

Tabla de Contenidos
La Curiosidad Como Motor de Exploración 🎯
La llegada del Intelligent Prompt Routing a Amazon Bedrock despertó mi curiosidad técnica. ¿Cómo decide realmente qué modelo usar? ¿Qué tan efectivas son estas decisiones? Sin un caso de uso específico en mente, decidí sumergirme en una exploración práctica desde la consola de AWS para entender sus capacidades y limitaciones.
¿Qué es Intelligent Prompt Routing?
Amazon Bedrock Intelligent Prompt Routing es una característica que proporciona un endpoint serverless único para enrutar eficientemente las solicitudes entre diferentes modelos fundacionales dentro de la misma familia. El router predice el rendimiento de cada modelo para cada solicitud y dirige dinámicamente cada consulta al modelo que probablemente dará la respuesta deseada al menor costo.
Durante la fase de preview, esta característica está disponible para:
- Familia Anthropic (Claude 3.5 Sonnet y Claude 3 Haiku)
- Familia Meta Llama (70B y 8B)
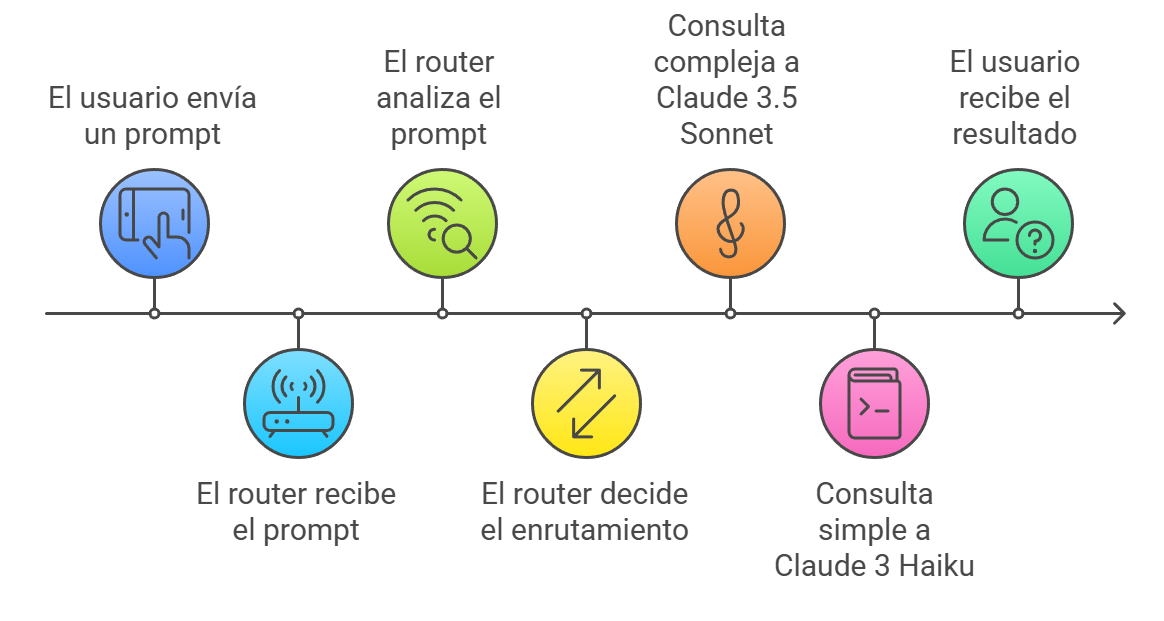 Figura 1: Diagrama mostrando el flujo de decisión del Intelligent Prompt Routing. El router analiza cada solicitud y la dirige al modelo más apropiado basado en su predicción de rendimiento y costo.
Figura 1: Diagrama mostrando el flujo de decisión del Intelligent Prompt Routing. El router analiza cada solicitud y la dirige al modelo más apropiado basado en su predicción de rendimiento y costo.
Preparando el Terreno: Configuración Inicial
Lo primero es acceder a la consola de AWS y navegar hasta Bedrock. Durante esta exploración, trabajaremos en la región US East (N. Virginia), donde tenemos acceso a los modelos necesarios.
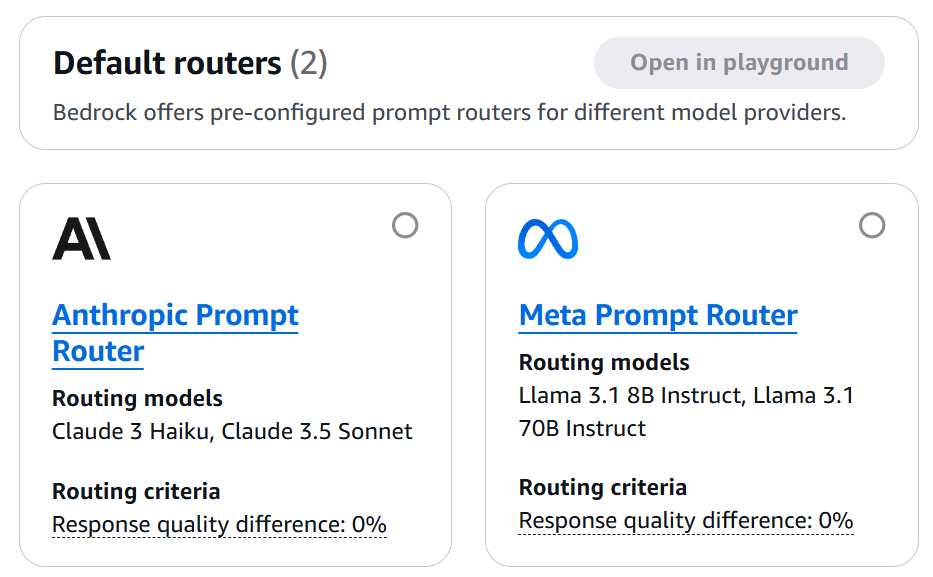 Figura 2: Panel principal de Amazon Bedrock mostrando la sección de Prompt Routers. Aquí es donde comenzamos nuestra exploración.
Figura 2: Panel principal de Amazon Bedrock mostrando la sección de Prompt Routers. Aquí es donde comenzamos nuestra exploración.
Accediendo al Prompt Router
- En el panel izquierdo, selecciona “Prompt routers”
- Localiza el “Anthropic Prompt Router”
- Observa los modelos disponibles:
- Claude 3.5 Sonnet
- Claude 3 Haiku
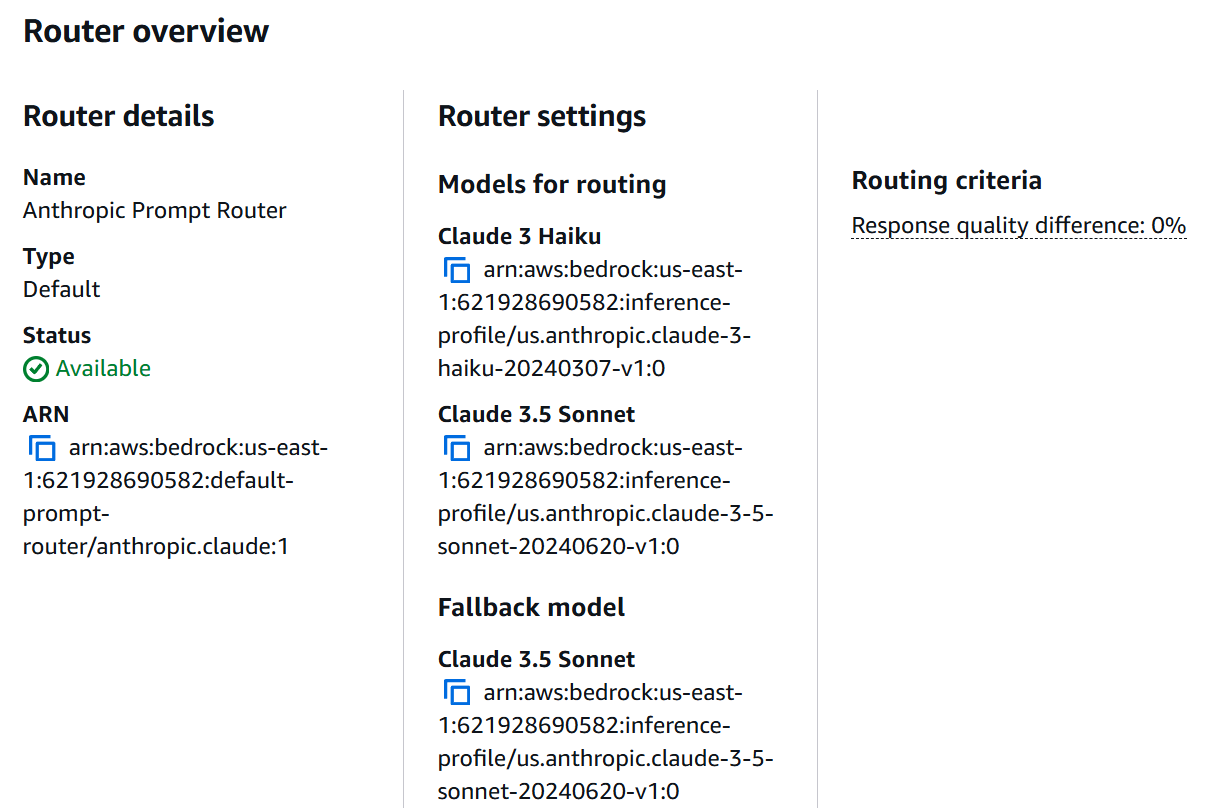 Figura 3: Configuración del Anthropic Prompt Router mostrando los modelos disponibles y sus configuraciones.
Figura 3: Configuración del Anthropic Prompt Router mostrando los modelos disponibles y sus configuraciones.
Manos a la Obra: Pruebas Prácticas
Para entender realmente cómo funciona el routing, diseñé un conjunto de pruebas que cualquiera puede replicar fácilmente desde la consola:
Escenario 1: Consultas de AWS Básicas
Empecemos con preguntas simples sobre AWS:
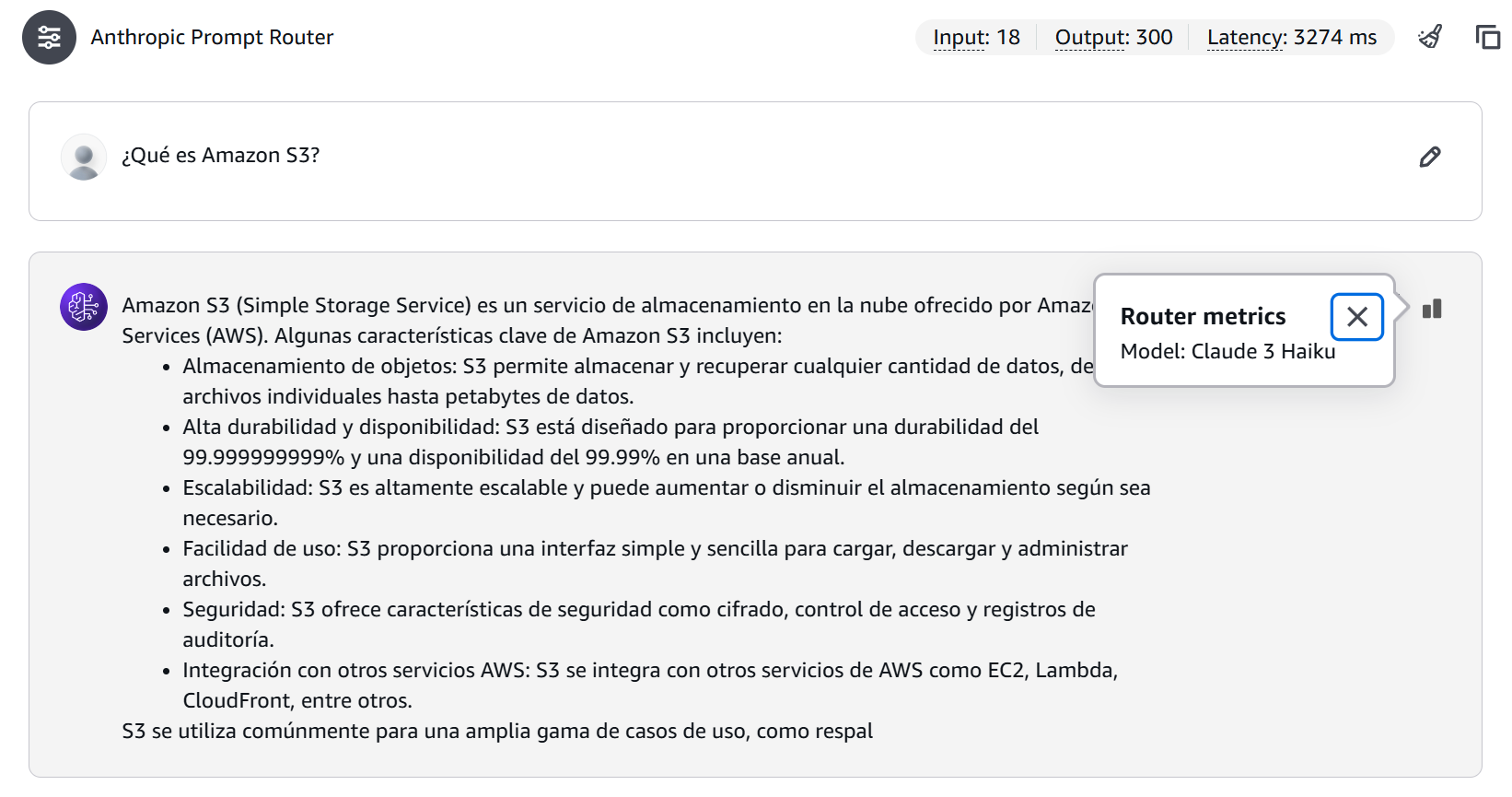 Figura 4: Resultado de una consulta simple mostrando la selección de Claude Haiku y el consumo de tokens.
Figura 4: Resultado de una consulta simple mostrando la selección de Claude Haiku y el consumo de tokens.
En este caso el modelo seleccionado ha sido Claude 3 Haiku, con un total de 18 tokens de entrada, 300 de salida y una latencia de 3274 ms.
Escenario 2: Análisis Arquitectónico
Ahora, probemos algo más complejo:
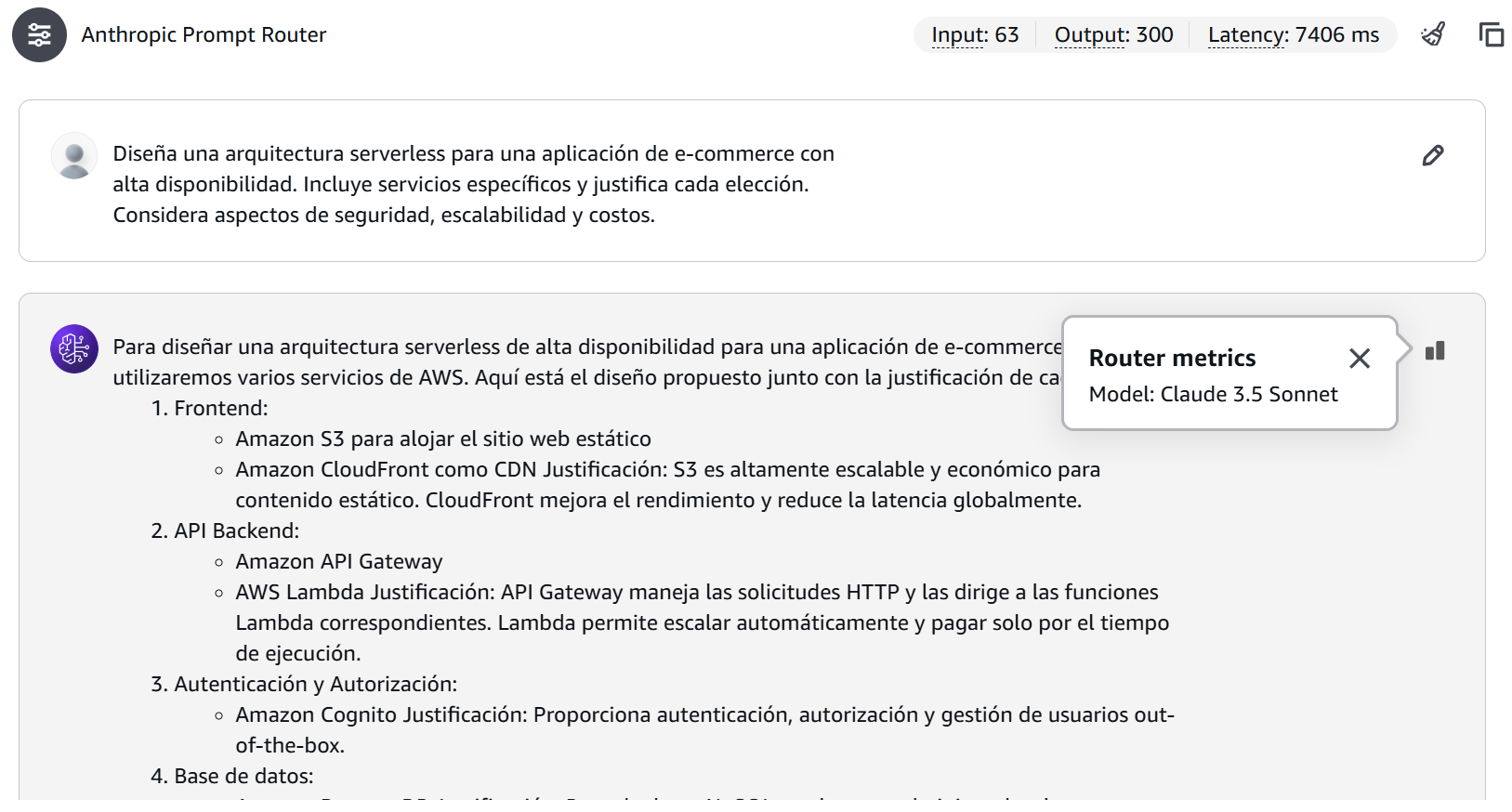 Figura 5: Resultado de una consulta compleja mostrando la selección de Claude Sonnet y un mayor consumo de tokens.
Figura 5: Resultado de una consulta compleja mostrando la selección de Claude Sonnet y un mayor consumo de tokens.
En este otro escenario, el modelo seleccionado ha sido Claude Sonnet 3.5, con un total de 63 tokens de entrada, 300 de salida y una latencia de 7406 ms.
Observaciones y Patrones
Durante las pruebas, emergieron patrones claros sobre cuándo el router elige cada modelo:
Claude Haiku tiende a ser seleccionado cuando:
- Preguntas directas y definiciones
- Consultas sobre servicios específicos
- Respuestas que requieren menos tokens de salida
Claude Sonnet tiende a ser elegido en:
- Diseños arquitectónicos complejos
- Análisis detallados
- Respuestas que requieren más tokens de salida
Análisis de Costos y Rendimiento
Un aspecto crucial al evaluar el Intelligent Prompt Router es entender su impacto en los costos. Analicemos el caso de la consulta sencilla comparando Haiku con Sonnet.
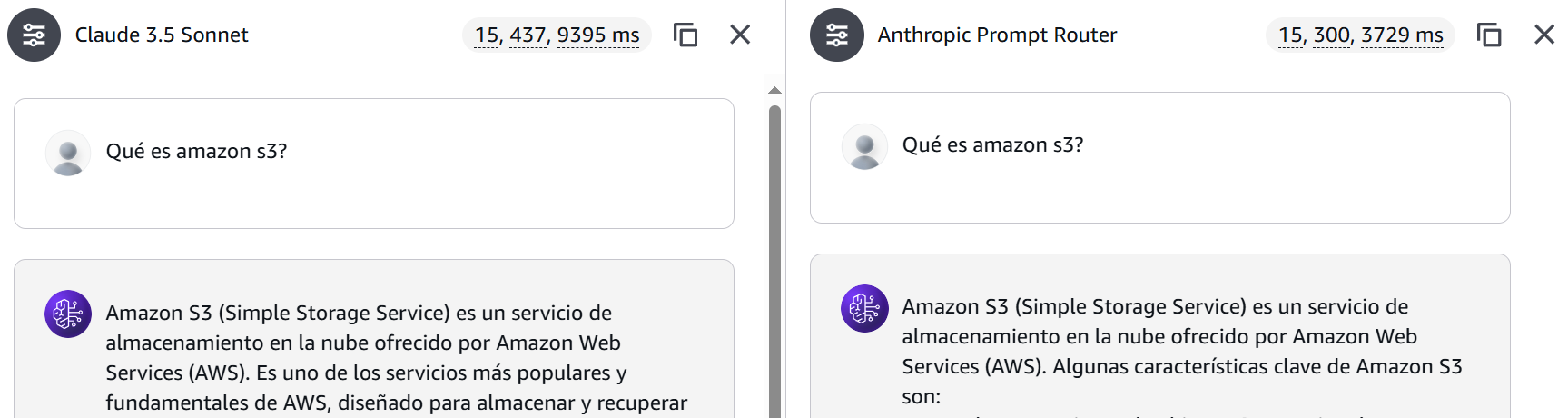 Figura 6: Comparativa de consultas sencillas.
Figura 6: Comparativa de consultas sencillas.
Escenario 1: Consulta Simple (Claude 3 Haiku)
- Tokens de entrada: 15
- Tokens de salida: 300
- Latencia: 3,729 ms
Cálculo de costos:
- Costo por entrada: 15 * ($0.00025/1000) = $0.00000375
- Costo por salida: 300 * ($0.00125/1000) = $0.000375
- Costo total: $0.00037875
Escenario 2: Consulta Simple (Claude 3.5 Sonnet)
- Tokens de entrada: 15
- Tokens de salida: 437
- Latencia: 9,395 ms
Cálculo de costos:
- Costo por entrada: 15 * ($0.003/1000) = $0.000045
- Costo por salida: 437 * ($0.015/1000) = $0.006555
- Costo total: $0.0066
Comparativa de Eficiencia
| Claude 3 Haiku | Claude 3.5 Sonnet | |
|---|---|---|
| Costo Total | $0.00037875 | $0.0066 |
| Latencia | 3,729 ms | 9,395 ms |
| Tokens Procesados | 315 | 452 |
🔍 ProTip: El router parece priorizar Haiku para consultas simples, lo cual es costo-efectivo considerando que es aproximadamente 17.4 veces más económico que Sonnet para este tipo de interacciones.
Implicaciones para Producción
- Optimización de Costos
- Las consultas simples procesadas por Haiku representan un ahorro significativo
- El costo por consulta con Sonnet se justifica para análisis complejos
- Balance Rendimiento-Costo
- Haiku ofrece mejor rendimiento (≈5 segundos más rápido) y menor costo
- La selección de Sonnet por el router se justifica por necesidades de análisis complejo, no por consideraciones de velocidad
- Consideraciones de Escalabilidad
- A escala, la diferencia de costos puede ser sustancial
- Por ejemplo, para 1 millón de consultas simples:
- Con Haiku: ≈$378.75
- Con Sonnet: ≈$6,600.00
- Ahorro potencial: $6,221.25
💰 Impacto en Costos: El uso de Haiku para consultas simples representa un ahorro del 94.26% en comparación con Sonnet. Para un millón de consultas similares, esto podría traducirse en un ahorro de más de $6,221.
Esta información de costos resalta la importancia del routing inteligente en la optimización de recursos y presupuesto, especialmente en implementaciones a gran escala.
Análisis Programático
Si quieres explorar más a fondo el comportamiento del router, aquí tienes un script de Python que puedes usar:
import boto3
import json
from datetime import datetime
class PromptRouterAnalyzer:
def __init__(self, region_name='us-east-1'):
self.bedrock_runtime = boto3.client('bedrock-runtime', region_name=region_name)
self.bedrock = boto3.client('bedrock', region_name=region_name)
self.router_arn = self._get_router_arn()
def _get_router_arn(self):
"""
Obtiene el ARN del Anthropic Prompt Router.
"""
try:
response = self.bedrock.list_prompt_routers()
for router in response['promptRouterSummaries']:
if router['promptRouterName'] == 'Anthropic Prompt Router':
return router['promptRouterArn']
raise Exception("Router Anthropic no encontrado")
except Exception as e:
print(f"Error obteniendo ARN del router: {str(e)}")
raise
def analyze_prompt(self, prompt):
request_body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": prompt
}
]
}
response = self.bedrock_runtime.invoke_model(
modelId=self.router_arn,
body=json.dumps(request_body)
)
response_body = json.loads(response['body'].read())
return {
'model_used': response_body.get('model', 'Unknown'),
'tokens': {
'input': response_body.get('usage', {}).get('input_tokens', 0),
'output': response_body.get('usage', {}).get('output_tokens', 0)
}
}
Conclusiones y Reflexiones
Después de esta exploración práctica del Intelligent Prompt Routing, emergen conclusiones significativas en varios aspectos:
1. Eficiencia en la Selección de Modelos
- El router demuestra precisión al dirigir consultas simples a Haiku y análisis complejos a Sonnet
- La selección no solo optimiza costos sino también tiempos de respuesta
- Las decisiones de routing parecen considerar tanto la complejidad como la longitud del prompt
2. Impacto Financiero
- Las pruebas revelan un ahorro potencial del 94.26% cuando se utiliza Haiku para consultas apropiadas
- A escala empresarial (1 millón de consultas):
- Escenario Haiku: $378.75
- Escenario Sonnet: $6,600.00
- Ahorro potencial: $6,221.25
- La diferencia en costos es especialmente relevante en aplicaciones de alto volumen
3. Rendimiento y Latencia
- Haiku no solo es más económico sino también más rápido para consultas simples
- Haiku: ~3.7 segundos
- Sonnet: ~9.3 segundos
- La reducción en latencia puede tener un impacto significativo en la experiencia del usuario
4. Consideraciones para Implementación
- Optimización de Prompts:
- Estructurar las consultas de manera clara y concisa
- Usar inglés para asegurar el funcionamiento óptimo del router
- Monitoreo de Uso:
- Seguimiento de patrones de selección de modelos
- Análisis de costos y consumo de tokens
- Evaluación continua de la efectividad del routing
5. Limitaciones y Áreas de Mejora
- Soporte exclusivo para prompts en inglés
- Visibilidad limitada sobre los criterios de decisión del router
- Conjunto limitado de modelos disponibles durante la preview
🚀 ProTip Final: Para maximizar los beneficios del Intelligent Prompt Routing, es crucial analizar los patrones de uso de tu aplicación. Un ahorro del 94.26% en costos operativos puede ser la diferencia entre un proyecto viable y uno que excede su presupuesto.
El Intelligent Prompt Routing de Amazon Bedrock demuestra ser una herramienta valiosa para optimizar tanto el rendimiento como los costos en aplicaciones de IA. Su capacidad para dirigir automáticamente las consultas al modelo más apropiado no solo simplifica la arquitectura sino que también puede resultar en ahorros significativos a escala. Para casos de uso que requieren razonamiento multi-paso o el uso de herramientas externas, considera complementar esta estrategia con Amazon Bedrock Agents, que añade capacidades de orquestación sobre el modelo seleccionado.
¿Has implementado el Intelligent Prompt Routing en tu organización? ¿Qué patrones de uso y ahorro has observado? Comparte tus experiencias en los comentarios.



Inicia la conversación