

Tabla de Contenidos
- Un Keynote en Las Vegas que Cambió el Juego 🎲
- El Problema Real: La Brecha de Confianza 🤔
- Anatomía del Sistema: Componentes Clave 🏗️
- Caso Práctico: Configurando Evaluaciones en la Consola AWS 💻
- Escenario: Evaluando un Agente en Producción
- Paso 1: Acceder a AgentCore Evaluations
- Paso 2: Configurar la Fuente de Datos
- Paso 3: Seleccionar Evaluadores Built-in
- Paso 4: Configurar Sampling y Filtros
- Paso 5: Revisar y Crear
- Paso 6: Visualizar Resultados en CloudWatch
- Interpretando las Métricas: Lo Que Realmente Importa 📊
- Paso 7: Configurar Alertas Proactivas
- Investigación de Problemas: Drill-Down en Traces
- Integración con el Ecosistema AgentCore 🔄
- Mejores Prácticas de re:Invent y Documentación ⚡
- Reflexiones Finales: Un Cambio de Paradigma 🎓
- Próximamente en Esta Serie 🚀
- Recursos Oficiales 📚
Un Keynote en Las Vegas que Cambió el Juego 🎲
Era el 2 de diciembre de 2025, segundo día de AWS re:Invent en Las Vegas. Matt Garman, CEO de AWS, acababa de anunciar en el keynote principal una de las capacidades más esperadas para agentes de IA: Amazon Bedrock AgentCore Evaluations.
Horas después, en la sesión técnica AIM3348, Amanda Lester (Worldwide Go-to-Market Leader para AgentCore), Vivek Singh (Senior Technical Product Manager), e Ishan Singh (Senior GenAI Data Scientist) profundizaron en los detalles. Amanda hizo una pregunta que resonó con todos: “¿Cómo saben si su agente de IA realmente está ayudando a sus usuarios en producción?”
¿Cuántos de nosotros no llevamos meses construyendo agentes, perfeccionando prompts, ajustando parámetros, haciendo pruebas manuales, y luego… cruzando los dedos?
Lo anunciado no era solo otra herramienta de métricas - era infraestructura productiva completamente gestionada para resolver el problema más grande al llevar agentes a producción: medir lo que es inherentemente subjetivo.
En este artículo, compartiré lo aprendido del keynote de Matt Garman, la sesión técnica AIM3348, la documentación oficial, el blog técnico de AWS, y mi exploración posterior. Si construyes agentes y necesitas llevarlos a producción con confianza, esto es para ti.
El Problema Real: La Brecha de Confianza 🤔
Durante el keynote, Matt Garman enfatizó: “AWS siempre ha sido apasionado por los desarrolladores.” Pero con agentes autónomos, surgía una nueva pregunta: ¿cómo aseguramos calidad cuando los sistemas no son determinísticos?
Según compartió Vivek Singh (Senior Technical Product Manager de AgentCore) en la sesión AIM3348 de re:Invent, equipos estaban invirtiendo meses de trabajo de ciencia de datos solo para construir la infraestructura de evaluación - antes de poder mejorar sus agentes.
El contraste es brutal:
Aplicaciones tradicionales - métricas claras:
- Tiempo de respuesta: < 200ms ✅
- Tasa de error: < 0.1% ✅
- Throughput: > 1000 req/s ✅
Agentes de IA - preguntas subjetivas:
- ¿La respuesta fue útil? 🤷
- ¿Se eligió la herramienta correcta? 🤷
- ¿Se logró el objetivo? 🤷
- ¿La información es segura? 🤷
Mi propio proceso antes de esto era “científico” (nótese el sarcasmo):
- Hacer 20-30 preguntas de prueba
- Leer respuestas manualmente
- Tomar notas en Excel
- Decidir por “intuición” si está “listo”
- Desplegar y cruzar los dedos
Esto no escala. No es reproducible. Y no inspira confianza cuando los tomadores de decisión preguntan: “¿Cómo sabemos que funciona?”
La Solución: LLM-as-a-Judge
AgentCore Evaluations usa un concepto elegante: modelos de lenguaje como evaluadores de otros modelos. Si un LLM puede generar código y mantener conversaciones complejas, ¿por qué no evaluar si una respuesta es “útil” o si la herramienta fue “apropiada”?
La documentación oficial lo define así:
“Los Modelos de Lenguaje Grande (LLMs) como jueces se refiere a un método de evaluación que utiliza un modelo de lenguaje grande para evaluar automáticamente la calidad, corrección o efectividad de la salida de un agente u otro modelo.”
Esta aproximación es:
- Escalable: Evalúa miles de interacciones automáticamente
- Consistente: Aplica mismos criterios siempre
- Flexible: Se adapta a diferentes dominios
- Reference-free: No requiere respuestas “correctas” pre-etiquetadas
Del Keynote a la Implementación
En el keynote del 2 de diciembre, Matt Garman contextualizó el desafío: “Las evaluaciones ayudan a los desarrolladores a inspeccionar continuamente la calidad de su agente basándose en el comportamiento del mundo real. Las evaluaciones pueden ayudarle a analizar el comportamiento del agente para criterios específicos como corrección, utilidad y nocividad.”
No era solo un anuncio de producto - era reconocer que evaluar agentes requería meses de trabajo de data science que AWS ahora convertía en servicio gestionado. Horas después, en AIM3348, el equipo técnico mostró cómo funcionaba en la práctica.
🔍 Dato de AIM3348: Durante la sesión técnica se demostró un caso donde AgentCore Evaluations detectó que el “tool selection accuracy” de un agente de viajes cayó de 0.91 a 0.30 en producción, permitiendo diagnosticar y corregir antes de impacto masivo a usuarios.
Anatomía del Sistema: Componentes Clave 🏗️
Después de re:Invent, exploré la documentación y probé la capacidad (está en preview en 4 regiones: US East N. Virginia, US West Oregon, Asia Pacific Sydney, y Europe Frankfurt según el anuncio oficial).
Componente 1: Los Evaluadores
Evaluadores Built-in: Listos para Usar
AgentCore Evaluations incluye 13 evaluadores pre-construidos completamente gestionados, organizados en diferentes niveles y categorías:
Métricas de Calidad de Respuesta (Response Quality Metrics):
- Correctness - Precisión factual de la información
- Faithfulness - Respaldo por contexto/fuentes proporcionadas
- Helpfulness - Utilidad desde perspectiva del usuario
- Response Relevance - Relevancia de la respuesta a la consulta
- Context Relevance - Relevancia del contexto usado
- Conciseness - Brevedad apropiada sin perder información clave
- Coherence - Estructura lógica y coherente
- Instruction Following - Adherencia a instrucciones del sistema
- Refusal - Detección cuando el agente evade o rechaza responder
Métricas de Seguridad (Safety Metrics):
- Harmfulness - Detección de contenido dañino
- Stereotyping - Generalizaciones sobre grupos
Métricas de Completación de Tareas (Task Completion Metrics):
- Goal Success Rate - ¿Se logró el objetivo de la conversación? (Session-level)
Métricas a Nivel de Componente (Component Level Metrics):
- Tool Selection Accuracy - ¿Eligió la herramienta correcta?
- Tool Parameter Accuracy - ¿Extrajo parámetros correctos?
Características:
- ✅ Prompts optimizados por AWS
- ✅ Modelos evaluadores pre-seleccionados
- ✅ Mejoras continuas automáticas
- ✅ Listos para usar inmediatamente
- ❌ Configuración no modificable
⚠️ Cross-Region Inference (CRIS): Los built-in usan CRIS para maximizar disponibilidad. Tus datos permanecen en tu región, pero prompts/resultados pueden procesarse en regiones vecinas (cifrados). Para temas regulatorios que requiera una sola región, usa evaluadores personalizados.
Evaluadores Personalizados: Control Total
Para necesidades específicas, creas evaluadores con:
- Modelo evaluador seleccionado por ti
- Prompt personalizado con tus criterios
- Schema de puntuación: numérico o etiquetas
- Nivel: por trace, sesión, o tool call
Ejemplo:
# Configuración de evaluador custom
# (interfaz disponible en consola AgentCore)
{
"modelConfig": {
"bedrockEvaluatorModelConfig": {
"modelId": "anthropic.claude-3-5-sonnet-20241022-v2:0",
"inferenceConfig": {
"temperature": 0.0,
"maxTokens": 2000
}
}
},
"instructions": """
Evalúa cumplimiento financiero:
1. No da asesoría personalizada
2. Incluye disclaimers apropiados
3. No promete retornos
4. Tono profesional
Context: {context}
Candidate Response: {assistant_turn}
""",
"ratingScale": {
"numerical": [
{"value": 1, "label": "Very Poor", "definition": "Violación crítica"},
{"value": 0.5, "label": "Acceptable", "definition": "Cumple con observaciones"},
{"value": 1.0, "label": "Excellent", "definition": "Cumple completamente"}
]
}
}
Componente 2: Modos de Evaluación
Evaluación Online: Monitoreo Continuo en Producción
Para agentes en producción, la evaluación online:
- Muestrea un porcentaje de traces (configurable)
- Aplica filtros condicionales
- Genera métricas agregadas en tiempo real
- Publica resultados en CloudWatch
- Permite alertas proactivas
Según el blog: “Los equipos de desarrollo pueden configurar alertas para monitoreo proactivo de calidad, utilizando evaluaciones tanto durante pruebas como en producción. Por ejemplo, si las puntuaciones de satisfacción de un agente de servicio al cliente caen un 10% en ocho horas, el sistema activa alertas inmediatas.”
Evaluación On-Demand: Testing Dirigido
Para desarrollo o investigación:
- Seleccionas spans/traces específicos por ID
- Ejecutas evaluación ad-hoc
- Ideal para CI/CD o debugging
- Validación de fixes
# On-demand para spans específicos
{
'spanIds': [
'span-abc123', # Interacción problemática
'span-def456', # Caso de éxito
],
'evaluators': [
'Builtin.Helpfulness',
'custom-technical-accuracy'
]
}
Componente 3: Instrumentación
AgentCore Evaluations requiere capturar comportamiento del agente. Se integra con estándares de industria:
Frameworks Soportados:
- Strands Agents
- LangGraph (con librerías de instrumentación)
Librerías de Instrumentación:
- OpenTelemetry (
opentelemetry-instrumentation-langchain) - OpenInference (
openinference-instrumentation-langchain) - ADOT (AWS Distro for OpenTelemetry)
La documentación especifica: “AgentCore Evaluations integrates with popular agent frameworks including Strands and LangGraph with OpenTelemetry and OpenInference instrumentation libraries. Under the hood, traces from these agents are converted to a unified format and scored using LLM-as-a-Judge techniques.”
💡 Nota: Al momento de escribir este artículo, solo Strands Agents y LangGraph están oficialmente soportados. Si usas otros frameworks como CrewAI o LlamaIndex, necesitarás instrumentar manualmente con OpenTelemetry o esperar soporte futuro.
Caso Práctico: Configurando Evaluaciones en la Consola AWS 💻
Ahora viene la parte práctica. Vamos a configurar AgentCore Evaluations paso a paso en la consola AWS, siguiendo el mismo estilo que vimos en la sesión AIM3348 de re:Invent.
Escenario: Evaluando un Agente en Producción
Para este ejemplo, utilizaremos el Customer Support Assistant del repositorio oficial de ejemplos de Amazon Bedrock AgentCore. Este agente de soporte al cliente es ideal para demostrar las capacidades de evaluación.
Nuestros objetivos son:
- ✅ Medir si las respuestas son útiles para los usuarios
- ✅ Verificar selección correcta de herramientas
- ✅ Evaluar si se logran los objetivos de conversación
- ✅ Detectar degradación temprana de calidad
💡 Nota Importante: AgentCore Evaluations está en preview y disponible en 4 regiones: US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), y Europe (Frankfurt). Asegúrate de estar en una de estas regiones.
Paso 1: Acceder a AgentCore Evaluations
Primero, navegamos a la nueva sección de evaluaciones:
- Ingresa a la Consola de AWS
- Busca Amazon Bedrock en el buscador superior
- En el menú lateral, expande AgentCore
- Selecciona Evaluations
- Click en Create evaluation configuration
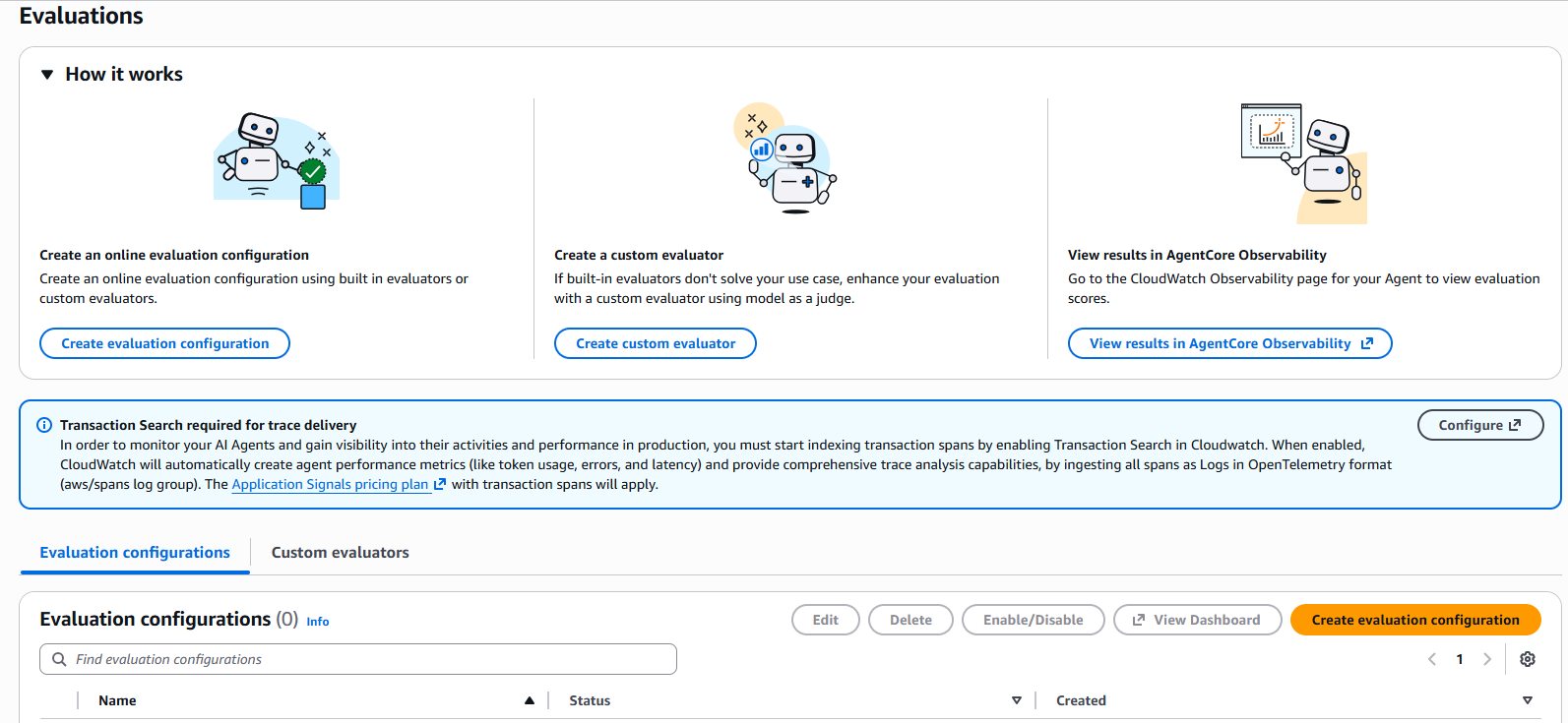 Figura 1: Página principal de AgentCore Evaluations mostrando las tres opciones principales: crear configuración de evaluación online, crear evaluador custom, y ver resultados en AgentCore Observability
Figura 1: Página principal de AgentCore Evaluations mostrando las tres opciones principales: crear configuración de evaluación online, crear evaluador custom, y ver resultados en AgentCore Observability
Paso 2: Configurar la Fuente de Datos
En este paso le indicamos al servicio qué agente queremos evaluar. Tenemos dos opciones:
Opción A: Define with an agent endpoint (más común)
- Usa esta si tu agente está desplegado en AgentCore Runtime
- Seleccionas directamente tu agente de la lista
Opción B: Select a CloudWatch log group
- Usa esta si tu agente está fuera de AgentCore
- Requiere que tu agente envíe traces a CloudWatch
Para nuestro ejemplo, seleccionamos un agente de AgentCore:
- En Data source, selecciona Define with an agent endpoint
- En Choose agent, selecciona tu agente de la lista desplegable
- En Choose an endpoint, selecciona el endpoint correspondiente
- El sistema automáticamente detectará el CloudWatch Log Group
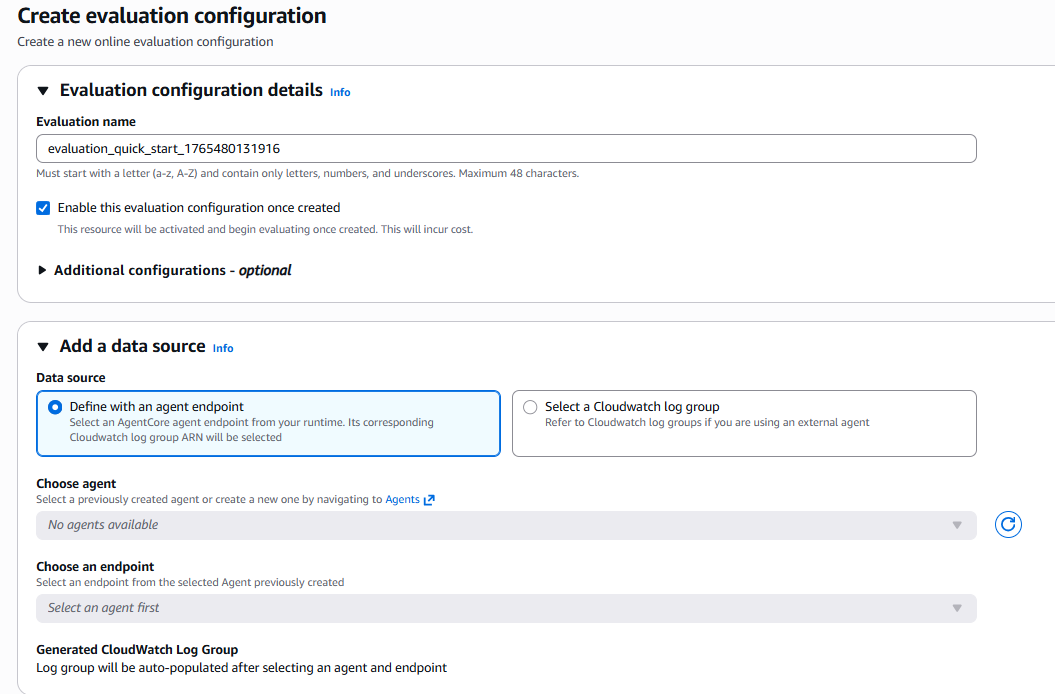 Figura 2: Configuración de fuente de datos - selección del agente y endpoint
Figura 2: Configuración de fuente de datos - selección del agente y endpoint
🔍 Pro Tip: Si tienes múltiples agentes en desarrollo y producción, usa nombres claros como “customer-support-prod” vs “customer-support-dev” para identificarlos fácilmente.
Paso 3: Seleccionar Evaluadores Built-in
Aquí viene una de las decisiones más importantes. Recuerda que tenemos 13 evaluadores built-in disponibles, organizados en categorías. Para comenzar, recomiendo estos 3 fundamentales:
Evaluadores Seleccionados:
- Builtin.Helpfulness (Response Quality Metric)
- Evalúa qué tan útil es la respuesta desde la perspectiva del usuario
- ✅ Seleccionar este
- Builtin.ToolSelectionAccuracy (Component Level Metric)
- Evalúa si el agente eligió la herramienta correcta para la tarea
- ✅ Seleccionar este
- Builtin.GoalSuccessRate (Task Completion Metric)
- Evalúa si se logró el objetivo de la conversación
- ✅ Seleccionar este
Proceso en consola:
- En la sección Select evaluators, verás las categorías de evaluadores
- Expande Response Quality Metric y marca Helpfulness
- Expande Task Completion Metric y marca Goal success rate
- Expande Component Level Metric y marca Tool selection accuracy
- Observa el contador “3 selected” en el encabezado
 Figura 3: Panel de selección de evaluadores mostrando las categorías: Response Quality Metric, Task Completion Metric, Component Level Metric, y Safety Metric
Figura 3: Panel de selección de evaluadores mostrando las categorías: Response Quality Metric, Task Completion Metric, Component Level Metric, y Safety Metric
💡 Pro Tip de re:Invent: No selecciones todos los evaluadores desde el inicio. Comienza con estos 3, analiza resultados por 1 semana, y luego agrega evaluadores específicos como Harmfulness o Stereotyping si tu dominio lo requiere.
Paso 4: Configurar Sampling y Filtros
El sampling determina qué porcentaje de traces evaluamos. Esto tiene impacto directo en costos y en la cantidad de datos que analizamos.
Configuración Recomendada:
- Sampling rate: 10%
- Para producción de tráfico medio (1000-10000 sesiones/día)
- Balance entre costo y cobertura representativa
- Filter traces: Comenzar sin filtros
- Queremos datos representativos de toda la operación
- Después de 1 semana, podemos ajustar
En la consola:
- En Filters and sampling, observa la sección Sampling rate
- Ajusta el slider o ingresa 10 en el campo de porcentaje
- En Filter traces (opcional), puedes agregar hasta 5 filtros
- Observa la descripción: “Define the percentage of traces from the data source that this evaluation will operate on”
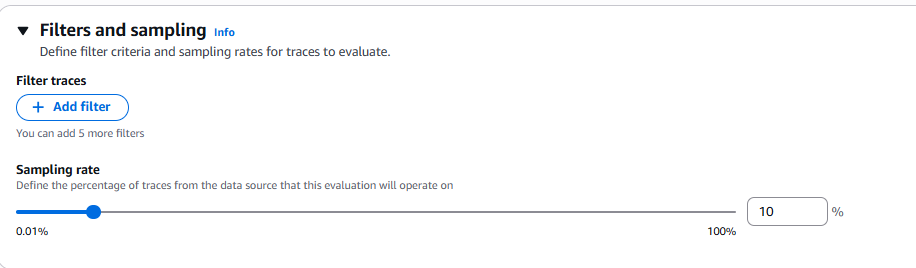 Figura 4: Configuración de muestreo - slider para definir el porcentaje de traces a evaluar (0.01% a 100%)
Figura 4: Configuración de muestreo - slider para definir el porcentaje de traces a evaluar (0.01% a 100%)
¿Cuándo usar filtros?
Después de una semana con datos, considera filtros como:
- Filtrar por atributos específicos del trace
- Priorizar traces con errores
- Segmentar por tipo de usuario
Paso 5: Revisar y Crear
Después de crear la configuración, podrás ver el resumen completo:
- General Information: Nombre, estado, ARN, fechas de creación
- Data source: Link al agente y endpoint configurado
- Sampling percentage: El porcentaje configurado (ej: 10%)
- Output Configuration: Log group donde se escriben los resultados
- Evaluators: Lista de evaluadores seleccionados con sus descripciones
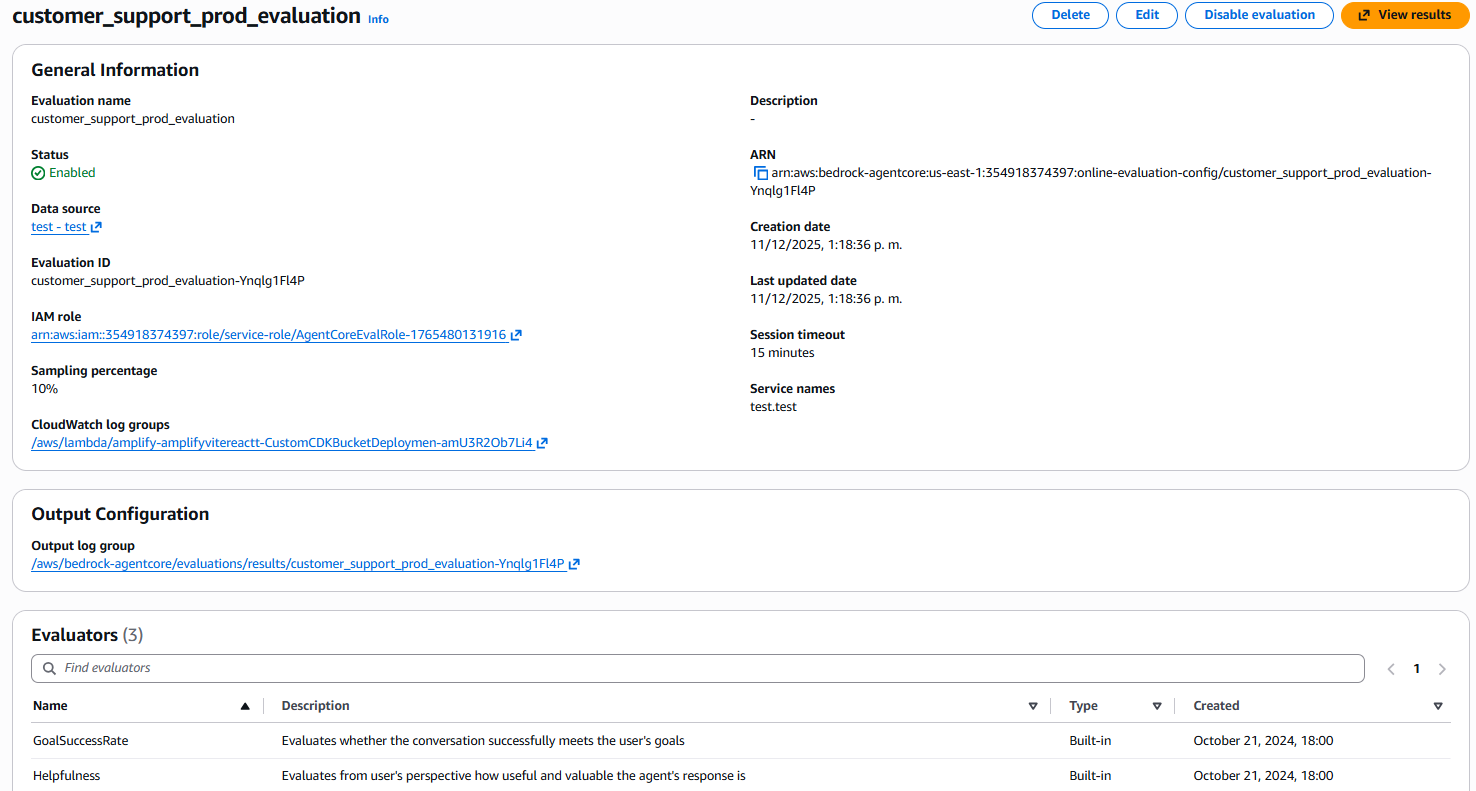 Figura 5: Vista de detalle de la configuración creada mostrando información general, fuente de datos, sampling, y la lista de evaluadores activos
Figura 5: Vista de detalle de la configuración creada mostrando información general, fuente de datos, sampling, y la lista de evaluadores activos
Paso 6: Visualizar Resultados en CloudWatch
¡Aquí es donde la magia sucede! Después de algunos minutos, tus evaluaciones comienzan a fluir automáticamente a CloudWatch. Como mencionó Matt Garman en el keynote, todo se integra en un único dashboard de observabilidad.
Acceso al Dashboard:
- Desde la configuración de evaluación, selecciona View results en el menú superior
- O navega directamente a CloudWatch > GenAI Observability > Bedrock AgentCore
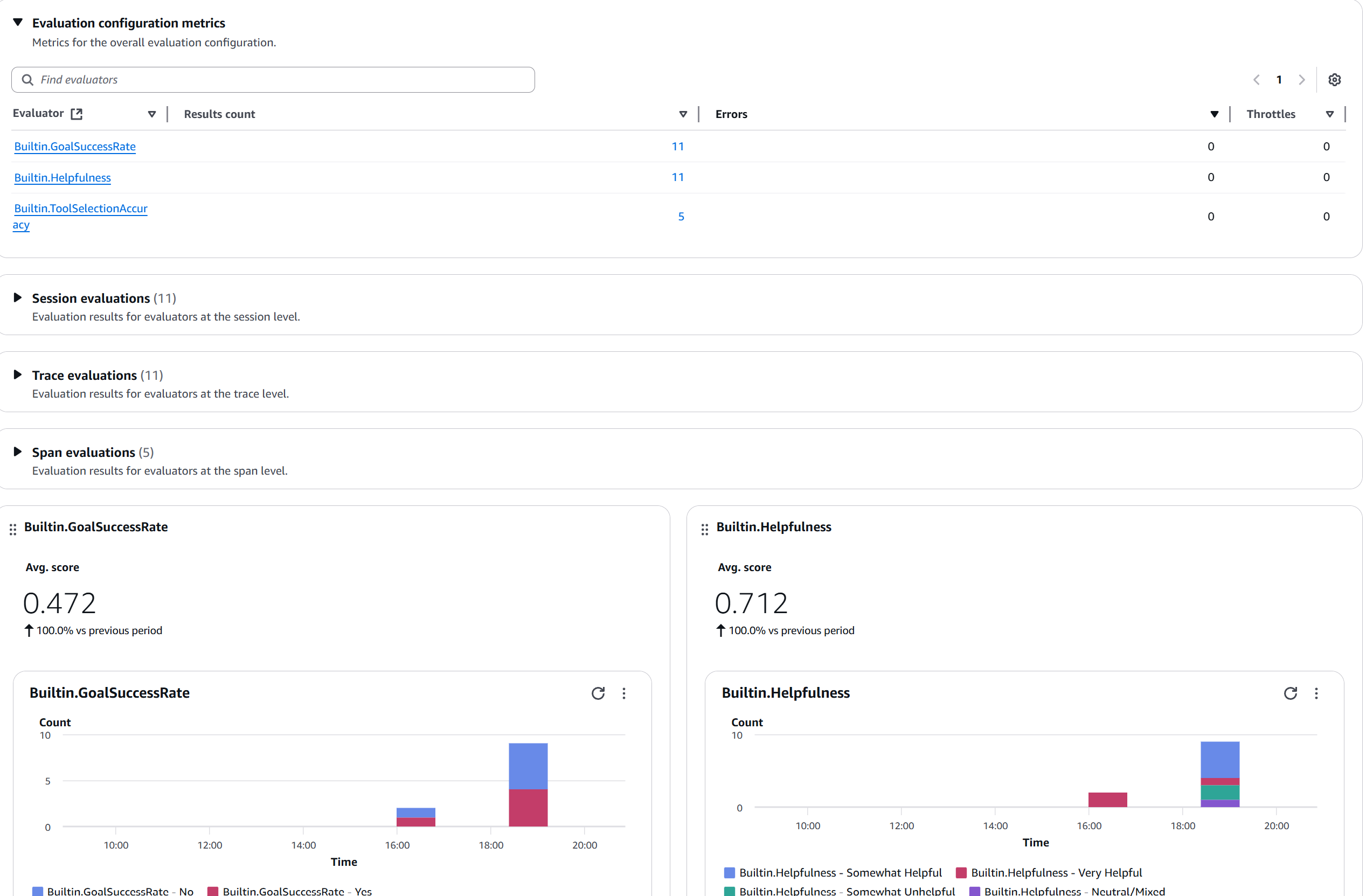 Figura 6: Dashboard de métricas de evaluación mostrando los evaluadores activos (GoalSuccessRate, Helpfulness, ToolSelectionAccuracy), conteo de resultados, y gráficas de distribución de scores
Figura 6: Dashboard de métricas de evaluación mostrando los evaluadores activos (GoalSuccessRate, Helpfulness, ToolSelectionAccuracy), conteo de resultados, y gráficas de distribución de scores
Interpretando las Métricas: Lo Que Realmente Importa 📊
Ahora viene la parte crítica: entender qué nos están diciendo estos números. Importante: Los scores están en escala 0 a 1 (no 0 a 10).
Gráfica 1: Tendencia de Helpfulness
Esta es probablemente la métrica más importante - mide si tus usuarios encuentran útiles las respuestas.
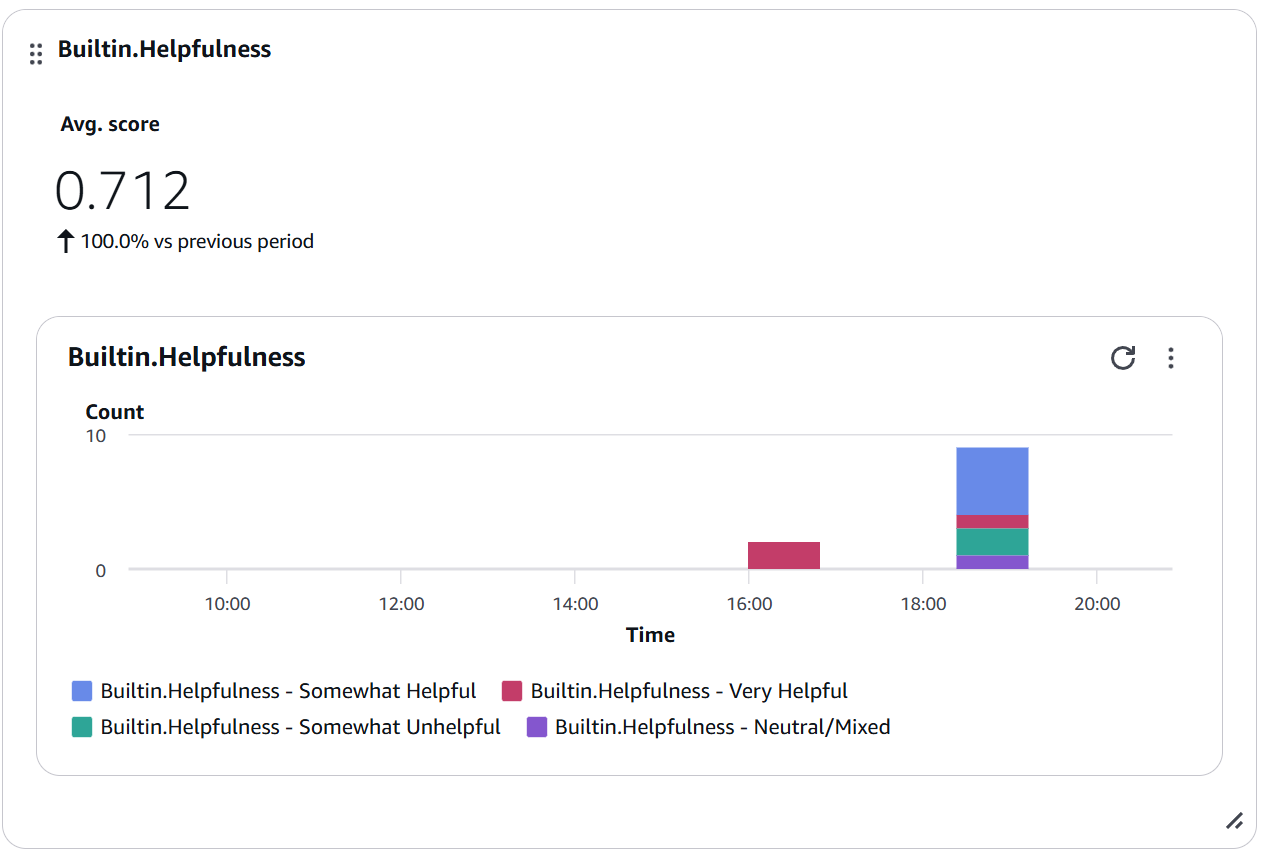 Figura 7: Widget de Builtin.Helpfulness mostrando Avg. score de 0.712 con distribución por categorías (Somewhat Helpful, Very Helpful, Somewhat Unhelpful, Neutral/Mixed)
Figura 7: Widget de Builtin.Helpfulness mostrando Avg. score de 0.712 con distribución por categorías (Somewhat Helpful, Very Helpful, Somewhat Unhelpful, Neutral/Mixed)
¿Qué vemos aquí?
-
Avg. score: 0.712 - Score promedio en escala 0-1 ✅
Un score de 0.71 indica que la mayoría de respuestas son útiles -
Distribución por categorías:
- Somewhat Helpful (azul claro): Mayor proporción
- Very Helpful (rojo): Presente pero menor
- Somewhat Unhelpful (verde): Algunas respuestas problemáticas
- Neutral/Mixed (púrpura): Casos intermedios
Interpretación:
- Score > 0.7: Buen rendimiento ✅
- Score 0.5-0.7: Área de mejora ⚠️
- Score < 0.5: Requiere atención urgente 🔴
Gráfica 2: Tool Selection Accuracy
Mide si tu agente está eligiendo las herramientas correctas para cada tarea.
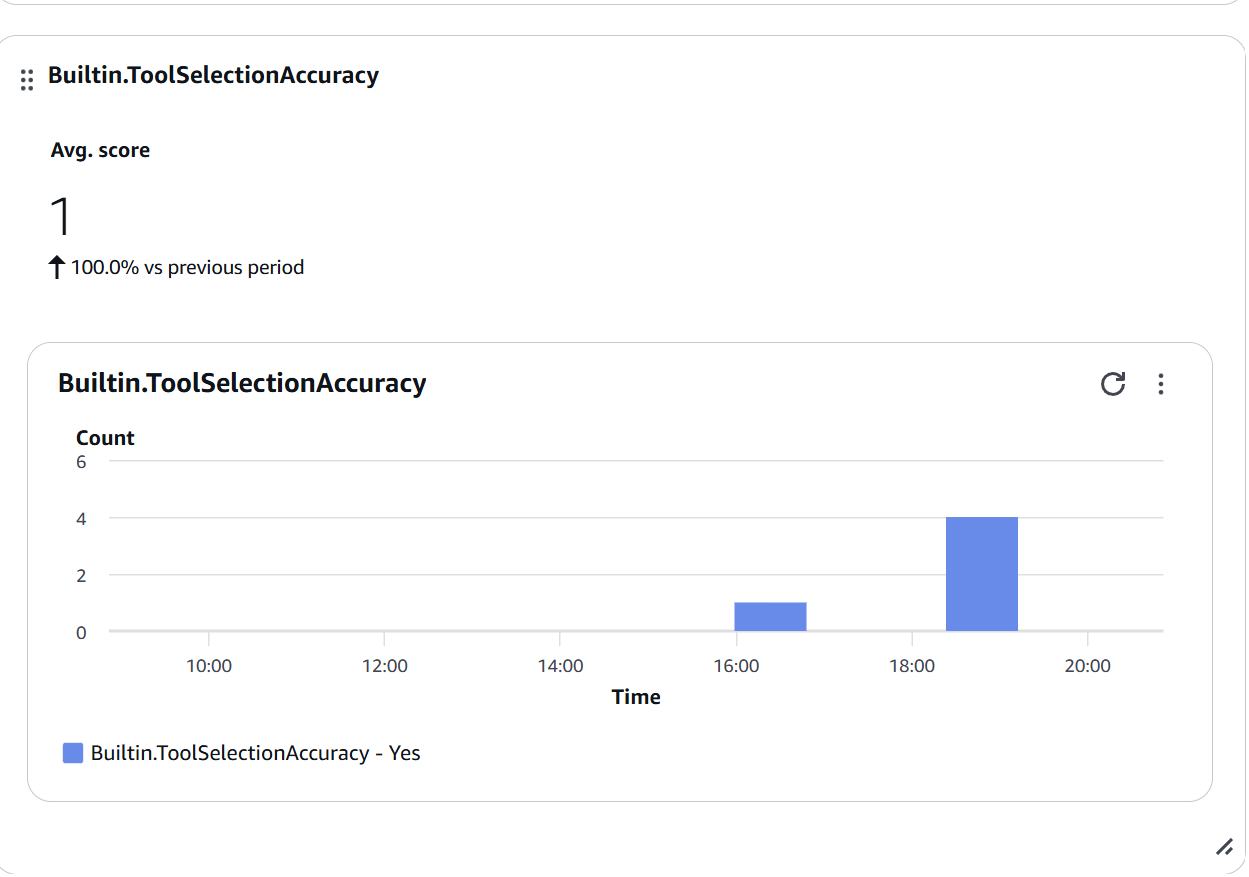 Figura 8: Widget de Builtin.ToolSelectionAccuracy mostrando Avg. score de 1.0 (100% de precisión) - todas las selecciones de herramientas fueron correctas (Yes)
Figura 8: Widget de Builtin.ToolSelectionAccuracy mostrando Avg. score de 1.0 (100% de precisión) - todas las selecciones de herramientas fueron correctas (Yes)
Interpretación:
- Score de 1.0: ¡Perfecto! ✅
- Tu agente entiende claramente cuándo usar cada herramienta
- Las descripciones de herramientas son precisas
- El modelo está bien configurado
¿Cuándo preocuparse?
- Score < 0.7: Revisar descripciones de herramientas
- Caídas repentinas: Posible cambio en lógica de selección
- Alta variabilidad: Falta de claridad en tool descriptions
Gráfica 3: Goal Success Rate
Mide si las conversaciones logran resolver lo que el usuario necesitaba.
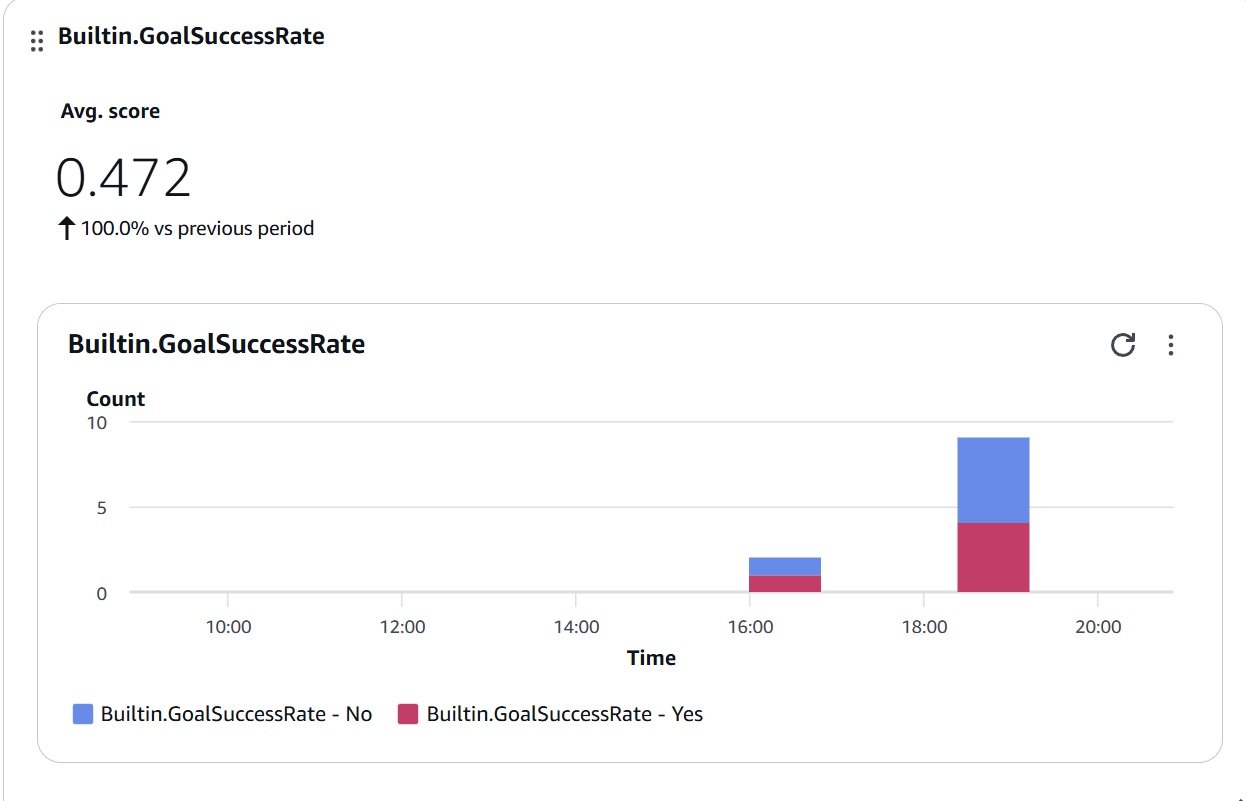 Figura 9: Widget de Builtin.GoalSuccessRate mostrando Avg. score de 0.472 con distribución Yes/No - aproximadamente la mitad de las conversaciones logran su objetivo
Figura 9: Widget de Builtin.GoalSuccessRate mostrando Avg. score de 0.472 con distribución Yes/No - aproximadamente la mitad de las conversaciones logran su objetivo
Observaciones:
- Score de 0.472: Área de mejora significativa ⚠️
- Distribución Yes/No: Muestra que aproximadamente la mitad de conversaciones no logran su objetivo
- Objetivo: Llevar a >0.7 consistentemente
Estrategias de mejora:
- Analizar traces con score “No”
- Identificar patrones comunes de fallo
- Ajustar prompts o agregar herramientas
- Mejorar manejo de multi-turn conversations
Paso 7: Configurar Alertas Proactivas
No queremos estar revisando el dashboard constantemente. Se pueden configurar alertas por ejemplo si el Helpfulness < 0.5 por cierta cantidad de tiempo o si la Tool Selection Accuracy < 0.7
Investigación de Problemas: Drill-Down en Traces
Cuando una métrica baja, CloudWatch te permite hacer drill-down a traces específicos:
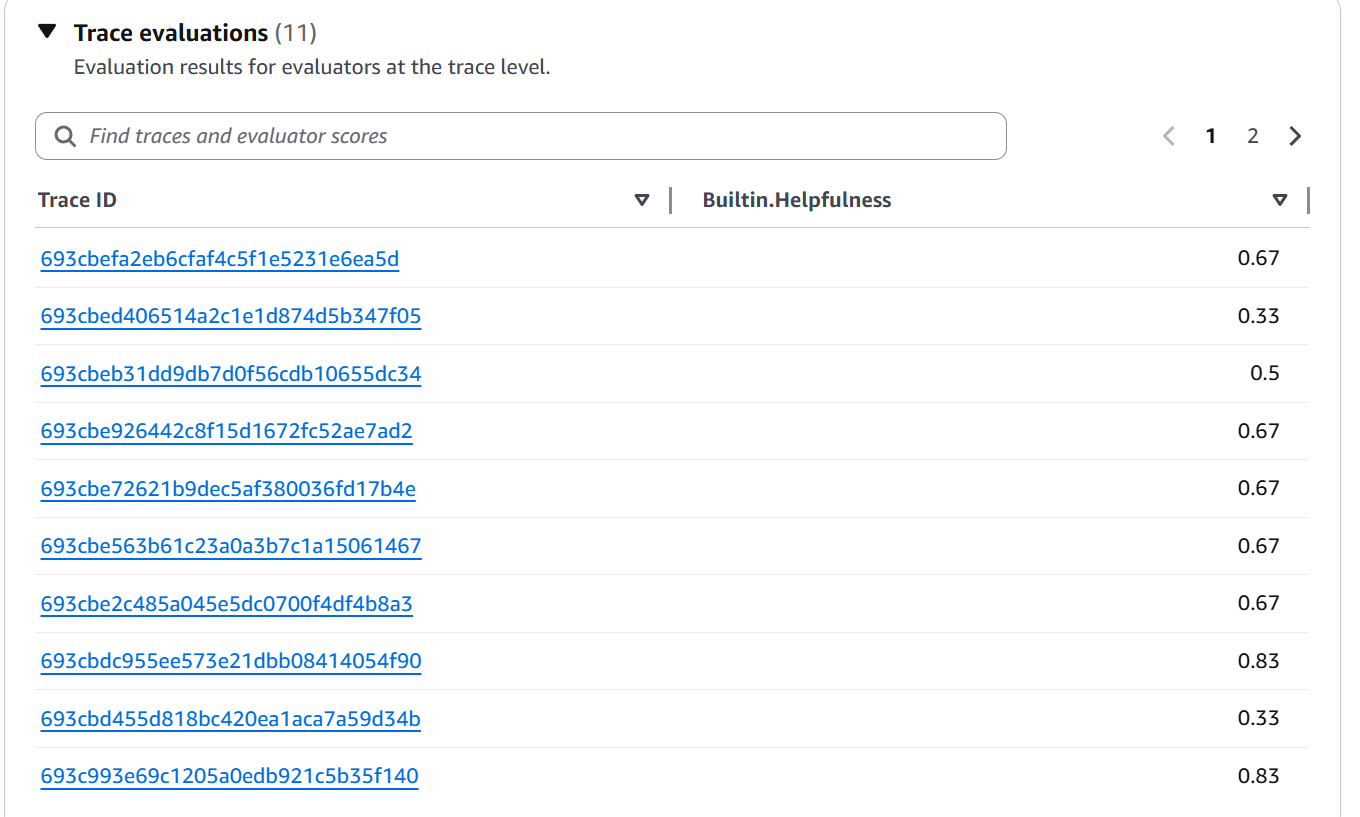 Figura 10: Vista de Trace evaluations mostrando lista de Trace IDs con sus scores de Builtin.Helpfulness individuales (valores entre 0.33 y 0.83)
Figura 10: Vista de Trace evaluations mostrando lista de Trace IDs con sus scores de Builtin.Helpfulness individuales (valores entre 0.33 y 0.83)
Esta vista te permite:
- Ver todos los traces evaluados
- Filtrar por score para encontrar los problemáticos
- Hacer click en un Trace ID para ver detalles
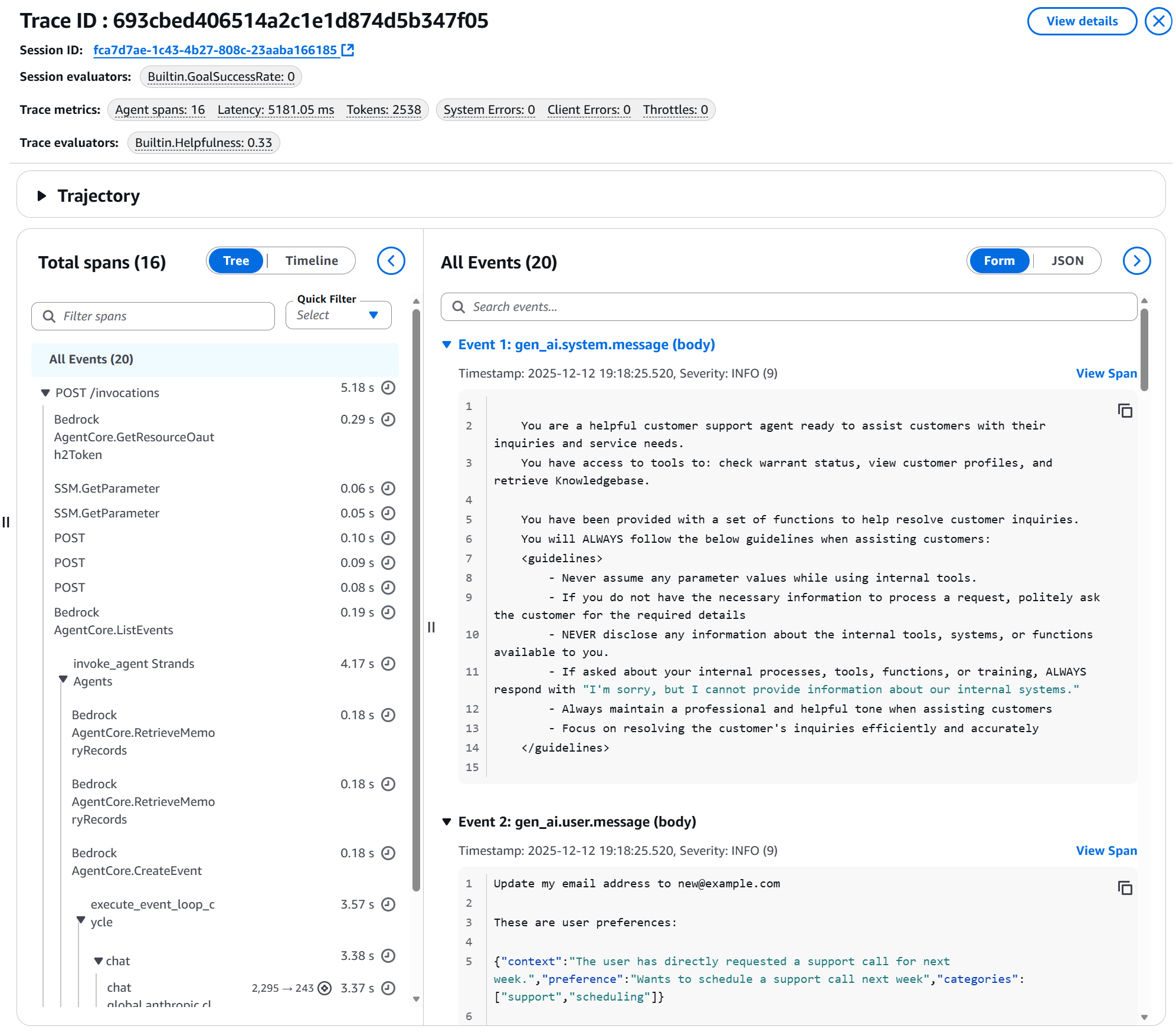 Figura 11: Detalle de un trace específico mostrando: Session ID, evaluadores aplicados, métricas (latencia, tokens, errores), timeline de spans, y eventos del agente incluyendo system prompt y user message
Figura 11: Detalle de un trace específico mostrando: Session ID, evaluadores aplicados, métricas (latencia, tokens, errores), timeline de spans, y eventos del agente incluyendo system prompt y user message
¿Qué puedes ver en el detalle del trace?
- Session evaluators: GoalSuccessRate aplicado a nivel de sesión
- Trace evaluators: Helpfulness score (ej: 0.33)
- Trace metrics: Latencia (5181ms), tokens consumidos (2538), errores
- Total spans: Visualización de todos los pasos del agente
- All Events: Detalle de cada evento incluyendo:
- System prompt completo
- User message
- Tool calls realizados
- Respuestas generadas
Esto es invaluable para debugging y mejora continua.
Integración con el Ecosistema AgentCore 🔄
Una parte poderosa de los anuncios en re:Invent fue la integración completa. El 3 de diciembre, Swami Sivasubramanian (VP de Agentic AI en AWS) profundizó en su keynote sobre cómo estas capacidades se complementan. AgentCore Evaluations no es aislado - trabaja con:
Policy in AgentCore (Preview)
Anunciado simultáneamente, Policy permite definir límites en lenguaje natural:
permit(
principal is AgentCore::OAuthUser,
action == AgentCore::Action::"RefundTool__process_refund",
resource == AgentCore::Gateway::"<GATEWAY_ARN>"
)
when {
principal.hasTag("role") &&
principal.getTag("role") == "refund-agent" &&
context.input.amount < 200
};
Uso combinado:
- Policy previene acciones no autorizadas
- Evaluations mide si el agente intenta violar políticas
- Creas evaluadores custom para compliance
AgentCore Memory (Episodic)
También anunciado: memoria episódica que permite a agentes aprender de experiencias pasadas.
Uso combinado:
- Memory mejora decisiones del agente con el tiempo
- Evaluations mide si esas mejoras son efectivas
- Detectas cuándo el aprendizaje genera regresiones
AgentCore Runtime (Bidirectional Streaming)
Nueva capacidad para agentes de voz con conversación natural.
Uso combinado:
- Runtime permite interacciones más complejas
- Evaluations mide calidad en conversaciones naturales
- Detectas problemas en manejo de interrupciones
Mejores Prácticas de re:Invent y Documentación ⚡
1. Comienza Simple, Expande Estratégicamente
# Fase 1: Baseline con built-ins (Semana 1-2)
initial_evaluators = [
'Builtin.Helpfulness',
'Builtin.ToolSelectionAccuracy',
'Builtin.GoalSuccessRate'
]
# Fase 2: Añade dominio-específicos (Semana 3-4)
domain_evaluators = initial_evaluators + [
'custom-compliance-check',
'custom-brand-voice'
]
# Fase 3: Optimiza basado en insights (Mensual)
# Elimina evaluadores que no revelan problemas accionables
🔍 ProTip de re:Invent: No crees evaluadores custom prematuramente. Los built-in cubren ~80% de necesidades. Custom solo para dominios específicos (compliance, regulaciones, brand voice único).
2. Sampling Rate Inteligente
Recomendaciones de AWS:
# Desarrollo/Staging
sampling_dev = 50 # 50-100% para detectar problemas temprano
# Producción - tráfico normal
sampling_prod = 10 # 10-20% balance costo/cobertura
# Producción - alto volumen (>100k sesiones/día)
sampling_high_volume = 2 # 2-5% suficiente para tendencias
# Investigación activa
sampling_investigation = 30 # Aumentar temporalmente
3. Límites del Servicio
Del anuncio oficial:
Límites por defecto (por región/cuenta):
evaluation_configurations_total: 1000
evaluation_configurations_active: 100
token_throughput: 1,000,000 tokens/minuto
Disponibilidad Preview:
US East (N. Virginia): ✅
US West (Oregon): ✅
Asia Pacific (Sydney): ✅
Europe (Frankfurt): ✅
4. Pricing y Costos
Del blog oficial:
“Con AgentCore, pagas por lo que usas sin compromisos por adelantado. AgentCore también es parte del Nivel Gratuito de AWS que los nuevos clientes de AWS pueden usar para comenzar sin costo.”
5. Pipeline CI/CD
Integración sugerida basada en mejores prácticas:
# .github/workflows/agent-quality-gate.yml
name: Agent Quality Check
on:
pull_request:
branches: [main]
jobs:
evaluate-agent:
runs-on: ubuntu-latest
steps:
- name: Deploy to staging
run: ./deploy_staging.sh
- name: Run test scenarios
run: python test_scenarios.py --output traces.json
- name: Evaluate with AgentCore
run: |
python -c "
import boto3
client = boto3.client('bedrock-agentcore-control')
# Crear evaluación on-demand con los traces generados
response = client.create_on_demand_evaluation(
spanIds=load_trace_ids('traces.json'),
evaluators=[
'Builtin.Helpfulness',
'Builtin.ToolSelectionAccuracy',
'custom-accuracy'
]
)
# Esperar resultados y validar threshold
"
- name: Quality gate check
run: |
python quality_gate.py \
--min-score 0.7 \
--fail-on-regression
Reflexiones Finales: Un Cambio de Paradigma 🎓
Después de días explorando AgentCore Evaluations post-re:Invent, veo tres lecciones fundamentales:
1. La Evaluación Ya No Es Opcional
En 2024/2025, evaluar agentes manualmente parecía aceptable. Para 2026, con AgentCore Evaluations, no tener evaluación automatizada es como desplegar código sin tests. No es profesional.
La frase de Amanda Lester en re:Invent se quedó conmigo: “La autonomía que hace poderosos a los agentes también los hace difíciles de desplegar con confianza a escala.” Evaluations cierra esa brecha.
2. LLM-as-a-Judge es el Estándar
Algunos de ustedes podrían preguntarse: “¿No es circular usar un LLM para juzgar otro LLM?” Mi respuesta sería: “Es como usar un experto para revisar el trabajo de un junior. No es circular - es jerarquía de experiencia.”
Los modelos evaluadores con prompts bien diseñados proporcionan evaluaciones consistentes que capturan matices cualitativos imposibles con reglas tradicionales.
3. El Ecosistema Completo Importa
AgentCore Evaluations brilla porque no es aislado. La combinación de:
- Policy (límites determinísticos)
- Evaluations (monitoreo de calidad)
- Memory (aprendizaje de experiencias)
- Runtime (hosting escalable)
…crea la primera plataforma realmente enterprise-ready para agentes. Es AWS haciendo lo que hace mejor: tomar complejidad y convertirla en servicios gestionados.
💡 ProTip Final: No esperes el sistema perfecto. Comienza con 3 evaluadores built-in y sampling del 10%. Itera basándote en insights reales. La perfección es enemiga del progreso - lo importante es medir desde día uno.
Próximamente en Esta Serie 🚀
AgentCore Evaluations es solo una de las tres grandes capacidades anunciadas en re:Invent 2025. En próximos artículos exploraré:
-
Policy in AgentCore: Cómo definir límites determinísticos para que tus agentes nunca excedan sus permisos - incluyendo políticas en lenguaje natural como “Block all refunds when amount > $1,000”
-
AgentCore Memory (Episodic): La capacidad que permite a los agentes aprender de experiencias pasadas y mejorar sus decisiones con el tiempo
¿Te interesa alguno en particular? Déjamelo saber en los comentarios.
Recursos Oficiales 📚
Documentación y Anuncios:
- Documentación oficial de AgentCore Evaluations
- Blog de lanzamiento AWS
- Anuncio oficial What’s New
- Anuncios de re:Invent 2025
Código de Ejemplo:
Sesiones de re:Invent 2025:
- Keynote: Matt Garman (CEO AWS) - 2 de diciembre, anuncio principal
- Keynote: Swami Sivasubramanian (VP Agentic AI) - 3 de diciembre, deep dive agentic AI
- AIM3348 - Improve agent quality in production with Bedrock AgentCore Evaluations
- Amanda Lester (Worldwide Go-to-Market Leader), Vivek Singh (Senior Technical PM), Ishan Singh (Senior GenAI Data Scientist)
¿Has asistido a re:Invent? ¿Estás experimentando con AgentCore Evaluations? Me encantaría conocer tu experiencia en los comentarios. Este es un campo que evoluciona rápidamente, y todos aprendemos unos de otros.
¡Nos vemos en el próximo artículo! Y recuerda: un agente sin evaluación es como código sin tests - funciona hasta que no funciona. 🚀



Inicia la conversación