

Tabla de Contenidos
- El Mapa de Memoria en AWS: Dónde Estamos Parados
- El Caso: Un Agente de Diagnóstico de Infraestructura
- Cómo Funciona AgentCore Memory Episódica
- Implementación Paso a Paso
- El Output Real: Así Luce lo que Genera AWS
- Namespaces: La Decisión de Diseño Más Importante
- Los Números Reales
- El Servicio por Dentro: Métricas de Observabilidad
- Lecciones Aprendidas (y Un Par de Gotchas)
- Conclusión
- Recursos Oficiales 📚
AgentCore Memory Episódica: Cuando Tu Agente Aprende de la Experiencia 🧠
Llevas semanas afinando el prompt de tu agente. Cada vez que aparece un caso edge nuevo, lo documentas, lo agregas a las instrucciones, y vuelves a desplegar. El system prompt ya supera los 4,000 tokens. Y aun así, la semana pasada el agente cometió exactamente el mismo error que tuvo con otro usuario hace tres semanas — uno que ya estaba “documentado” en las instrucciones, pero que el modelo sencillamente no priorizó en el momento correcto.
El problema no es el modelo. El problema es que tu agente no tiene memoria de experiencias. Solo tiene memoria de instrucciones.
Esa distinción, que parece semántica, cambia completamente el enfoque. Y es exactamente el gap que AgentCore Memory Episódica viene a cerrar.
En el artículo sobre AgentCore Evaluations, prometí cubrir esta capacidad. Hoy cerramos esa deuda — y si ya viste cómo medir si tu agente funciona bien, ahora veremos cómo hacer que aprenda activamente de lo que vivió.
El Mapa de Memoria en AWS: Dónde Estamos Parados
Antes de entrar en la episódica, vale la pena ubicarnos. A lo largo del tiempo, AWS ha evolucionado sus capacidades de memoria de agentes en capas distintas. Es fácil confundirlas porque todas “recuerdan cosas”, pero sirven propósitos muy diferentes.
Memoria de sesión en Bedrock Agents clásica — la que exploramos en el artículo de multiagentes: persiste resúmenes entre sesiones usando un memoryId. Funcional, pero básica. El agente recuerda que algo pasó, no cómo lo resolvió ni qué aprendió de eso.
Session Management APIs — lo que cubrimos en el artículo de Bedrock Sessions: gestión de estado completo dentro y entre sesiones, sin depender del agente de Bedrock. Más control, más código, mismo límite: no hay aprendizaje, solo persistencia.
AgentCore Memory con estrategias long-term — el servicio gestionado anunciado en 2025 que permite extraer hechos, preferencias y resúmenes de sesión de forma automática. Gran avance. Pero sigue siendo memoria declarativa: sabe que “el usuario prefiere instancias en us-east-1”, no recuerda que la última vez que intentó hacer un rollback en esa región usó primero el approach incorrecto y tuvo que corregirlo.
AgentCore Memory Episódica — anunciada en re:Invent 2025 como estrategia long-term adicional: captura experiencias completas, las estructura en episodios, y genera reflections que cruzan múltiples episodios para extraer patrones generalizables. Esta es la diferencia entre recordar un hecho y recordar cómo aprendiste ese hecho.
La distinción que más me ayudó a entenderlo: la memoria semántica te dice qué sabes. La memoria episódica te dice cómo llegaste a saberlo — y por qué cierto approach funcionó mejor que otro.
El Caso: Un Agente de Diagnóstico de Infraestructura
Para hacer esto concreto, construí un agente DevOps que diagnostica incidentes de infraestructura en AWS. El escenario es familiar: alguien reporta timeouts intermitentes en producción, el agente investiga con herramientas (CloudWatch, RDS, EC2), e intenta resolver o escalar.
Sin memoria episódica, cada incidente es tratado como si fuera el primero. Con ella, después de varios incidentes similares de RDS el agente sabe que cuando aparecen ciertos síntomas combinados, verificar primero el connection pool antes de escalar instancias resuelve la mayoría de los casos.
Ese conocimiento no viene de que alguien lo escribió en el system prompt. Viene de la experiencia acumulada del propio agente. Todo el código de este proyecto está disponible en github.com/codecr/bedrock-memory.
Cómo Funciona AgentCore Memory Episódica
Cuando tu agente envía eventos a AgentCore Memory con la estrategia episódica habilitada, el servicio ejecuta un pipeline de tres etapas automáticamente:
Extracción (Extraction) — Analiza el episodio turno por turno mientras ocurre. Para cada turno registra: la situación que enfrentó el agente, la intención de esa acción específica, qué herramientas usó y con qué parámetros, el razonamiento detrás de la decisión, y si ese turno fue exitoso. El servicio detecta automáticamente si el episodio está completo (el usuario logró su objetivo) o si continúa.
Consolidación (Consolidation) — Cuando el episodio se completa, sintetiza todos los turnos en un registro único que captura la situación global, la intención del usuario, si el objetivo se logró, y insights del episodio: qué approaches funcionaron, cuáles fallaron y por qué.
Reflexión (Reflection) — La parte más interesante. El módulo de reflexión toma el episodio recién consolidado, busca semánticamente episodios similares en el historial, y genera reflections — patrones generalizables que aplican a escenarios futuros. Cada reflection tiene un título, una descripción de cuándo aplica, hints accionables, y un score de confianza entre 0.1 y 1.0 que crece con cada episodio que confirma el patrón.
⚠️ Punto importante de timing: A diferencia de las otras estrategias de AgentCore Memory (semántica, summary, preferencias de usuario), los registros episódicos solo se generan cuando el episodio se completa. Si la conversación queda a medias, el sistema espera antes de generar el episodio. Esto tiene implicaciones en cómo diseñas el flujo de tu agente — los episodios incompletos aparecen con latencia mayor.
Implementación Paso a Paso
Paso 1: Configuración del Recurso de Memoria
AgentCore Memory usa dos clientes boto3 separados: el control plane (bedrock-agentcore-control) para crear y configurar recursos, y el data plane (bedrock-agentcore) para enviar eventos y recuperar memorias.
La clase MemoryManager en el repositorio encapsula ambos clientes. Lo más importante aquí es la estructura del create_memory: los namespaces de episodios llevan {actorId}/{sessionId} para organizar cada incidente, y las reflections van a nivel de actor — así el agente aprende de todos sus incidentes, no solo del actual.
# memory_manager.py
import boto3
import time
from datetime import datetime
class MemoryManager:
def __init__(self, region_name: str):
# Control plane: crear y gestionar recursos de memoria
self.control_client = boto3.client(
'bedrock-agentcore-control', region_name=region_name
)
# Data plane: escribir eventos y recuperar memorias
self.data_client = boto3.client(
'bedrock-agentcore', region_name=region_name
)
def create_memory_resource(self, name: str, description: str) -> str:
response = self.control_client.create_memory(
name=name,
description=description,
eventExpiryDuration=90, # Eventos raw retenidos 90 días
memoryStrategies=[{
'episodicMemoryStrategy': {
'name': 'IncidentEpisodes',
# Episodios por agente + sesión (un incidente = una sesión)
'namespaces': ['/incidents/{actorId}/{sessionId}'],
# Reflections a nivel de actor — insight global del agente
'reflectionConfiguration': {
'namespaces': ['/incidents/{actorId}']
}
}
}]
)
memory_id = response['memory']['id']
# El recurso tarda ~2 minutos en quedar ACTIVE
while True:
status = self.control_client.get_memory(
memoryId=memory_id
).get('memory', {}).get('status')
if status == 'ACTIVE':
break
elif status == 'FAILED':
raise Exception("Falló la creación del recurso de memoria")
time.sleep(15)
return memory_id
Un punto de diseño relevante: el actorId representa al agente (o combinación agente-usuario, según tu caso de uso), y el sessionId representa cada incidente individual. Esto permite que las reflections a nivel de actor acumulen aprendizaje de todos los incidentes sin mezclar datos entre sesiones.
Paso 2: Registrar el Incidente como Eventos
Cada interacción del agente — mensajes del usuario, respuestas, y especialmente resultados de herramientas — se registra como un evento. El rol TOOL es particularmente valioso: le da al módulo de extracción el contexto de qué información tenía el agente al tomar cada decisión.
def register_event(self, memory_id: str, actor_id: str,
session_id: str, content: str, role: str):
"""
role puede ser: 'USER', 'ASSISTANT', 'TOOL'
"""
self.data_client.create_event(
memoryId=memory_id,
actorId=actor_id,
sessionId=session_id,
eventTimestamp=datetime.now(),
payload=[{
'conversational': {
'content': {'text': content},
'role': role
}
}]
)
En seed_memory.py puedes ver cómo se registra un incidente completo con los tres roles. Este fragmento muestra el patrón con el incidente real de RDS que usamos para probar el sistema:
# seed_memory.py — registro del incidente incident-001
manager.register_event(
memory_id=memory_id, actor_id=actor_id,
session_id='incident-001', role='USER',
content=(
'Timeouts intermitentes en checkout-api desde hace 20 minutos. '
'Afecta al 30% de las requests. El servicio usa RDS PostgreSQL.'
)
)
manager.register_event(
memory_id=memory_id, actor_id=actor_id,
session_id='incident-001', role='ASSISTANT',
content='Entendido. Comenzaré investigando el estado actual de la instancia '
'RDS y las métricas de conexiones activas.'
)
# El resultado de la herramienta es clave — sin esto el módulo de extracción
# no puede reconstruir el razonamiento del agente
manager.register_event(
memory_id=memory_id, actor_id=actor_id,
session_id='incident-001', role='TOOL',
content=json.dumps({
'tool': 'describe_rds_metrics',
'params': {'instance': 'checkout-prod-db', 'period_minutes': 30},
'result': {
'DatabaseConnections': 485,
'MaxConnections': 500,
'CPUUtilization': 42,
'FreeableMemory_GB': 8.2,
'ReadLatency_ms': 120
}
})
)
manager.register_event(
memory_id=memory_id, actor_id=actor_id,
session_id='incident-001', role='ASSISTANT',
content=(
'Las métricas muestran 485 de 500 conexiones máximas (97%). '
'CPU y memoria están normales — descarta sobrecarga de recursos. '
'El cuello de botella está en el connection pool. '
'Voy a verificar si hay conexiones zombie.'
)
)
# ... más turnos TOOL + ASSISTANT hasta la confirmación del usuario ...
manager.register_event(
memory_id=memory_id, actor_id=actor_id,
session_id='incident-001', role='USER',
content='Excelente, eso resolvió el problema. Los timeouts desaparecieron.'
)
La confirmación final del usuario (“resolvió el problema”) es la señal que AgentCore usa para detectar que el episodio está completo y lanzar el pipeline de consolidación y reflexión.
Paso 3: Esperar la Generación del Episodio
AgentCore Memory procesa los episodios de forma asíncrona. Después de registrar todos los eventos, el servicio necesita tiempo para ejecutar extracción → consolidación → reflexión:
def wait_for_episode(self, memory_id: str, actor_id: str,
session_id: str, timeout_minutes: int = 10):
namespace = f'/incidents/{actor_id}'
deadline = time.time() + (timeout_minutes * 60)
while time.time() < deadline:
response = self.data_client.retrieve_memory_records(
memoryId=memory_id,
namespace=namespace,
searchCriteria={'searchQuery': session_id},
maxResults=5
)
records = response.get('memoryRecordSummaries', [])
if records:
print(f"✅ Episodio generado para sesión {session_id}")
return records[0]
print("⏳ Esperando episodio...")
time.sleep(30)
return None
En la práctica, con los 5 incidentes del seed (34 eventos en total), AWS generó los 5 episodios y 5 reflections en aproximadamente 30-60 minutos. No es tiempo real — es algo que ocurre en segundo plano mientras el agente sigue atendiendo otros incidentes.
Paso 4: Recuperar Experiencias Relevantes
Antes de iniciar cualquier diagnóstico nuevo, el agente consulta la memoria episódica. La API usa búsqueda semántica con searchCriteria.searchQuery — no es búsqueda por keywords exactas, sino por similitud de significado:
def retrieve_experiences(self, memory_id: str, actor_id: str,
query: str, max_results: int = 3) -> dict:
response = self.data_client.retrieve_memory_records(
memoryId=memory_id,
namespace=f'/incidents/{actor_id}',
searchCriteria={
'searchQuery': query
},
maxResults=max_results
)
records = response.get('memoryRecordSummaries', [])
# Los registros retornan como JSON — episodios y reflections
# se distinguen por la presencia de campos específicos
episodios = []
reflections = []
for record in records:
content_text = record.get('content', {}).get('text', '')
try:
content_json = json.loads(content_text)
# Episodios: tienen 'situation' y 'turns'
if 'situation' in content_json and 'turns' in content_json:
episodios.append(record)
# Reflections: tienen 'title' y 'use_cases'
elif 'title' in content_json and 'use_cases' in content_json:
reflections.append(record)
except json.JSONDecodeError:
pass
return {'episodios': episodios, 'reflections': reflections}
Un detalle importante sobre el formato: la documentación de AWS muestra ejemplos en XML, pero en la práctica el servicio retorna JSON. Los campos son situation, turns, intent, assessment para episodios, y title, use_cases, hints, confidence para reflections. El código maneja los dos formatos por compatibilidad.
Paso 5: Inyectar el Contexto en el Agente
La recuperación por sí sola no hace nada — el valor está en cómo preparas al agente con esa información antes del diagnóstico. En agent.py, las experiencias se incorporan al system prompt antes de llamar a Bedrock Converse:
# agent.py — construcción del system prompt con experiencias
def _build_system_prompt(self, experiences: dict) -> str:
prompt = """Eres un agente DevOps experto en diagnóstico de infraestructura AWS.
Tu especialidad: RDS (PostgreSQL, MySQL, Aurora), EC2, problemas de conexiones,
latencia, CPU y memoria. Usa un enfoque metódico: analiza síntomas, identifica
métricas a verificar, interpreta resultados, proporciona diagnóstico y solución.
"""
# Primero las reflections — orientan la estrategia general
if experiences['reflections']:
prompt += "\n=== PATRONES APRENDIDOS DE EXPERIENCIAS PREVIAS ===\n\n"
for reflection in experiences['reflections']:
content = json.loads(reflection.get('content', {}).get('text', ''))
score = reflection.get('score', 0)
prompt += f"[Relevancia: {score:.2f}]\n"
prompt += f"Patrón: {content.get('title', '')}\n"
prompt += f"Aplica cuando: {content.get('use_cases', '')}\n"
hints = content.get('hints', [])
if isinstance(hints, list):
prompt += "Recomendaciones:\n"
for hint in hints[:5]:
prompt += f" - {hint}\n"
prompt += f"Confianza: {content.get('confidence', '')}\n\n"
# Luego los episodios — ejemplos concretos de casos similares
if experiences['episodios']:
prompt += "\n=== CASOS SIMILARES RESUELTOS ANTERIORMENTE ===\n\n"
for episode in experiences['episodios'][:2]: # Solo los 2 más relevantes
content = json.loads(episode.get('content', {}).get('text', ''))
prompt += f"Situación: {content.get('situation', '')}\n"
prompt += f"Aprendizaje: {content.get('reflection', '')}\n"
prompt += "---\n\n"
prompt += "\nBasándote en tu experiencia previa, proporciona un diagnóstico " \
"claro y accionable. Si reconoces un patrón similar a casos anteriores, " \
"menciónalo explícitamente.\n"
return prompt
La documentación de AWS distingue cuándo usar cada tipo: reflections para orientación estratégica de alto nivel (qué verificar primero, qué errores evitar), episodios cuando el nuevo problema es muy específico y ya existe un caso casi idéntico resuelto. Para el agente DevOps, la combinación de ambos es lo que da el mejor resultado.
El Output Real: Así Luce lo que Genera AWS
Una vez que el pipeline procesa los eventos, los registros retornan con esta estructura JSON. Esto es un ejemplo representativo de lo que generó el servicio para nuestro incidente de RDS:
Episodio:
{
"situation": "Agente DevOps investigando timeouts intermitentes en servicio checkout-api. Instancia RDS PostgreSQL en producción. Síntoma: 30% de requests con timeout.",
"intent": "Diagnosticar y resolver la causa raíz de timeouts en base de datos de checkout",
"turns": [
{
"action": "Consultar métricas de conexiones RDS con describe_rds_metrics",
"thought": "Verificar primero si el problema es de recursos (CPU, memoria) o de conexiones",
"assessment": "Exitoso — descubrió 97% de utilización del límite de conexiones"
},
{
"action": "Analizar conexiones zombie con check_zombie_connections",
"thought": "CPU y memoria normales descarta recursos; conexiones altas sugiere pool mal gestionado",
"assessment": "Exitoso — identificó 180 conexiones idle in transaction"
}
],
"assessment": "Yes",
"reflection": "Para timeouts en RDS con CPU normal: verificar conexiones antes de escalar. Conexiones idle in transaction son señal de fuga de conexiones en la aplicación."
}
Reflection (generada después de múltiples episodios similares):
{
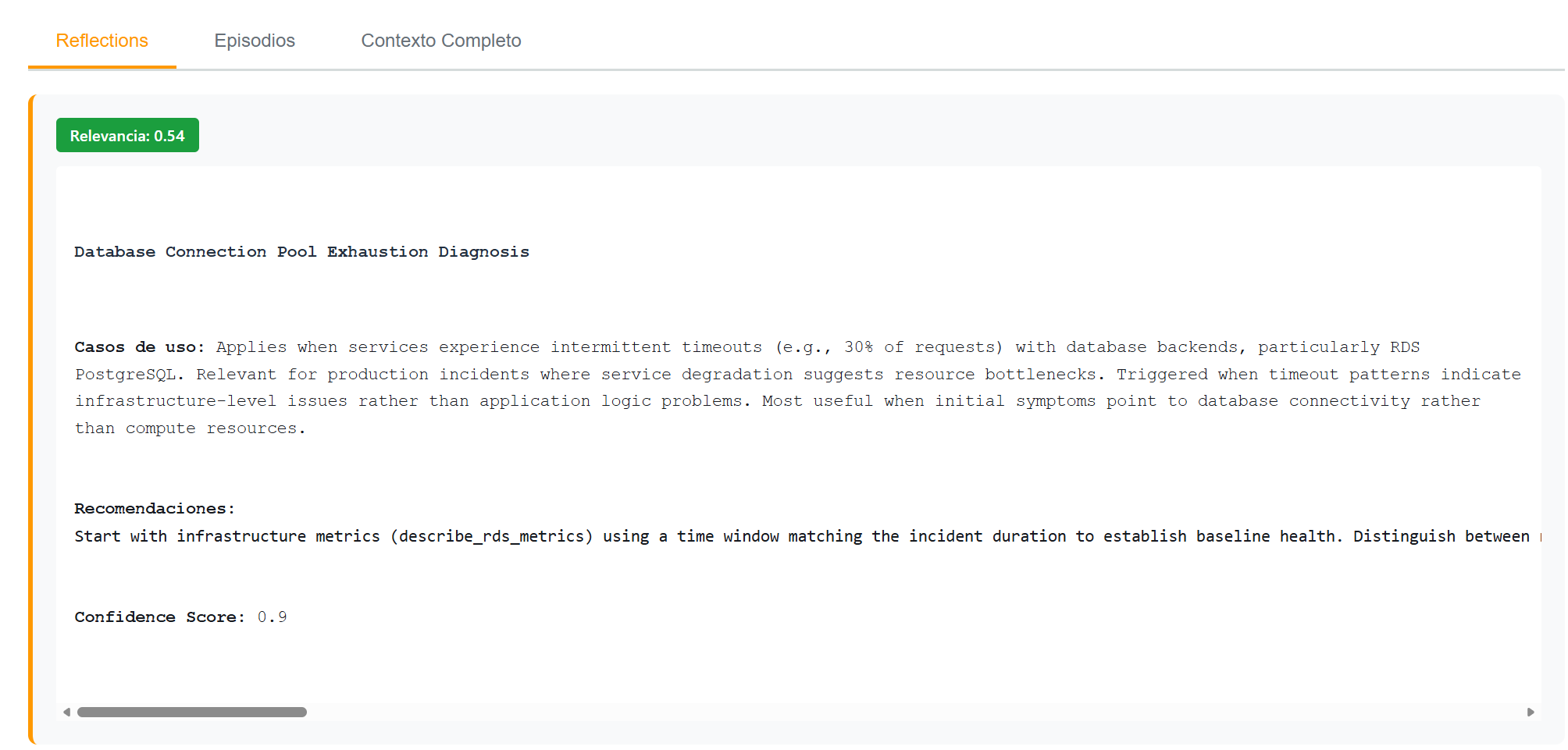
"title": "Database Connection Pool Exhaustion Diagnosis",
"use_cases": "Applies when services experience intermittent timeouts with database backends, particularly RDS PostgreSQL. Relevant for production incidents where service degradation suggests resource bottlenecks. Most useful when initial symptoms point to database connectivity rather than compute resources.",
"hints": [
"Start with infrastructure metrics (describe_rds_metrics) using a time window matching the incident duration to establish baseline health.",
"Distinguish between resource exhaustion (high CPU/memory) and connection pool exhaustion (high DatabaseConnections with normal CPU).",
"When DatabaseConnections exceeds 80% of maximum, prioritize connection pool investigation over vertical scaling.",
"Check for idle-in-transaction connections as these indicate application-level connection leaks.",
"Apply immediate remediation (kill zombie connections) before implementing permanent fixes."
],
"confidence": 0.9
}
Observa el score de confianza en 0.9 — ese valor creció con cada incidente adicional que confirmó el patrón. Cuando el primer episodio se genera, la confianza es baja. Después de cinco incidentes similares resueltos de la misma manera, el sistema tiene alta confianza en el patrón.
 Reflection con score de relevancia 0.54 para una query de timeouts RDS. El sistema identifica correctamente el patrón de connection pool exhaustion.
Reflection con score de relevancia 0.54 para una query de timeouts RDS. El sistema identifica correctamente el patrón de connection pool exhaustion.
Y esto es lo que retorna para una query sin memoria relevante — cuando el problema es de red entre regiones, algo que el agente nunca ha visto:
 Para una query de latencia inter-regional, los scores bajan a 0.38 y 0.37. El agente recupera los registros más cercanos disponibles, pero la baja relevancia indica que no hay experiencia previa específica.
Para una query de latencia inter-regional, los scores bajan a 0.38 y 0.37. El agente recupera los registros más cercanos disponibles, pero la baja relevancia indica que no hay experiencia previa específica.
Namespaces: La Decisión de Diseño Más Importante
La estructura de namespaces determina el alcance del aprendizaje. Vale la pena pensarlo bien porque no es trivial cambiarlo después.
El patrón que usamos — episodios en /incidents/{actorId}/{sessionId} y reflections en /incidents/{actorId} — genera insights a nivel de agente. Un solo agente aprende de todos los incidentes que ha atendido.
# Opción A: Aprendizaje por agente (lo que implementamos)
# Un agente aprende de sus propios incidentes
'namespaces': ['/incidents/{actorId}/{sessionId}'] # episodios
'reflectionConfiguration': {'namespaces': ['/incidents/{actorId}']} # reflections
# Opción B: Aprendizaje global (todos los agentes comparten insights)
# Útil si tienes múltiples instancias del mismo agente
'namespaces': ['/incidents/{actorId}/{sessionId}']
'reflectionConfiguration': {'namespaces': ['/incidents']} # ← sin actorId
# Opción C: Aprendizaje por tipo de servicio (si categorizas incidentes)
'namespaces': ['/incidents/rds/{actorId}/{sessionId}']
'reflectionConfiguration': {'namespaces': ['/incidents/rds']}
La documentación de AWS es explícita en este punto: las reflections pueden abarcar múltiples actores dentro del mismo recurso de memoria. Si diferentes actores representan diferentes usuarios finales (no solo diferentes instancias del mismo agente), las reflections a nivel global podrían mezclar información de distintas personas. En ese caso, mantén las reflections a nivel de actor o combina con Guardrails.
Los Números Reales
Después de sembrar la memoria con 5 incidentes históricos (34 eventos en total) y esperar a que AWS generara los episodios y reflections, corrí dos queries comparativas para validar que el sistema discrimina correctamente:
Query 1 — CON memoria relevante:
Timeouts intermitentes en checkout-api. RDS PostgreSQL.
Conexiones al 92%. CPU al 40%.
Query 2 — SIN memoria relevante:
Alta latencia entre regiones.
El tráfico de us-east-1 a eu-west-1 es muy lento.
| Métrica | Query RDS | Query Red | Diferencia |
|---|---|---|---|
| Score promedio de relevancia | 0.497 | 0.390 | +27.4% |
| Episodios recuperados | 5 | 4 | — |
| Reflections recuperadas | 5 | 6 | — |
| Menciona experiencia previa | ✅ Sí | ❌ No | Cualitativa |
| Orden específico de diagnóstico | ✅ Sí | ❌ No | Cualitativa |
El score promedio de relevancia (0.497 vs 0.390) refleja cuán semánticamente cercanos son los registros recuperados al query. Para la query de RDS, los scores individuales de las reflections son [0.568, 0.511, 0.491] — todos sobre 0.49. Para la query de red, los mismos registros de BD se recuperan pero con scores [0.406, 0.404, 0.385] — el sistema los trae porque son lo más cercano disponible, pero con menor confianza en su relevancia.
Lo más interesante no son los números sino el comportamiento cualitativo del agente. Para la query de RDS, el diagnóstico empieza así:
 El agente reconoce el patrón inmediatamente: “Connection Pool Exhaustion con Zombie Connections”. Propone el plan de diagnóstico de 3 pasos sin exploración previa, basado en experiencia acumulada.
El agente reconoce el patrón inmediatamente: “Connection Pool Exhaustion con Zombie Connections”. Propone el plan de diagnóstico de 3 pasos sin exploración previa, basado en experiencia acumulada.
Para una query de Lambda con errores IAM (algo que el agente conoce solo parcialmente de su memoria), el comportamiento es diferente — responde con contexto de patrones generales pero aclara los límites de su experiencia:
 Con 2 episodios y 8 reflections relevantes, el agente da un diagnóstico útil pero más genérico, y señala explícitamente que el problema está fuera de su especialidad principal.
Con 2 episodios y 8 reflections relevantes, el agente da un diagnóstico útil pero más genérico, y señala explícitamente que el problema está fuera de su especialidad principal.
AWS publicó en enero 2026 benchmarks formales con el dataset τ2-bench (escenarios de atención al cliente en retail y aerolíneas). Sin memoria, el agente resuelve exitosamente al menos una vez el 65.8% de los escenarios. Con reflections cruzadas, ese número sube a 77.2% — pero más importante, la consistencia (resolver 3 de 4 intentos) mejora de 42.1% a 55.7%. El agente no solo resuelve más cosas, sino que las resuelve con más confiabilidad.
El Servicio por Dentro: Métricas de Observabilidad
Una cosa que no esperaba encontrar al revisar la consola de AWS fue la sección de Observability en el recurso de memoria. Muestra métricas operativas en tiempo real:
 En 24 horas: 58 invocaciones a create_event (131.3ms latencia promedio, 0 errores), 52 invocaciones a retrieve_memory_records (189.1ms latencia promedio, 0 errores), 14 memorias long-term extraídas. Sin alertas configuradas, sin código extra.
En 24 horas: 58 invocaciones a create_event (131.3ms latencia promedio, 0 errores), 52 invocaciones a retrieve_memory_records (189.1ms latencia promedio, 0 errores), 14 memorias long-term extraídas. Sin alertas configuradas, sin código extra.
Los 14 registros extraídos corresponden a los 5 episodios más las 9 reflections generadas a partir de los patrones detectados entre incidentes similares. La latencia promedio de recuperación de 189ms es completamente aceptable para un sistema de diagnóstico donde el tiempo de respuesta total del agente es de 5-7 segundos.
Lecciones Aprendidas (y Un Par de Gotchas)
La latencia episódica es real y hay que diseñar para ella. Los otros tipos de memoria generan registros de forma continua. Los episódicos esperan a que el episodio complete. En producción esto significa que no puedes confiar en que el aprendizaje de un incidente esté disponible inmediatamente para el siguiente. Tiene latencia de minutos, no segundos.
Los resultados de herramientas son el insumo más valioso. En nuestro agente de diagnóstico, las métricas que retornan las herramientas son lo que permite al módulo de extracción entender por qué el agente tomó cada decisión. Sin incluirlos como eventos con role TOOL, los episodios pierden mucha profundidad.
El formato real es JSON, no XML. La documentación oficial muestra fragmentos XML en algunos lugares, pero el servicio retorna JSON con campos como situation, turns, use_cases, hints. Si construyes el parser esperando XML, vas a tener problemas. El código en el repositorio maneja los dos formatos, pero en la práctica solo vas a ver JSON.
Episodios vs. reflections no es una elección — es una combinación. Los benchmarks de τ2-bench muestran que las reflections mejoran más el rendimiento en problemas abiertos (+11.4% en Pass^1), mientras que los episodios como ejemplos funcionan mejor en flujos bien definidos con procedimientos claros. Para el caso DevOps, la combinación de ambos da el mejor resultado.
El control plane vs. data plane es una distinción real con consecuencias. bedrock-agentcore-control tiene cuotas mucho más bajas que bedrock-agentcore. Crear el recurso de memoria es una operación de control plane que debes hacer en tiempo de infraestructura (IaC, despliegue), no en runtime. En producción, el agente solo debería llamar al data plane.
El nombre episodic puede confundir. La estrategia no recuerda “lo que pasó como si fuera un diario”. Recuerda cómo se resolvió algo con suficiente estructura para que sea útil en situaciones futuras similares. Es menos memoria episódica humana y más como un runbook que se escribe solo.
Conclusión
Hay un momento en el desarrollo de un agente en el que ya no puedes seguir mejorándolo solo con prompts. Has cubierto los casos comunes, has agregado ejemplos, has refinado el tono. Pero el agente sigue sin capitalizar la experiencia que ya acumuló — cada interacción comienza desde cero.
AgentCore Memory Episódica es la respuesta a ese momento. No reemplaza el diseño cuidadoso del agente ni la evaluación continua (para eso, Evaluations). Lo que hace es agregar una capa de aprendizaje que se alimenta sola conforme el agente trabaja.
El agente DevOps que construimos empieza sin saber nada sobre timeouts de RDS. Después de cinco incidentes similares, sus reflections tienen 90% de confianza y le dicen exactamente en qué orden verificar las métricas, qué patrones son señales de qué tipo de problema, y qué soluciones temporales vs. permanentes aplicar. Ese conocimiento no lo escribió nadie — lo acumuló el agente de su propia experiencia.
Con esto cerramos la serie de las tres capacidades anunciadas en re:Invent 2025. Evaluations para medir calidad en producción. Policy para definir límites que el agente no puede cruzar. Y Episódica para que aprenda de lo que vive. Tres piezas que juntas cambian fundamentalmente lo que significa llevar un agente a producción.
¿Ya tienes agentes en producción que se beneficiarían de este tipo de memoria? ¿O tienes casos donde la latencia de generación de episodios sería un bloqueante? Me interesa conocer qué están construyendo — los comentarios están abiertos.



Inicia la conversación