

Tabla de Contenidos
- El Contexto: Por Qué Esto Me Importa
- Las 5 Estrategias de Chunking (Y una aclaración importante)
- El Setup: Aislar el Chunking Como Única Variable
- Hallazgo #1:
NONENo Es Tan Inocente Como Suena - Hallazgo #2:
SEMANTICTiene un Límite de 1MB Por Archivo Que No Se Documenta al Elegirla - El Corte Cualitativo Antes de Medir Calidad
- Los 7 Gotchas de Infraestructura Que Nadie Documenta Junto
- Gotcha #1: ¿Por qué falla la ingesta con “Filterable metadata must have at most 2048 bytes”?
- Gotchas #2-4: ¿Por qué la Lambda del CUSTOM chunker falla con “Access denied for lambda:InvokeFunction”?
- Gotcha #5: ¿Por qué Sonnet 4.6 no aparece como modelo juez válido en Bedrock Evaluations?
- Gotcha #6: ¿Por qué el eval job falla con “metric name Builtin.ContextRelevance is not available”?
- Gotcha #7: ¿Por qué Bedrock Evaluations dice “does not have permission to call the KB API” aunque las policies parezcan correctas?
- Sumando los Gotchas
- Los Resultados Cuantitativos
- Observación 1: Hay Dos Grupos, No un Ranking Continuo
- Observación 2: Entre las 3 Estrategias “Buenas”, el Margen es Pequeño
- Observación 3: Faithfulness Es la Métrica Más Discriminativa
- Observación 4:
SEMANTICTerminó Peor QueNONE. El Análisis Contraintuitivo - Observación 5: Helpfulness Es la Métrica Menos Útil Para Comparar Chunking
- Tabla de Decisión: ¿Qué Estrategia Para Tu Caso?
- Mi Recomendación Personal
- Lo Que Queda Pendiente
- Conclusión
Hace algunas semanas me encontré con una pregunta que escucho cada vez más seguido en las conversaciones con arquitectos y equipos de desarrollo:
“Voy a implementar un RAG con Bedrock Knowledge Bases, ¿qué estrategia de chunking uso? Veo que hay cinco y todas suenan razonables.”
Es una pregunta sensata y honestamente no tenía una respuesta que me dejara tranquilo. La documentación de AWS explica cada estrategia con claridad. Los blogs técnicos hablan de ellas en términos conceptuales. Las comparativas que había visto solían quedarse en el “cada una tiene su caso de uso”. Pero pocos datos concretos sobre cómo se comportan con corpus real.
Así que decidí hacer el benchmark yo mismo. Con una metodología reproducible, datos reales, y métricas objetivas. Lo que encontré me sorprendió lo suficiente como para que valga la pena este artículo, porque la realidad es bastante distinta de lo que sugiere la documentación.
🎯 Spoiler: De las 5 estrategias, solo 3 pudieron procesar un corpus de documentación técnica real. Las otras 2 fallaron en la etapa de ingesta, no por mala calidad de chunking, sino por límites duros del servicio que no se mencionan al momento de elegir la estrategia.
En este artículo comparto la metodología completa, los resultados cuantitativos (25 preguntas evaluadas con LLM-as-a-judge), y algo que me parece aún más valioso: los 7 problemas de infraestructura que tuve que resolver para que todo funcionara con Terraform. Porque el código de ejemplo “oficial” asume cosas que no siempre son ciertas.
📌 TL;DR — Datos clave antes de seguir leyendo
- Titan V2 embeddings: límite de 50,000 caracteres / 8,192 tokens por request → hace inviable
NONEpara corpus normal.- SEMANTIC chunking: límite empírico de 1 MB por archivo → falla con la mayoría de documentación técnica.
- S3 Vectors: límite de 2,048 bytes de filterable metadata → resolver declarando
nonFilterableMetadataKeysal crear el índice.- Sonnet 4.6/4.5/Opus 4.x no están en la allowlist de jueces de Bedrock Evaluations → usar Nova Pro como juez cross-family.
- Ganadores del benchmark con corpus real: Custom (0.94), Hierarchical (0.92), Fixed (0.88) en Correctness. NONE y SEMANTIC fallaron en ingesta antes de poder evaluarse justamente.
- Recomendación para producción: arranca con
FIXED_SIZE(max_tokens=512, overlap=20%) + S3 Vectors + evaluación periódica. Cambia solo si los datos justifican la complejidad.
El Contexto: Por Qué Esto Me Importa
Llevo varios proyectos construyendo RAGs sobre Bedrock Knowledge Bases, y cada vez que llega el momento de configurar el chunking aparece la misma conversación. Alguien del equipo pregunta “¿hierarchical o semantic?”, otro dice “probemos fixed, suena lo más seguro”, y al final la decisión se toma por intuición, no por evidencia.
El problema con ese enfoque es que cuando el RAG no funciona bien en producción, no sabemos si fue el chunking, el embedding, el retrieval, o el generator. Estamos debuggeando a ciegas.
Mi objetivo con este benchmark era doble:
- Producir datos reproducibles que cualquier equipo pueda usar para justificar una decisión de arquitectura.
- Aislar el chunking como variable única para que los resultados sean honestos.
Spoiler adicional: lograr esa segunda parte fue más difícil de lo que esperaba.
Las 5 Estrategias de Chunking (Y una aclaración importante)
Antes de entrar a los resultados, vamos a alinearnos sobre qué son estas 5 estrategias. Según la documentación oficial de Amazon Bedrock, las opciones disponibles en el ChunkingConfiguration son:
| Estrategia | Qué hace |
|---|---|
NONE |
No chunkea. Cada archivo se trata como un único chunk. |
FIXED_SIZE |
Divide el texto en chunks de un tamaño aproximado configurable (tokens), con overlap. |
HIERARCHICAL |
Divide el documento en dos capas: chunks “padre” grandes y chunks “hijo” más pequeños derivados de ellos. |
SEMANTIC |
Divide basándose en similitud semántica entre oraciones usando un embedding model. |
CUSTOM (Lambda) |
Tu propia lógica de chunking ejecutada como transformación Lambda. |
🔍 ProTip #1: En muchos lugares verás mencionado “multimodal chunking” como una sexta estrategia. No lo es. El chunking multimodal (audio, video, imágenes) ocurre a nivel del embedding model (por ejemplo, Nova multimodal embeddings) y su configuración es independiente de
ChunkingConfiguration. Las 5 estrategias de arriba aplican solo a documentos de texto, aunque tengas contenido multimodal en tu data source. Esta confusión se la veo a muchos arquitectos.
El Setup: Aislar el Chunking Como Única Variable
La tesis del benchmark es simple: si vas a comparar estrategias de chunking, todo lo demás debe ser idéntico entre las KBs. Cualquier otra variable contamina los resultados.
Por eso, las 5 Knowledge Bases comparten:
- El mismo corpus en S3 (3 archivos)
- El mismo embedding model:
amazon.titan-embed-text-v2:0, 1024 dimensiones - El mismo vector store: Amazon S3 Vectors (más sobre esto más adelante)
- El mismo modelo generador:
us.anthropic.claude-sonnet-4-6vía inference profile - El mismo modelo juez:
amazon.nova-pro-v1:0 - El mismo conjunto de 25 preguntas con ground truth
Lo único que cambia entre KBs: el ChunkingConfiguration.
¿Por qué S3 Vectors como backend?
Cuando empecé a armar esta infraestructura, originalmente apunté a OpenSearch Serverless, que es el backend por default cuando creas una KB desde la consola. Hice el cálculo de costos:
| Backend | Costo base por tener la infra arriba |
|---|---|
| OpenSearch Serverless (vector collection) | ~$11.52 USD/día (floor de 2 OCUs × $0.24/hora, mínimo obligatorio en producción para vector collections) |
| S3 Vectors | $0 base — pagas solo storage ($0.06/GB/mes), PUT ($0.20/GB) y queries ($2.5/M API calls + $/TB procesados) |
Para un benchmark que implica varias iteraciones y potencial debugging, esa diferencia es determinante. Amazon S3 Vectors alcanzó GA el 2 de diciembre de 2025 y se integra nativamente con Bedrock Knowledge Bases. El storage cuesta $0.06/GB/mes, los PUT cuestan $0.20/GB logical subido, y las queries se cobran por API call ($2.50/M) más $/TB procesados. No hay costo base por mantener la infra arriba — a diferencia de las OCUs de OpenSearch, no hay compute corriendo cuando no estás usando el servicio.
🔍 ProTip #2: S3 Vectors tiene tres trade-offs que debes conocer antes de elegirlo:
- Latencia: 100-800ms vs 10-100ms de OpenSearch.
- Solo búsqueda semántica: no soporta hybrid search en Bedrock KB (confirmado en la documentación oficial).
- Metadata limitado: máximo 1KB de custom metadata y 35 keys por vector cuando se usa con Bedrock KB. Si usas chunking
HIERARCHICALcon token counts altos, AWS advierte explícitamente que puedes exceder los límites de metadata porque las relaciones parent-child se guardan como non-filterable metadata.Para un benchmark offline esto no importa. Para producción con keyword matching exacto o metadata rica, probablemente quieras OpenSearch. Usa S3 Vectors cuando priorices costo sobre latencia extrema.
El Corpus
Elegí 3 documentos con estructuras distintas, a propósito, para estresar diferentes supuestos:
| Archivo | Tamaño | Caracteres aprox. | Estructura | Hipótesis inicial |
|---|---|---|---|---|
well-architected-framework.pdf |
14 MB | ~2,530,000 | Jerárquica marcada (6 pilares → principios → prácticas) | Debería favorecer HIERARCHICAL |
bedrock-agentcore-dg.pdf |
17 MB | ~2,400,000 | Prosa técnica densa con cambios sutiles de tema | Debería favorecer SEMANTIC |
blog-rag-evaluation.html |
1 MB | ~1,080,000 | Narrativa larga tipo blog | Debería exponer limitaciones de FIXED_SIZE |
Como voy a mostrar más adelante, ninguna de esas hipótesis iniciales sobrevivió al primer intento de ingestión. Y ese fue precisamente el hallazgo más importante.
Hallazgo #1: NONE No Es Tan Inocente Como Suena
Mi primer intento de ingestar el corpus con la estrategia NONE arrojó este error:
Malformed input request: expected maxLength: 50000, actual: 2530200,
please reformat your input and try again.
(Service: BedrockRuntime, Status Code: 400)
Issue occurred while processing file: well-architected-framework.pdf
Confieso que me tomó un segundo entender lo que estaba pasando.
La estrategia NONE instruye a Bedrock a no hacer chunking: el documento completo se manda al embedding model como un solo request. Y aquí está el detalle crucial: según la documentación oficial de Amazon Titan Text Embeddings V2, el modelo acepta “como máximo 8,192 tokens o 50,000 caracteres”.
Mi PDF de Well-Architected tiene 2.5 millones de caracteres. Cincuenta veces el límite.
¿Qué significa esto en la práctica?
La estrategia NONE es perfectamente válida, pero solo si tu corpus ya viene pre-chunkeado. Es decir, solo si cada archivo en tu bucket S3 es una unidad lógica pequeña (una FAQ, un producto, un ticket, una definición de glosario) que cabe en esos 50,000 caracteres.
La propia documentación lo reconoce, aunque de forma sutil:
“If you choose this option [NONE], you may want to pre-process your documents by splitting them into separate files.”
Pero la palabra clave aquí es “may” (podrías). En la realidad es un “must” (debes).
🎯 ProTip #3: Cuando veas la opción
NONEen la consola de Bedrock, mentalmente tradúcela aPRE_CHUNKED. No es “sin chunking”: es “chunking delegado a ti, antes de subir a S3”. Si tu corpus son PDFs técnicos normales,NONEva a fallar. Si es una base de datos de preguntas frecuentes con una pregunta por archivo, es perfecta.
Resultado: con mi corpus, NONE indexó 1 de 3 documentos (el HTML de 1 MB también excedió el límite en muchas partes, pero procesó algo). Los dos PDFs fallaron completamente.
Hallazgo #2: SEMANTIC Tiene un Límite de 1MB Por Archivo Que No Se Documenta al Elegirla
Pasé a la siguiente estrategia con cierta expectativa. SEMANTIC chunking analiza el texto con un embedding model auxiliar y detecta “breakpoints” entre oraciones donde cambia el tema. Suena bien para documentación técnica densa con cambios sutiles de tema, ¿no?
El log de ingesta me dijo otra cosa:
File body text exceeds size limit of 1000000 for semantic chunking.
[Files: s3://.../bedrock-agentcore-dg.pdf,
s3://.../well-architected-framework.pdf]
Mil millones, no. Un millón de caracteres. Por archivo.
¿Por qué esto es problemático?
Revisé la documentación de chunking cuidadosamente. Describe los parámetros de semantic chunking (max tokens, buffer size, breakpoint percentile threshold). Habla de los costos adicionales por usar un foundation model. Pero el límite de 1 MB por archivo no se menciona en la pantalla donde eliges la estrategia. Lo descubres cuando la ingestión falla.
Y es un límite práctico, no teórico: una documentación de desarrollador promedio de AWS ya excede ese tamaño. Un whitepaper normal lo excede. Prácticamente cualquier documentación técnica real de más de unas 200-300 páginas lo excede.
⚠️ ProTip #4: Si tienes documentación técnica grande y quieres usar
SEMANTICchunking, tienes que hacer pre-splitting tú mismo antes de subir a S3. Lo cual tiene una ironía interesante: estás haciendo chunking manual para poder usar la estrategia de chunking “semántica”. Para la mayoría de corpus empresariales reales (manuales, políticas, whitepapers),SEMANTICno es viable sin preprocesamiento significativo.
Resultado: SEMANTIC también indexó 1 de 3 documentos (solo el HTML del blog, que estaba justo debajo del límite).
El Corte Cualitativo Antes de Medir Calidad
Después de los dos primeros hallazgos, ya tenía la mitad de la historia del benchmark antes de correr una sola evaluación. Esta es la tabla que nadie te muestra cuando comparas estrategias de chunking:
| Estrategia | Documentos indexados | Por qué |
|---|---|---|
NONE |
1 / 3 | Falla con archivos > 50,000 caracteres |
FIXED_SIZE |
3 / 3 | ✅ Sin restricciones prácticas de tamaño |
HIERARCHICAL |
3 / 3 | ✅ Sin restricciones prácticas de tamaño |
SEMANTIC |
1 / 3 | Falla con archivos > 1,000,000 caracteres |
CUSTOM |
3 / 3 | ✅ (después de resolver 3 gotchas que veremos después) |
Antes de evaluar calidad de retrieval, solo 3 de las 5 estrategias pueden ingestar documentación técnica normal sin preprocesamiento. Este es el dato que deberías llevarte aunque no leas nada más del artículo.
Los 7 Gotchas de Infraestructura Que Nadie Documenta Junto
Antes de mostrar los números cuantitativos, necesito contar algo que me tomó más tiempo de lo que esperaba: los problemas de infraestructura que aparecieron al intentar desplegar todo con Terraform. Son 7 en total, y son el tipo de cosa que solo descubres cuando te sientas a hacerlo desde cero, sin la consola asistiéndote.
Los dejo aquí porque cualquier persona que intente reproducir este benchmark va a encontrarse con varios de ellos, y tenerlos juntos en un solo lugar ahorra mucho tiempo.
Gotcha #1: ¿Por qué falla la ingesta con “Filterable metadata must have at most 2048 bytes”?
Al primer intento de ingesta, las 5 KBs fallaron con el mismo error:
Invalid record for key '<uuid>':
Filterable metadata must have at most 2048 bytes
(Service: S3Vectors, Status Code: 400)
S3 Vectors tiene un límite de 2,048 bytes de metadata “filtrable” por vector. Por default, Bedrock KB mete dos cosas como filtrable: AMAZON_BEDROCK_TEXT (el texto del chunk) y AMAZON_BEDROCK_METADATA (metadata del documento). Casi cualquier chunk de tamaño razonable excede los 2 KB solo con el texto.
La solución: al crear el índice de S3 Vectors, declarar explícitamente esos campos como no-filtrables:
resource "aws_s3vectors_index" "strategies" {
# ... otros campos ...
metadata_configuration {
non_filterable_metadata_keys = [
"AMAZON_BEDROCK_TEXT",
"AMAZON_BEDROCK_METADATA",
]
}
}
🚨 ProTip #5: Los índices de S3 Vectors son inmutables. Si creas un índice sin esta configuración y te das cuenta después, no hay manera de editarlo: tienes que hacer
terraform destroyyapplyotra vez. Verifica esto antes de aprovisionar.
Gotchas #2-4: ¿Por qué la Lambda del CUSTOM chunker falla con “Access denied for lambda:InvokeFunction”?
Configurar un Lambda chunker suena directo en el papel: escribes el código, le das permisos IAM, listo. En la práctica, tuve que resolver tres problemas distintos que se manifiestan con errores muy similares. Si resuelves solo uno o dos, sigue fallando pero con un mensaje que parece el mismo.
Problema 1: Falta la aws_lambda_permission
Primer error:
Access denied for lambda:InvokeFunction for Lambda function ARN
arn:aws:lambda:us-east-1:...:function:...-chunker:$LATEST.
Darle al IAM role del KB un permiso lambda:InvokeFunction no basta. Lambda también exige que la función tenga una resource-based policy que permita a bedrock.amazonaws.com invocarla:
resource "aws_lambda_permission" "bedrock_invoke" {
statement_id = "AllowBedrockKBInvoke"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.custom_chunker.function_name
principal = "bedrock.amazonaws.com"
source_arn = "arn:aws:bedrock:${var.aws_region}:${data.aws_caller_identity.current.account_id}:knowledge-base/*"
}
Cuando creas la KB por consola, AWS genera este permiso automáticamente. Con Terraform crudo, tienes que declararlo explícitamente.
Problema 2: El Resource del role del KB necesita incluir el qualifier wildcard
Con el permiso resource-based en su lugar, el siguiente intento falló con el mismo mensaje. La diferencia sutil: ahora el problema es del lado del IAM role del KB.
La razón: Bedrock invoca la Lambda usando el ARN qualificado <arn>:$LATEST, no el ARN base. Si tu policy dice:
Resource = aws_lambda_function.custom_chunker.arn
IAM no matchea. La solución es incluir ambos:
Resource = [
aws_lambda_function.custom_chunker.arn,
"${aws_lambda_function.custom_chunker.arn}:*",
]
Problema 3: El contrato del handler usa keys relativos, no URIs S3
Con los dos problemas IAM resueltos, la Lambda al fin se invocaba. Y explotaba con:
ValueError: Invalid S3 URI: intermediate/.../well-architected-framework_1.JSON
Los ejemplos que circulan muestran event["inputFiles"][*]["contentBatches"][*]["key"] tratado como si fuera un URI s3://bucket/key. No lo es. Bedrock manda solo el key path relativo al bucket intermedio, que te llega en event["bucketName"]:
def handler(event, context):
intermediate_bucket = event["bucketName"]
for input_file in event["inputFiles"]:
for batch in input_file["contentBatches"]:
key = batch["key"] # relative path, NO un URI
response = s3.get_object(Bucket=intermediate_bucket, Key=key)
# ... procesar chunking ...
s3.put_object(Bucket=intermediate_bucket, Key=output_key, Body=...)
# Output: key, NO URI
processed_batches.append({"key": output_key})
🔧 ProTip #6: Para tener un CUSTOM chunker funcional desplegado con Terraform necesitas los tres fixes juntos. Resolver solo uno o dos produce errores que se parecen lo suficiente como para mandarte a debuggear la cosa equivocada. Si el tuyo no funciona a la primera, revisa los tres antes de asumir que es otra cosa.
Gotcha #5: ¿Por qué Sonnet 4.6 no aparece como modelo juez válido en Bedrock Evaluations?
Cuando intenté usar Sonnet 4.6 como juez para las evaluaciones:
ValidationException: The requested evaluator model(s)
us.anthropic.claude-sonnet-4-6 are not supported.
Retrocediendo a Sonnet 3.7:
ValidationException: Access denied. This Model is marked by provider as
Legacy and you have not been actively using the model in the last 30 days.
Bedrock Evaluations mantiene una allowlist fija de modelos que pueden actuar como juez. Según la documentación oficial verificada a abril 2026, la lista es:
amazon.nova-pro-v1:0anthropic.claude-3-5-sonnet-20240620-v1:0anthropic.claude-3-5-sonnet-20241022-v2:0anthropic.claude-3-7-sonnet-20250219-v1:0anthropic.claude-3-haiku-20240307-v1:0anthropic.claude-3-5-haiku-20241022-v1:0meta.llama3-1-70b-instruct-v1:0mistral.mistral-large-2402-v1:0
Tres observaciones importantes:
- Sonnet 4.6 no está en la lista. Tampoco Sonnet 4.5, ni Opus 4.x. La allowlist va dos generaciones atrás del estado del arte.
- La consola de Bedrock muestra cualquier inference profile disponible al elegir juez, incluyendo modelos que luego serán rechazados. La validación ocurre server-side en
CreateEvaluationJob. - Los modelos “soportados” pueden volverse inutilizables por desuso. Si un modelo está marcado como Legacy y tu cuenta no lo invocó en 30 días, Bedrock lo deniega aunque esté en la allowlist.
Mi solución: usar amazon.nova-pro-v1:0 como juez. Además de estar en la lista oficial, me dio algo técnicamente más defendible para el artículo: un juez cross-family (AWS Nova evaluando respuestas de Anthropic Sonnet 4.6), lo cual reduce el sesgo de auto-evaluación intra-familia.
🎓 ProTip #7: Adopta cross-family judging como patrón, no solo por las limitaciones de AWS sino porque es metodológicamente más sólido. “Claude evaluando a Claude” es una crítica válida en papers académicos. Nova evaluando Claude (o viceversa) elimina esa crítica.
Gotcha #6: ¿Por qué el eval job falla con “metric name Builtin.ContextRelevance is not available”?
Mi siguiente intento, después de resolver el juez:
ValidationException: The metric name Builtin.ContextRelevance is not available
for RAG retrieveAndGenerate evaluations.
Bedrock Evaluations divide las métricas built-in para RAG en dos conjuntos mutuamente excluyentes según el tipo de job:
| Métrica | retrieveAndGenerate (end-to-end) |
retrieve (solo retrieval) |
|---|---|---|
Builtin.Correctness |
✅ | ❌ |
Builtin.Completeness |
✅ | ❌ |
Builtin.Helpfulness |
✅ | ❌ |
Builtin.Faithfulness |
✅ | ❌ |
Builtin.ContextRelevance |
❌ | ✅ |
Builtin.ContextCoverage |
❌ | ✅ |
Si mandas una métrica del set equivocado, el job completo falla, incluso si las otras métricas sí aplican al tipo de job.
Además, hay un matiz importante sobre retrieveAndGenerate: este tipo de job produce scores que combinan ambas cosas: el retrieval y la generación. De ahí que Correctness y Faithfulness puedan caer simultáneamente cuando el retrieval falla (como veremos en la Observación 3). Para aislar si el problema está en el retrieval o en el generator, necesitas correr también el job retrieve-only con ContextRelevance y ContextCoverage.
La documentación oficial sí separa las métricas por tipo de job, pero muchos ejemplos y blogs listan las 6 en la misma lista, induciendo al error.
💡 ProTip #8: Para un benchmark completo necesitas dos jobs por KB: uno
retrieveAndGeneratecon las 4 métricas de generación, y otroretrievecon las 2 de retrieval. Eso duplica el costo y tiempo de evaluación. En este benchmark corrí solo los jobs end-to-end; un siguiente paso sería correr también retrieve-only para tener las 6 métricas.
Gotcha #7: ¿Por qué Bedrock Evaluations dice “does not have permission to call the KB API” aunque las policies parezcan correctas?
Ultimo gotcha. Con todo lo anterior resuelto, los eval jobs seguían fallando:
The provided role does not have permission to call the KB API.
El mensaje te hace pensar que es un problema de permissions policy. En realidad son dos cosas:
- Trust policy: el
aws:SourceArndebe incluir el pattern de evaluation jobs:"Condition": { "StringLike": { "aws:SourceArn": "arn:aws:bedrock:us-east-1:<account>:evaluation-job/*" } } - Permission policy: los ARNs de las KBs que el job va a consultar deben estar específicos, no con wildcard:
"Resource": [ "arn:aws:bedrock:us-east-1:<account>:knowledge-base/<kb-id-1>", ... ]
Cualquiera de las dos ausente produce el mismo error genérico. Te manda a buscar el bug en el lugar equivocado.
🔍 ProTip #9: Cuando Bedrock Evaluations te diga “does not have permission to call the KB API”, siempre revisa ambos lados del IAM: trust policy Y permission policy. No es lo mismo que cuando otros servicios AWS dan ese error.
Sumando los Gotchas
Los 7 problemas me tomaron varias horas de debugging. Todos son resolvibles y todos están arreglados en el repositorio con el código Terraform completo. Pero vale la pena documentarlos juntos porque nadie lo había hecho antes y porque cualquier persona que replique esto va a tropezar con al menos 3 de ellos.
Ahora sí, los números del benchmark.
Los Resultados Cuantitativos
25 preguntas con ground truth. 5 Knowledge Bases. 125 prompts al generator (Claude Sonnet 4.6) y cerca de 500 juicios del evaluator (Nova Pro). Los scores son el promedio por métrica sobre las 25 preguntas:
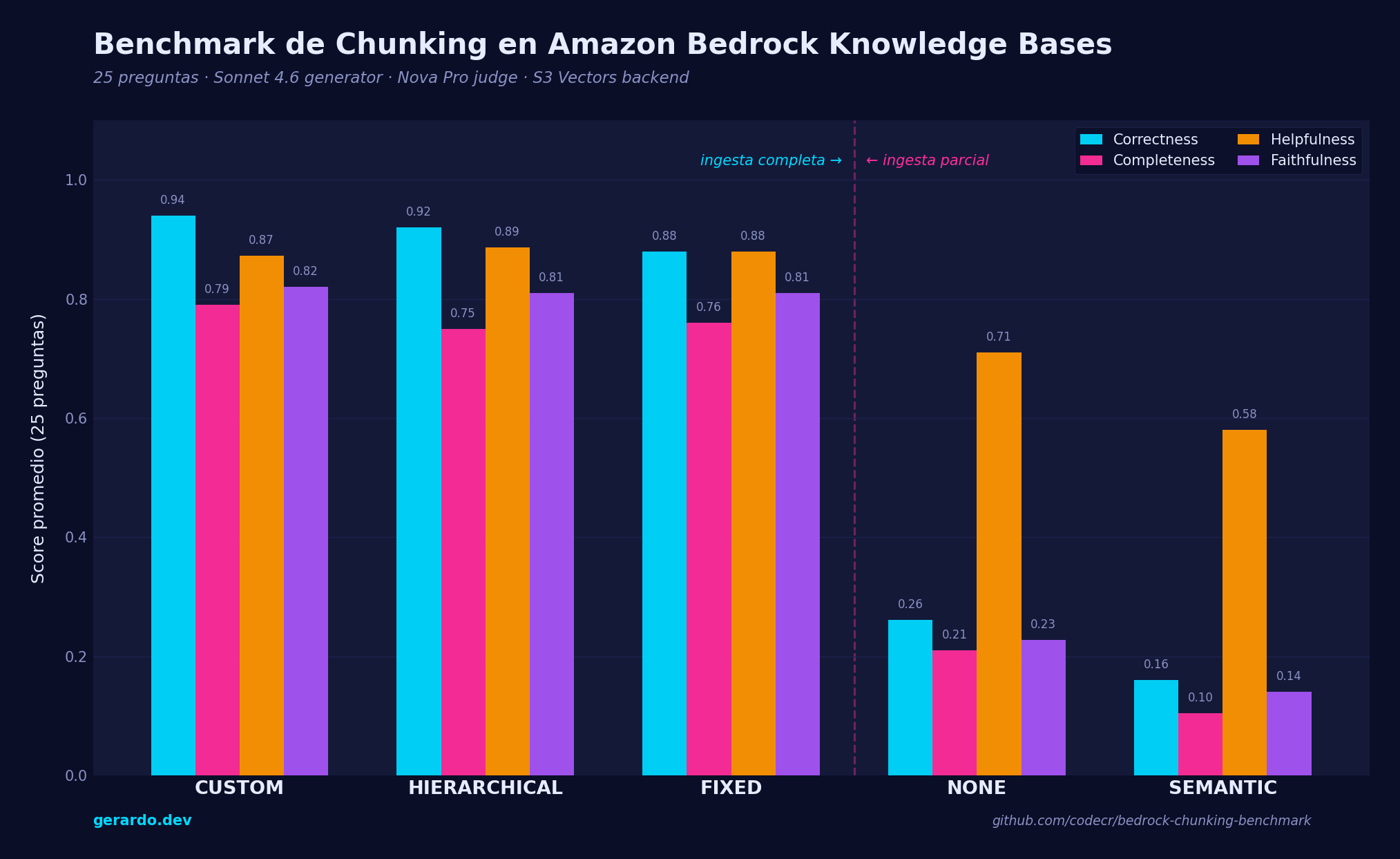 Figura 1: Scores promedio por estrategia de chunking en 25 preguntas con ground truth. El “cliff” entre el grupo alto (Custom, Hierarchical, Fixed) y el grupo bajo (None, Semantic) está causado por fallas de ingesta, no por calidad intrínseca del chunking.
Figura 1: Scores promedio por estrategia de chunking en 25 preguntas con ground truth. El “cliff” entre el grupo alto (Custom, Hierarchical, Fixed) y el grupo bajo (None, Semantic) está causado por fallas de ingesta, no por calidad intrínseca del chunking.
| Estrategia | Correctness | Completeness | Helpfulness | Faithfulness |
|---|---|---|---|---|
| custom | 0.940 | 0.790 | 0.873 | 0.820 |
| hierarchical | 0.920 | 0.750 | 0.887 | 0.810 |
| fixed | 0.880 | 0.760 | 0.880 | 0.810 |
| none | 0.261 | 0.210 | 0.710 | 0.228 |
| semantic | 0.160 | 0.104 | 0.580 | 0.140 |
Déjame compartir cinco observaciones con los datos en la mano.
Observación 1: Hay Dos Grupos, No un Ranking Continuo
Fixed, Hierarchical y Custom viven entre 0.75 y 0.94 en todas las métricas. None y Semantic viven entre 0.10 y 0.71. La brecha en Correctness entre el tercer lugar del grupo alto (Fixed, 0.880) y el mejor del grupo bajo (None, 0.261) es de 0.619 puntos.
Eso no se explica con varianza estadística. Es un corte cualitativo producido por las limitaciones de ingesta que documenté arriba. Los scores bajos de None y Semantic no son un juicio sobre la calidad de esas estrategias: son la consecuencia aritmética de que no pudieron indexar 2 de los 3 documentos.
Si solo hubieras mirado esta tabla sin el contexto de ingesta, habrías concluido que Semantic chunking es terrible. Y sería una conclusión falsa. Lo que es terrible es intentar aplicar Semantic chunking a un corpus que excede su límite operacional.
Observación 2: Entre las 3 Estrategias “Buenas”, el Margen es Pequeño
- Custom gana 3 de 4 métricas (Correctness, Completeness, Faithfulness).
- Hierarchical gana Helpfulness por 0.007 sobre Fixed (prácticamente un empate).
- Diferencia entre el primero (Custom, 0.940) y el tercero (Fixed, 0.880) en Correctness: 0.060.
Un margen de 0.06 es medible pero no aplastante. Mi chunker custom (un recursive character splitter markdown-aware) está haciendo algo útil, pero no justifica el costo operacional del Lambda para un corpus genérico: Fixed te da el 94% del resultado sin los 3 gotchas de IAM, sin el costo del Lambda, sin el debugging adicional.
🎯 ProTip #10: Un custom chunker solo vale la pena si tienes un formato de documento muy específico donde el chunker genérico rompe unidades semánticas clave de tu dominio (código fuente, transcripts de llamadas, logs estructurados, contratos con cláusulas numeradas). Para documentación técnica estándar, Fixed gana por simplicidad operacional.
Observación 3: Faithfulness Es la Métrica Más Discriminativa
Mira la diferencia entre Correctness y Faithfulness para las estrategias que fallaron:
| Estrategia | Correctness | Faithfulness | Diferencia |
|---|---|---|---|
| none | 0.261 | 0.228 | -0.033 |
| semantic | 0.160 | 0.140 | -0.020 |
Faithfulness cae más fuerte que Correctness cuando la KB no tiene el contenido. ¿Por qué? Porque una respuesta puede ser correcta sin estar fundada en el contexto recuperado.
Cuando la KB no tiene el documento relevante indexado, Sonnet 4.6 igual produce una respuesta usando su conocimiento paramétrico. Si la respuesta casualmente coincide con el ground truth, Correctness le pone un score decente. Pero Faithfulness mide si la respuesta está sustentada en lo que la KB retornó, y la KB no retornó nada útil. Por eso Faithfulness se colapsa.
🔍 ProTip #11: Si estás diagnosticando un RAG que parece dar respuestas correctas pero “sospechosas”, Faithfulness es la métrica que te va a confirmar lo que intuyes. Una caída de Faithfulness es el indicador más temprano de que tu KB no está trayendo el contexto real — más sensible que Correctness.
Observación 4: SEMANTIC Terminó Peor Que NONE. El Análisis Contraintuitivo
💡 Hallazgo clave: Cuando una estrategia de chunking no puede ingestar la mayoría del corpus, el chunking fino amplifica el ruido de lo poco que sí ingestó. El chunking ausente lo unifica en un chunk gigante coherente que al menos es interpretable. Esto no es crítica a SEMANTIC como técnica — es un recordatorio de que los scores bajos no son representativos de la estrategia en su caso de uso adecuado.
Este fue el resultado que más me hizo detenerme a pensar. Semantic debería ser al menos tan bueno como None: chunkear “semánticamente” debería ser mejor que no chunkear.
Los datos dicen lo contrario. En las 4 métricas, Semantic está por debajo de None.
Mi hipótesis, después de analizar los datos:
Ambas estrategias solo pudieron indexar el mismo archivo: el HTML del blog (1.08 MB). Pero lo hacen de formas distintas:
-
NONEindexa ese HTML como un único chunk gigante de aproximadamente 1 millón de caracteres. Cuando el retrieval hace match sobre cualquier pregunta que se relacione al contenido del blog, recupera el blog entero como contexto. El recall es perfecto (todo el contenido está ahí), aunque el contexto sea muy ruidoso (la mayor parte del chunk no aplica a la pregunta). -
SEMANTICsubdivide ese mismo HTML en chunks más chicos y coherentes. Para las ~20 preguntas del benchmark cuyo tema no está en el blog (sino en los PDFs que Semantic no pudo indexar), el retrieval devuelve chunks pequeños que son superficialmente relevantes pero vacíos del contenido que la pregunta realmente necesita. El juez califica la respuesta como no fiel (el contexto recuperado no la soporta) y no correcta.
En otras palabras: cuando tu estrategia no puede ingestar la mayoría del corpus, el chunking fino amplifica el ruido de lo poco que sí ingestó. El chunking ausente lo unifica en un chunk gigante coherente que al menos es interpretable.
Esto no es una crítica a Semantic como técnica. Es un recordatorio adicional de que con un corpus que la estrategia no puede procesar, ningún score va a ser bueno, y los scores bajos tampoco son representativos de la estrategia en su caso de uso adecuado.
Observación 5: Helpfulness Es la Métrica Menos Útil Para Comparar Chunking
Mira el rango de Helpfulness entre todas las estrategias:
- custom: 0.873
- hierarchical: 0.887
- fixed: 0.880
- none: 0.710
- semantic: 0.580
El rango total es 0.30 puntos. Comparado con Correctness (rango 0.78) y Faithfulness (rango 0.68), Helpfulness casi no diferencia. Incluso las estrategias que indexaron casi nada del corpus sacaron entre 0.58 y 0.71.
El juez parece premiar “que la respuesta esté bien escrita, estructurada y sea útil en sí misma”, independientemente de si es correcta o fiel al contexto. Es una métrica de forma más que de fondo.
💡 ProTip #12: Si vas a elegir 3 métricas para comparar estrategias de chunking, elige Correctness, Faithfulness y Completeness en ese orden. Helpfulness es útil para medir la calidad del generator, no del chunking.
Tabla de Decisión: ¿Qué Estrategia Para Tu Caso?
Después de todo este análisis, esta es la recomendación que yo le daría a alguien hoy:
| Tu caso de uso | Estrategia recomendada | Razón |
|---|---|---|
| Documentación técnica (whitepapers, developer guides, manuales corporativos) | FIXED_SIZE (max_tokens=512, overlap=20%) |
Ingresa todo, scores altos, mínima complejidad. Cubre el 80% de casos. |
| Documentos con jerarquía muy marcada (libros con capítulos/secciones, documentación de APIs) | HIERARCHICAL |
Usa la estructura real del documento. Margen pequeño pero medible sobre FIXED_SIZE. |
| Corpus pre-chunkeado (cada archivo es una FAQ, un ticket, un producto) | NONE |
Único caso legítimo. Cada archivo debe ser < 50,000 caracteres. |
| Corpus de artículos/emails/blogs cortos (cada archivo < 1 MB) | SEMANTIC |
Preserva fronteras semánticas naturales. Solo si todos tus archivos son pequeños. |
| Formato muy específico (código fuente, transcripts, logs con estructura) | CUSTOM (Lambda) |
Cuando el chunker genérico rompe unidades semánticas del dominio. Asegúrate de tener presupuesto para debugging. |
| No estás seguro | FIXED_SIZE |
En serio. Empieza por aquí. Mide. Cambia después si los datos justifican el cambio. |
Mi Recomendación Personal
Si mañana tuviera que construir un RAG de producción con Bedrock Knowledge Bases, arrancaría con esta configuración:
- Chunking:
FIXED_SIZE, max_tokens=512, overlap=20% - Backend: S3 Vectors (excepto que necesite hybrid search)
- Embedding: Titan Text Embeddings v2, 1024 dimensiones
- Generator: Claude Sonnet 4.6 vía inference profile
- Evaluation: jobs periódicos con Nova Pro como juez (cross-family)
Y mediría Faithfulness y Correctness en un set de preguntas con ground truth desde el día 1. Solo consideraría moverme a Hierarchical o Custom si los números muestran un gap específico que justifique la complejidad adicional.
El chunking se vende a veces como la gran palanca del RAG. La realidad es que lo que más mueve la aguja es:
- Que tu estrategia pueda ingestar tu corpus sin preprocesamiento manual.
- Que tengas forma de medir que está funcionando.
- Que puedas iterar sobre esa medición.
Todo lo demás es ajuste fino.
Lo Que Queda Pendiente
Este benchmark tiene un scope acotado a propósito. Lo que sí podría ser un siguiente paso:
- Métricas retrieval-only (
ContextRelevance,ContextCoverage) con un segundo set de eval jobs. Lo dejé afuera por la partición de métricas (gotcha #6). - Grid search de parámetros dentro de cada estrategia. ¿Qué pasa si Fixed usa max_tokens=1024 en vez de 512? ¿Cuánto mueve la aguja el overlap?
- Corpus en español. Este benchmark usó documentación en inglés. Titan v2 es multilingüe, pero valdría la pena verificar si el corte cualitativo es igual en otros idiomas.
- Costo por consulta en producción con patrones de tráfico realistas. Este benchmark mide calidad; el costo operacional en tiempo real merece su propio análisis.
Si alguno de estos temas te interesa o quieres verlo cubierto en un artículo siguiente, déjame un comentario. Y si replicas este benchmark en tu propia cuenta y encuentras más gotchas o mejores resultados, me encantaría saberlo.
Conclusión
Armar este benchmark me cambió la forma de pensar sobre chunking en Bedrock Knowledge Bases. No porque descubrí que tal o cual estrategia es “mejor”, sino porque me quedó claro que la discusión normal sobre chunking tiene el orden equivocado.
Primero importa si tu estrategia puede ingestar tu corpus. Después importa si tu infra está bien configurada. Después importa tener métricas objetivas para comparar. Y solo al final, mucho después, importa el matiz de cuál estrategia tiene 0.06 puntos más que otra en una métrica específica.
Si este artículo te ahorra una tarde de debugging con los gotchas de infraestructura, me alegra el día. Si te ayuda a tomar una decisión de arquitectura con evidencia en vez de intuición, mejor todavía.
El código completo del benchmark (Terraform + Python + preguntas de evaluación) está en github.com/codecr/bedrock-chunking-benchmark. Cualquiera puede reproducir los resultados en su cuenta por unos 18-20 USD aproximadamente, gracias al costo prácticamente nulo de S3 Vectors como backend.
🚀 Pro Tip Final: Si vas a llevar un RAG a producción, invierte tiempo en evaluación antes de invertir tiempo en chunking. Una estrategia de chunking “mediocre” con buena evaluación te va a llevar más lejos que la “mejor” estrategia sin forma de medir si está funcionando.
Si te interesa profundizar en otras capacidades de Bedrock relacionadas, te invito a leer mis artículos sobre Bedrock Evaluations y Bedrock Guardrails, que complementan bien este análisis.
¡Nos vemos en el próximo artículo! No olviden compartir en los comentarios si han tenido experiencias similares configurando Knowledge Bases en producción, o si tienen dudas sobre alguno de los hallazgos. ¡Feliz desarrollo! 🚀



Inicia la conversación