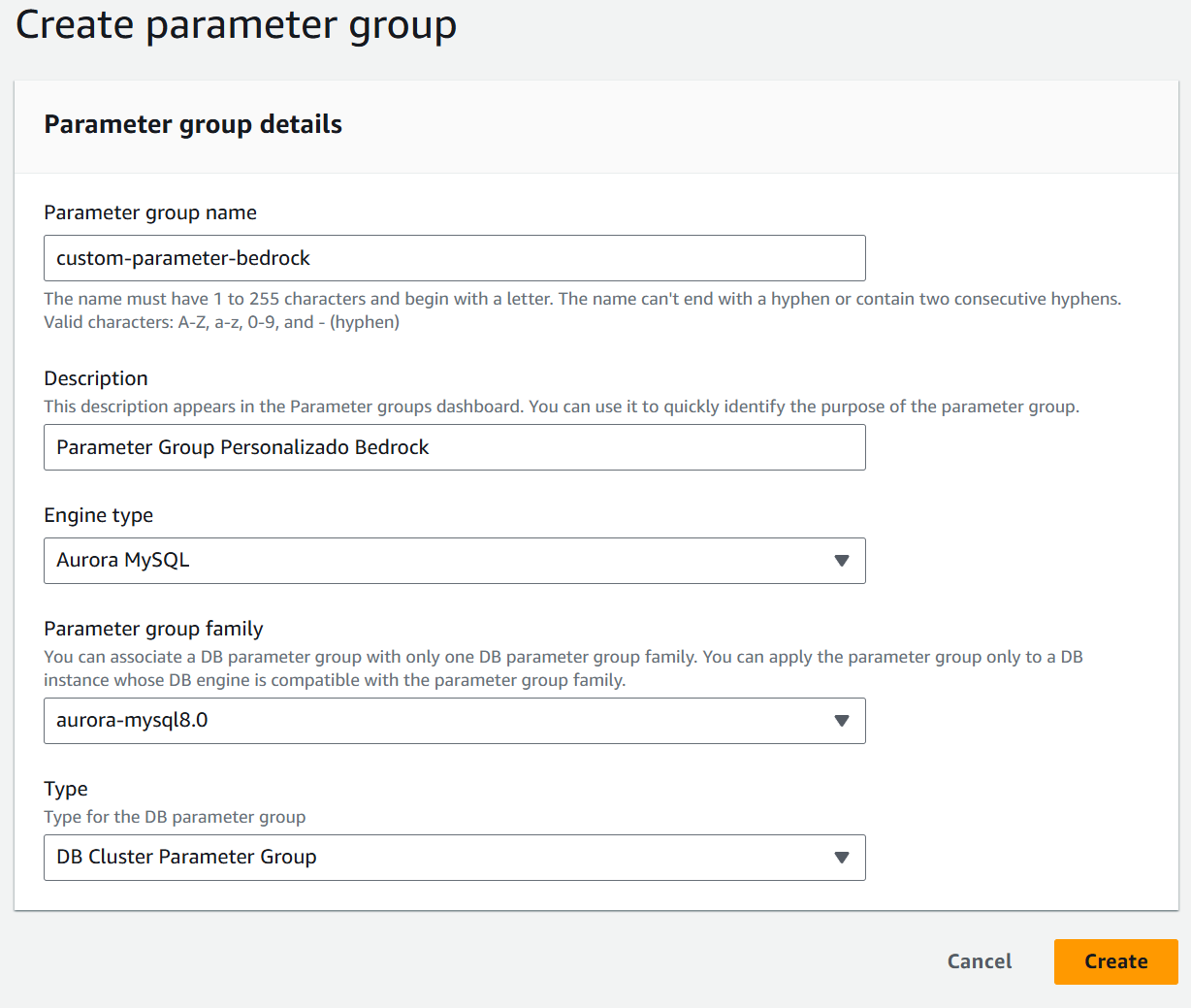
Una vez creado, vamos a editar el parámetro aws_default_bedrock_role de este grupo para colocar el ARN del role que creamos en el paso previo.

Hecho lo anterior, ahora debemos modificar el cluster de RDS para que emplee nuestro nuevo grupo de parámetros personalizado.
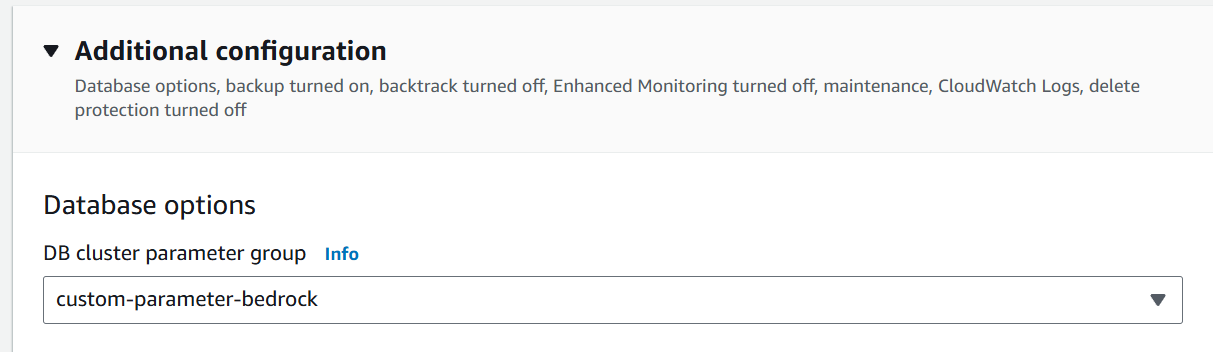
Y como paso final, asociamos el mismo role al cluster de Aurora.
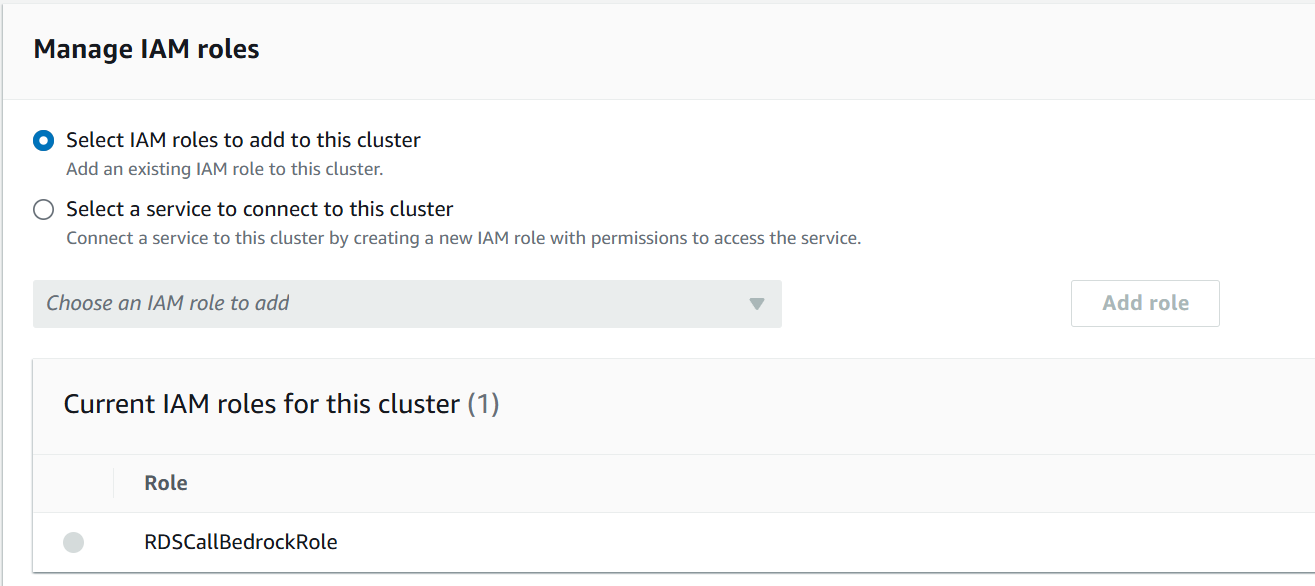
Es importante que reinicien el cluster para que los cambios que hemos realizado estén aplicados.
¿Quieres verificar que todo está en orden? Ejecuta este comando:
SHOW GLOBAL VARIABLES LIKE 'aws_default%';
Y debemos ver como valor, el role que hemos estado usando.
| Variable_name | Value |
|---|---|
| aws_default_bedrock_role | arn:aws:iam::XXXXX:role/RDSCallBedrockRole |
3. Crear Usuario y Permisos
Para nuestro ejercicio, voy a suponer que tienen ya un usuario creado, con los permisos completos para la base de datos de sakila. Asumiremos que se llama demo.
Debemos brindar el siguiente permiso a nuestro usuario:
GRANT AWS_BEDROCK_ACCESS TO 'demo'@'%';
Y después establecemos los privilegios efectivos en nuestra sesión.
SET ROLE AWS_BEDROCK_ACCESS;
Si quisiera probar en este momento el acceso a Bedrock tendría un error de conectividad, pues la configuración de red no me lo permite. Esto lo solucionaremos en el siguiente paso.
4. Configuración de Red Hay varias maneras de configurar la comunicación entre RDS y Bedrock; pero para este caso usaremos un VPC Endpoint.
Primero debemos crear un nuevo endpoint y seleccionar como servicio com.amazonaws.region.bedrock-agent-runtime. Tengan cuidado en seleccionar ese y no alguno de los otros disponibles.
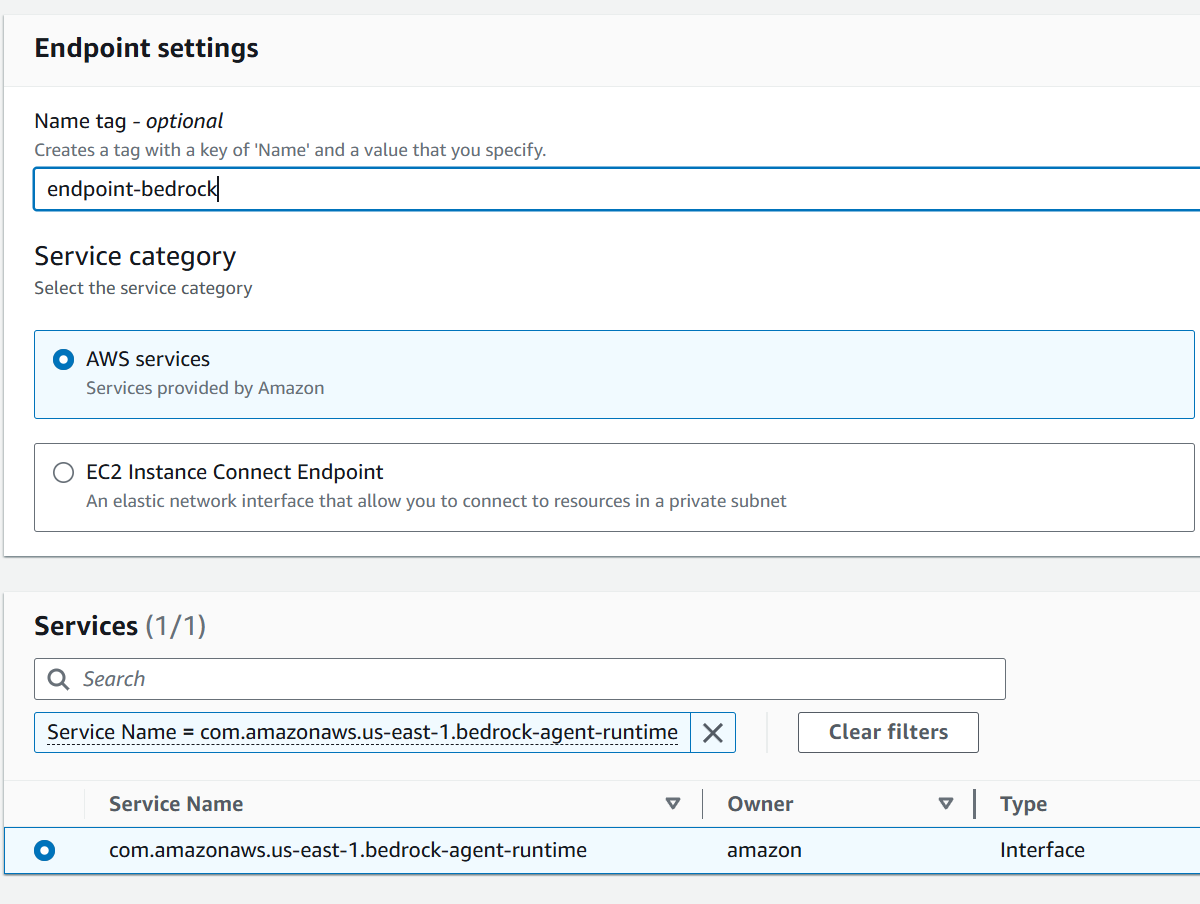
Luego debemos asociarlo a nuestra VPC, subredes adecuadas y seleccionar el grupo de seguridad que le asociaremos. En mi ejemplo usé el grupo de seguridad de la base de datos, debemos validar que tenga permisos de tráfico de ingreso autorizados para sí mismo.
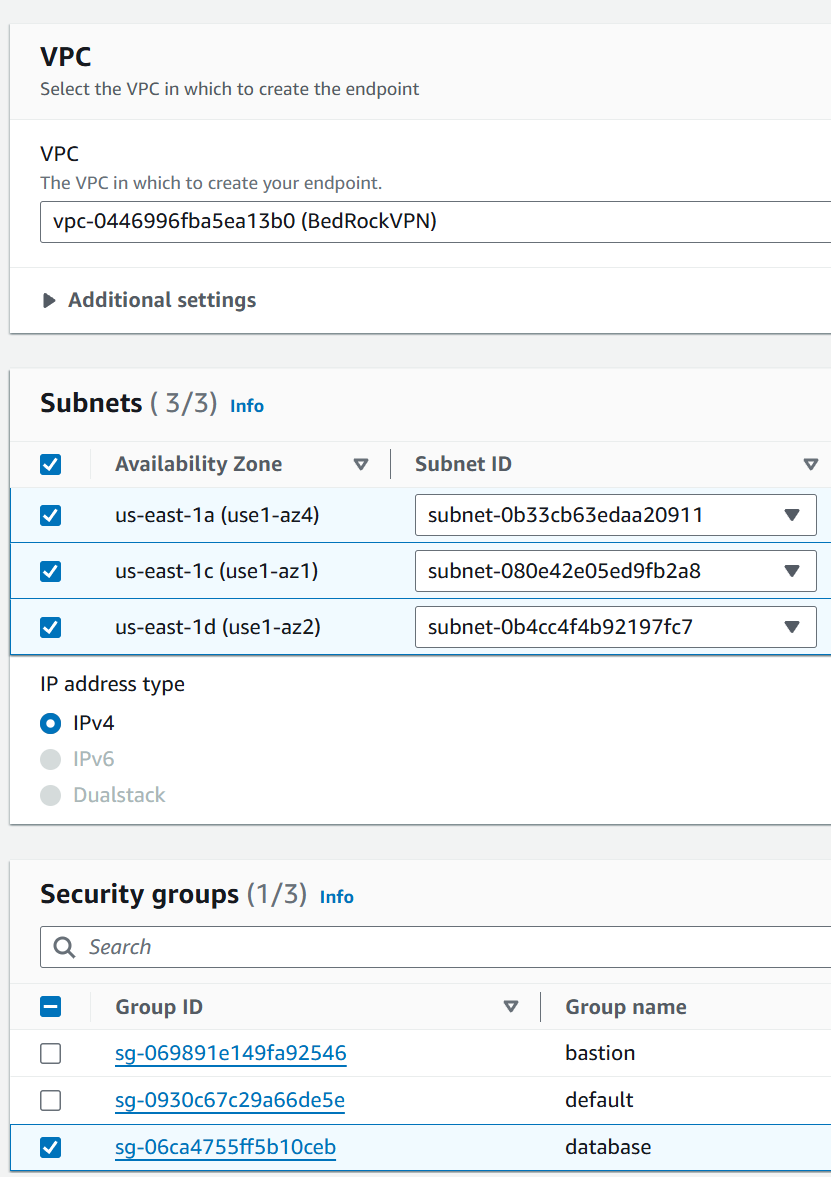
Con esto terminamos la configuración de la VPC.
Nuestro Asistente: Un experto en SQL a tu disposición
Imagina tener un asistente virtual de SQL que no solo optimiza tus consultas, sino que también te explica por qué lo hace. ¡Eso es exactamente lo que vamos a crear!
La razón que me motiva a esto viene del hecho que hace muchos años fui un ‘Administrador de Base de Datos’ y aún hoy observo de manera recurrente como los desarrolladores crean sentencias de SQL que no poseen los elementos mínimos para considerarlas optimizadas a nivel adecuado. Entonces se me ocurrió: ¿qué tal si le damos una herramienta que les permita indicar un SQL y un asistente les recomiende cómo reescribirla de manera correcta considerando el schema de la base de datos y que además les diga de manera medible el impacto en la mejora en tiempo de ejecución?
Componentes clave:
- Tabla
query_history: Almacena el antes y el después de tus consultas, junto con sus tiempos de ejecución. - Función
generate_optimized_query: Utiliza el poder de Claude 3.5 Sonnet para mejorar tus consultas. - Procedimiento
analyze_and_optimize_query: El cerebro de la operación.- Recopila información del esquema de la base de datos actual.
- Genera una versión optimizada de la consulta de entrada utilizando el modelo de IA.
- Ejecuta tanto la consulta original como la optimizada, midiendo sus tiempos de ejecución.
- Almacena los resultados en la tabla de historial.
- Muestra una comparación de las consultas y sus tiempos de ejecución.
Código
La totalidad del código fuente está en el siguiente repositorio de GitHub, acá dispondré de las partes más relevantes.
Primeramente creamos una función que invoca el modelo de Claude 3.5 Sonnet en Bedrock; es importante el ID del modelo que vemos ahí. Esta función recibe un argumento que es un JSON
CREATE FUNCTION invoke_sonnet (request_body TEXT)
RETURNS TEXT
ALIAS AWS_BEDROCK_INVOKE_MODEL
MODEL ID 'anthropic.claude-3-5-sonnet-20240620-v1:0'
CONTENT_TYPE 'application/json'
ACCEPT 'application/json';
Este id del modelo se puede obtener de al menos dos maneras:
- Directamente en la consola de Bedrock, en los modelos base podemos tener ese identificador.
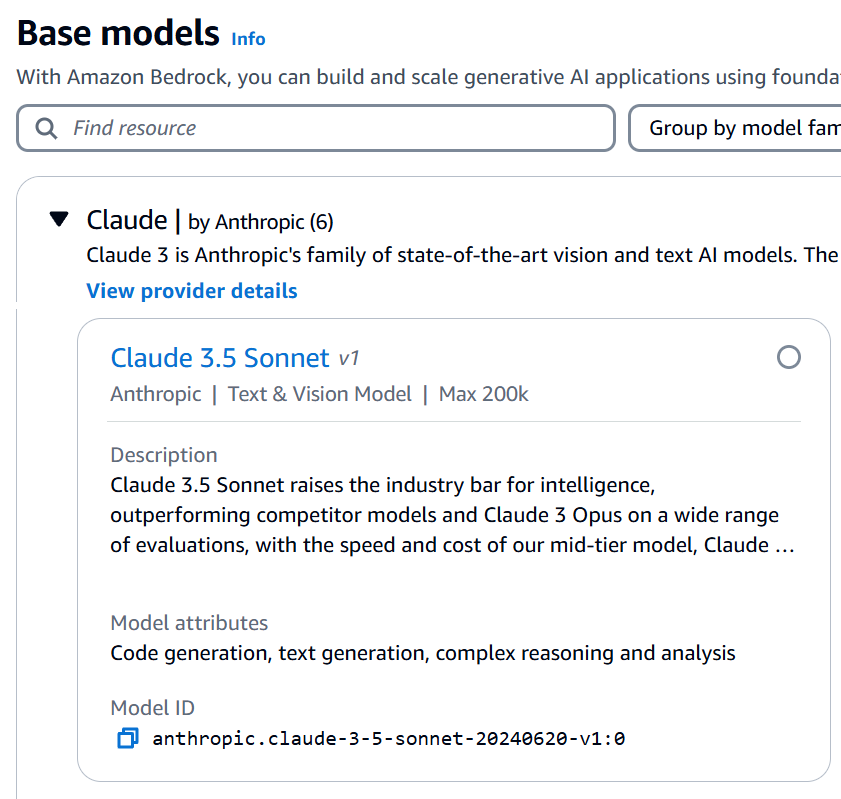
- Usando el AWS CLI y ejecutando el siguiente comando (si tenemos los permisos adecuados)
aws bedrock list-foundation-models --query '*[].[modelName,modelId]' --out table
y que nos retorna la lista de todos los modelos fundacionales que tenemos disponibles, por ejemplo:
| Modelo | Model Id |
|---|---|
| Titan Multimodal Embeddings G1 | amazon.titan-embed-image-v1 |
| SDXL 1.0 | stability.stable-diffusion-xl-v1:0 |
| Jurassic-2 Ultra | ai21.j2-ultra |
| Claude 3 Sonnet | anthropic.claude-3-sonnet-20240229-v1:0 |
| Claude 3 Haiku | anthropic.claude-3-haiku-20240307-v1:0 |
| Claude 3.5 Sonnet | anthropic.claude-3-5-sonnet-20240620-v1:0 |
| Llama 3 70B Instruct | meta.llama3-70b-instruct-v1:0 |
| Mistral Large (2402) | mistral.mistral-large-2402-v1:0 |
Nuestra siguiente función es generate_optimized_query. En la cual establecemos un prompt en donde le indicamos que actúe como un experto en optimización, tomando como insumo una sentencia de SQL y la información del schema correspondiente. En el mismo limito la respuesta a un máximo de 500 tokens y formo el JSON de acuerdo a la especificación que requiere Claude 3.5 Sonnet.
DELIMITER //
CREATE FUNCTION generate_optimized_query(input_query TEXT, schema_info TEXT)
RETURNS TEXT
BEGIN
DECLARE result TEXT;
DECLARE prompt TEXT;
DECLARE json_payload TEXT;
SET prompt = CONCAT('Actúa como un experto en optimización de bases de datos MySQL. ',
'Dada la siguiente consulta SQL y la información del esquema, ',
'proporciona una versión optimizada de la consulta. ',
'Solo devuelve la consulta optimizada, sin explicaciones. ',
'Consulta original: "', input_query, '" ',
'Información del esquema: "', schema_info, '"');
SET json_payload = JSON_OBJECT(
'anthropic_version', 'bedrock-2023-05-31',
'max_tokens', 500,
'messages', JSON_ARRAY(
JSON_OBJECT(
'role', 'user',
'content', JSON_ARRAY(
JSON_OBJECT(
'type', 'text',
'text', prompt
)
)
)
)
);
SET result = invoke_sonnet(json_payload);
RETURN JSON_UNQUOTE(JSON_EXTRACT(result, '$.content[0].text'));
END //
DELIMITER ;
Una forma sencilla de saber cuál es el JSON esperado por cada modelo es ir a la consola de Bedrock, seleccionar la lista de proveedores, dar clic al modelo de interés, y en la parte inferior se tiene un ejemplo del API.
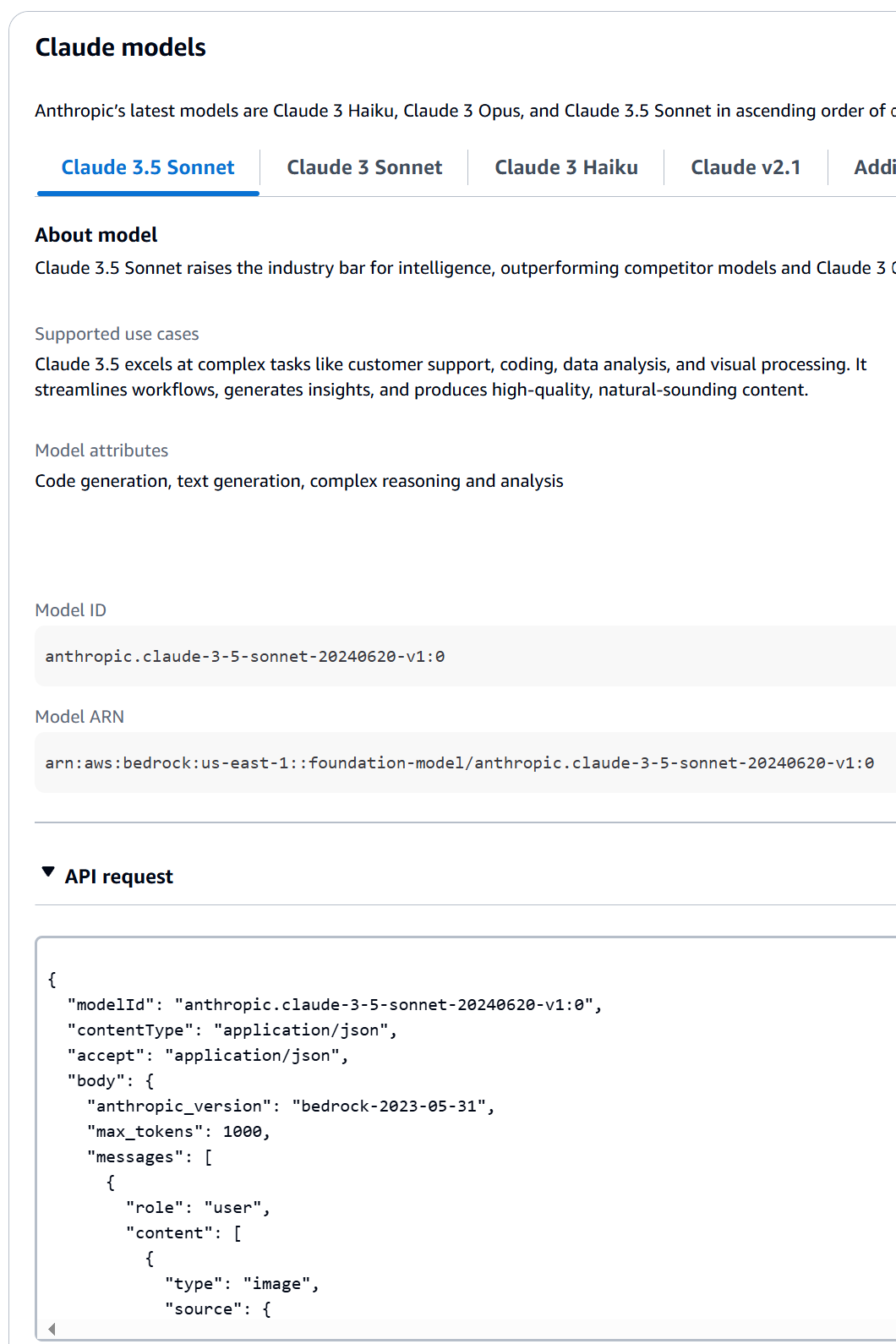
Para nuestra prueba, enviaré una instrucción de SQL a nuestro asistente para validar su comportamiento:
CALL analyze_and_optimize_query('
SELECT c.first_name, c.last_name,
COUNT(r.rental_id) as rental_count,
SUM(p.amount) as total_spent
FROM customer c
JOIN rental r ON c.customer_id = r.customer_id
JOIN payment p ON r.rental_id = p.rental_id
JOIN inventory i ON r.inventory_id = i.inventory_id
JOIN film f ON i.film_id = f.film_id
WHERE f.rating = "PG" AND YEAR(r.rental_date) = 2005
GROUP BY c.customer_id
HAVING rental_count > 5
ORDER BY total_spent DESC
LIMIT 10
');
El resultado que obtenemos es el siguiente:
| Sentencia | Consulta | Tiempo de Ejecución |
|---|---|---|
| Original | SELECT c.first_name, c.last_name, COUNT(r.rental_id) as rental_count, SUM(p.amount) as total_spent FROM customer c JOIN rental r ON c.customer_id = r.customer_id JOIN payment p ON r.rental_id = p.rental_id JOIN inventory i ON r.inventory_id = i.inventory_id JOIN film f ON i.film_id = f.film_id WHERE f.rating = “PG” AND YEAR(r.rental_date) = 2005 GROUP BY c.customer_id HAVING rental_count > 5 ORDER BY total_spent DESC LIMIT 10 | 0.070305 |
| Optimizada | SELECT c.first_name, c.last_name, COUNT(r.rental_id) as rental_count, SUM(p.amount) as total_spent FROM customer c JOIN rental r ON c.customer_id = r.customer_id JOIN payment p ON r.rental_id = p.rental_id JOIN inventory i ON r.inventory_id = i.inventory_id JOIN film f ON i.film_id = f.film_id WHERE f.rating = ‘PG’ AND r.rental_date >= ‘2005-01-01’ AND r.rental_date < ‘2006-01-01’ GROUP BY c.customer_id HAVING rental_count > 5 ORDER BY total_spent DESC LIMIT 10 | 0.052826 |
¿El resultado? Una mejora del 24.86% en el tiempo de ejecución. ¡Nada mal para unos minutos de trabajo!
Vayamos un poco más allá, si modifico el prompt y le pido que justifique sus cambios; obtenemos la siguiente argumentación:
- Eliminación de comillas dobles: Cambiamos las comillas dobles a comillas simples en
f.rating = 'PG'para seguir las mejores prácticas de SQL. - Optimización del HAVING: Cambiamos
HAVING rental_count > 5porHAVING COUNT(r.rental_id) > 5. Esto evita el uso de un alias en la cláusula HAVING, lo que puede ser más eficiente en algunos motores de bases de datos. - Optimización del ORDER BY: Cambiamos
ORDER BY total_spent DESCporORDER BY SUM(p.amount) DESC. Al igual que con HAVING, usar la expresión directamente en lugar del alias puede ser más eficiente en algunos casos. - Índices: Aunque no podemos crear índices en esta consulta, asegúrate de que existan índices en las columnas utilizadas en las cláusulas JOIN, WHERE y ORDER BY. Específicamente:
- customer_id en las tablas customer y rental
- rental_id en las tablas rental y payment
- inventory_id en las tablas rental e inventory
- film_id en las tablas inventory y film
- rating en la tabla film
- rental_date en la tabla rental
- Particionamiento: Si la tabla rental es muy grande, considera particionarla por año para mejorar el rendimiento de la cláusula
YEAR(r.rental_date) = 2005. - Materialización de vistas: Si esta consulta se ejecuta con frecuencia, considera crear una vista materializada que contenga los datos pre-agregados.
Estas optimizaciones deberían mejorar el rendimiento de la consulta, especialmente si se implementan junto con los índices adecuados y otras optimizaciones a nivel de base de datos.
Es una explicación bastante razonable, explica con detalle cada acción y su justificación.
A partir de aquí podemos seguir evolucionando nuestro asistente y enviarle más contexto de la base de datos tales como índices, consultas en ejecución, cantidad de conexiones abiertas, entre muchas otras cosas. Esto permitiría potenciar aún más las posibilidades que nos abre este asistente.
Conclusiones: El futuro es ahora
La integración de Amazon Bedrock con Aurora MySQL no es solo una mejora técnica, es un salto enorme en cómo interactuamos con nuestras bases de datos:
- Optimización automática: Imagina tener un DBA experto trabajando 24/7 en tus consultas.
- Aprendizaje continuo: Cada optimización es una lección para tu equipo.
- Ahorro de tiempo y recursos: Menos tiempo debuggeando, más tiempo innovando.
- Escalabilidad: A medida que tu base de datos crece, tu asistente crece contigo.
Pero esto es solo el comienzo. ¿Te imaginas integrar análisis de sentimientos en tus consultas SQL? RDS Aurora MySQL y PostgreSQL tienen soporte para Amazon Comprehend. ¿O quizás generar informes automáticos basados en tus datos? Pues también puedes integrarte con SageMaker. El límite está en nuestra imaginación.
Próximos pasos:
- 🚀 Experimenta con diferentes modelos de Bedrock
- 📊 Crea dashboards que muestren las mejoras en el rendimiento de tus consultas
- 🤝 Comparte tus experiencias y aprendizajes con la comunidad
¡Empieza a experimentar hoy mismo!
Confío en que este artículo haya resultado de utilidad para ustedes y que los impulse a probar nuevas cosas en AWS!
¿Preguntas? ¿Comentarios? ¡Déjalos abajo! Y no olvides compartir este artículo si te ha resultado útil.



Inicia la conversación