

Tabla de Contenidos
Al desarrollar aplicaciones orientadas a microservicios es responsabilidad del arquitecto de software a cargo explicarle al equipo de desarrollo como debe construirlos, de manera que sean tolerantes a fallas.
En este artículo les hablaré sobre las causas por las que es importante tomar esto en cuenta, algunas de las razones por las que un sistema puede fallar y cuales patrones de estabilidad es importante que se conozcan y se empleen.
Historia
Empecemos con un poco de historia. Hace cerca de 25 años, Peter Deutsch junto a otras personas en Sun Microsystem realizaron un estudio sobre las falacias de la computación distribuida que todos los programadores nuevos inevitablemente hacian al construir aplicaciones de esta índole. Y que cito seguidamente:
- La red es confiable.
- La latencia es cero.
- El ancho de banda es infinito.
- La red es segura.
- La topología no cambia.
- El costo de transporte es cero.
- La red es homogénea.
Elaboremos un poco al respecto, si las aplicaciones que creamos tienen poco o escaso manejo de errores de red, durante momentos en que la misma tenga problemas nuestros sistemas pueden ‘pegarse’ o quedarse esperando de manera indefinida paquetes que nunca llegarán, consumiendo memoria u otros recursos. Más aún, es probable que cuando la red se restaure la aplicación sea incapaz de recuperarse y requiera de un reinicio completo.
Mi experiencia me dice que hoy en día, muchos programadores que confían en REST para comunicarse en un sistema distribuido caen en estas falacias. Y más aún, una característica importante de REST es que no oculta las limitaciones de la red.
Ante esto, existen varios patrones de estabilidad que podemos incorporar en nuestros desarrollos. En este artículo abordaré tres de ellos.
Patrones de Estabilidad
Un patrón de estabilidad lo que busca es promover la resiliencia en un sistema distribuido.
Pero ¿qué es resiliencia?
“Capacidad de un sistema tecnológico de soportar y recuperarse ante desastres y perturbaciones.”
Veamos el siguiente ejemplo de un sistema que consta de varios microservicios. Existe un componente de facturación que invoca un servicio para validar una identificación.
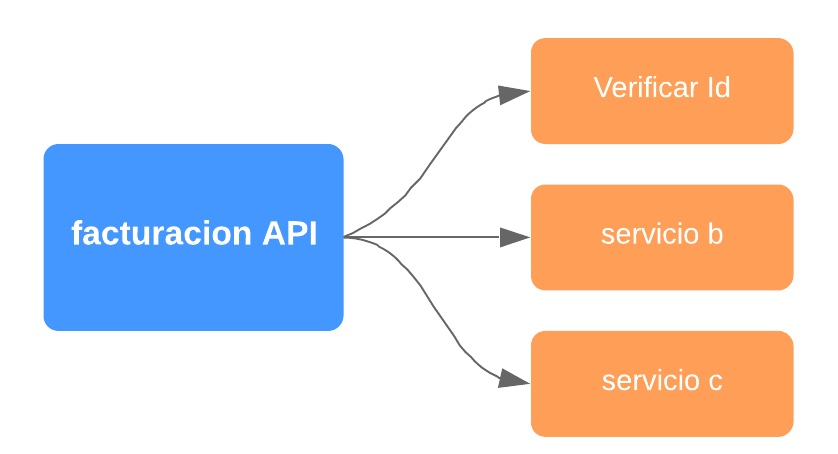
Por un tiempo todo marcha perfectamente, pero de repente el aplicativo se comienza a degradar y exhibe tiempos de respuesta muy lentos hasta que finalmente se debe reiniciar todo el aplicativo. Al indagar dentro de los logs el equipo de desarrollo determinar que el problema era un microservicio de validación de historial. Este servicio se consume sólo en casos muy particulares.
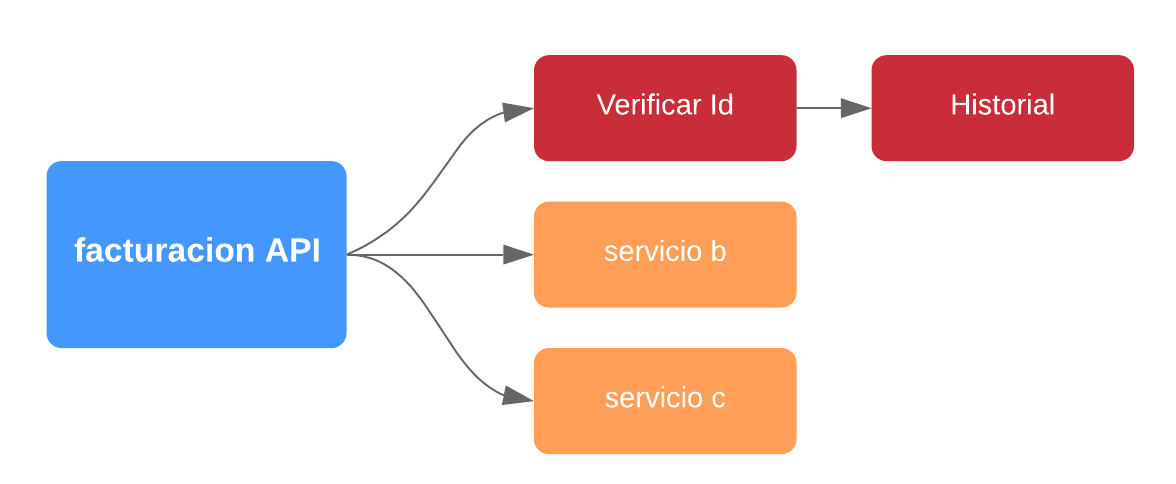
Acá tenemos un ejemplo de como un servicio que se emplea rara vez y que no es crítico (como el historial) termina por afecta algo que si lo es. Y esto es lo que se conoce como una falla en cascada.
Por tanto, debemos prevenir está falla a futuro.
¿Cómo podemos lograrlo?
Inicialmente uno podría pensar que puede hacer varias cosas, a manera de ilustración:
- Agregar más redundancia en componentes.
- Hacer más pruebas.
Code Reviewsadicionales.- Agregar más servidores.
Y supongamos que logramos tener una disponibilidad del 99.999%. Eso es grandioso! quiere decir que en un año tenemos apenas 5 minutos en que nuestro servicio esta fuera de línea.
Pero ¿qué pasa si tenemos 1,000 microservicios?
En tal caso nuestra disponibilidad pasaría a ser:
0.999991000 = 0.99%
Lo que corresponde a 87 horas al año y eso evidentemente sería inaceptable. Entonces debemos evitar que las fallas en cascada se den sin control. Y además considerar que hay que:
“Diseñar para las Fallas”
¿Porqué? Por qué hay demasiadas partes en movimiento y debemos suponer que a pesar de todos nuestros mejores esfuerzos las fallas inevitablemente se van a dar.
Anatomía de la Falla
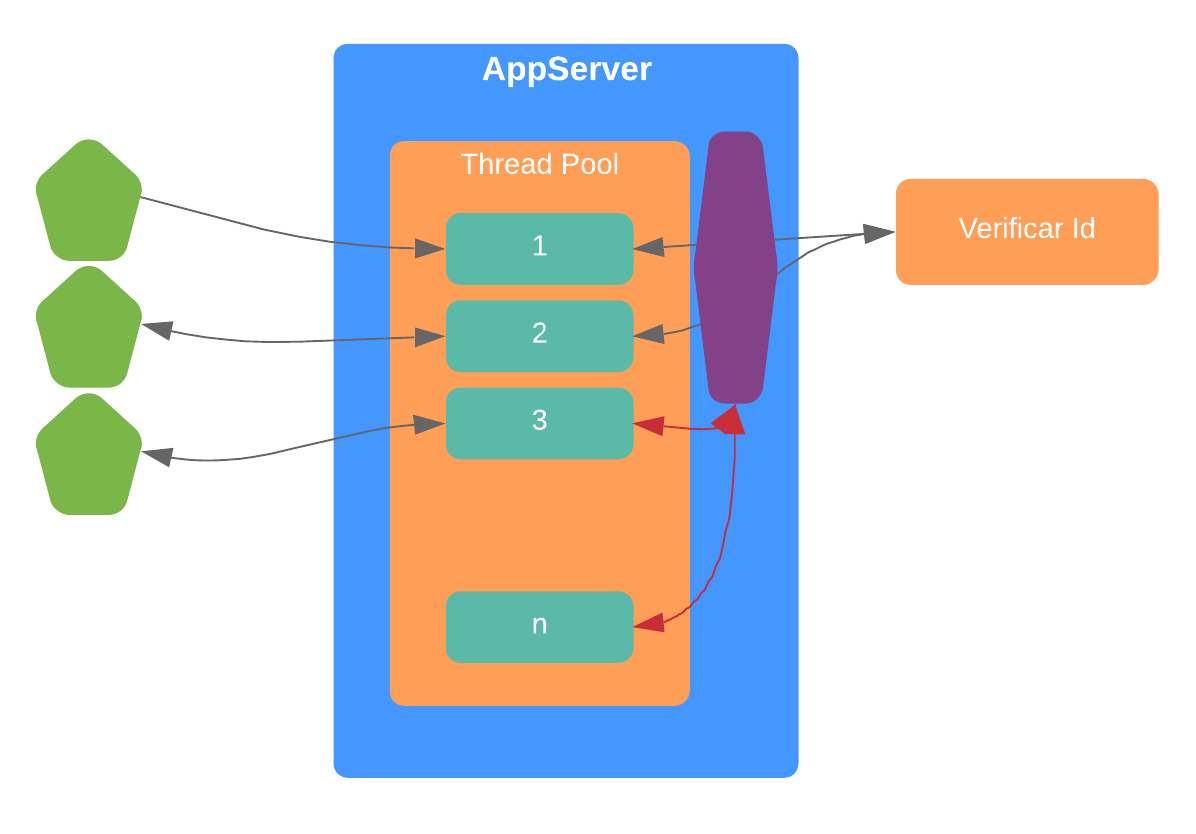
Si consideramos nuestro ejemplo anterior, a nivel de un servidor de aplicaciones JEE, lo que sucede es lo siguiente:
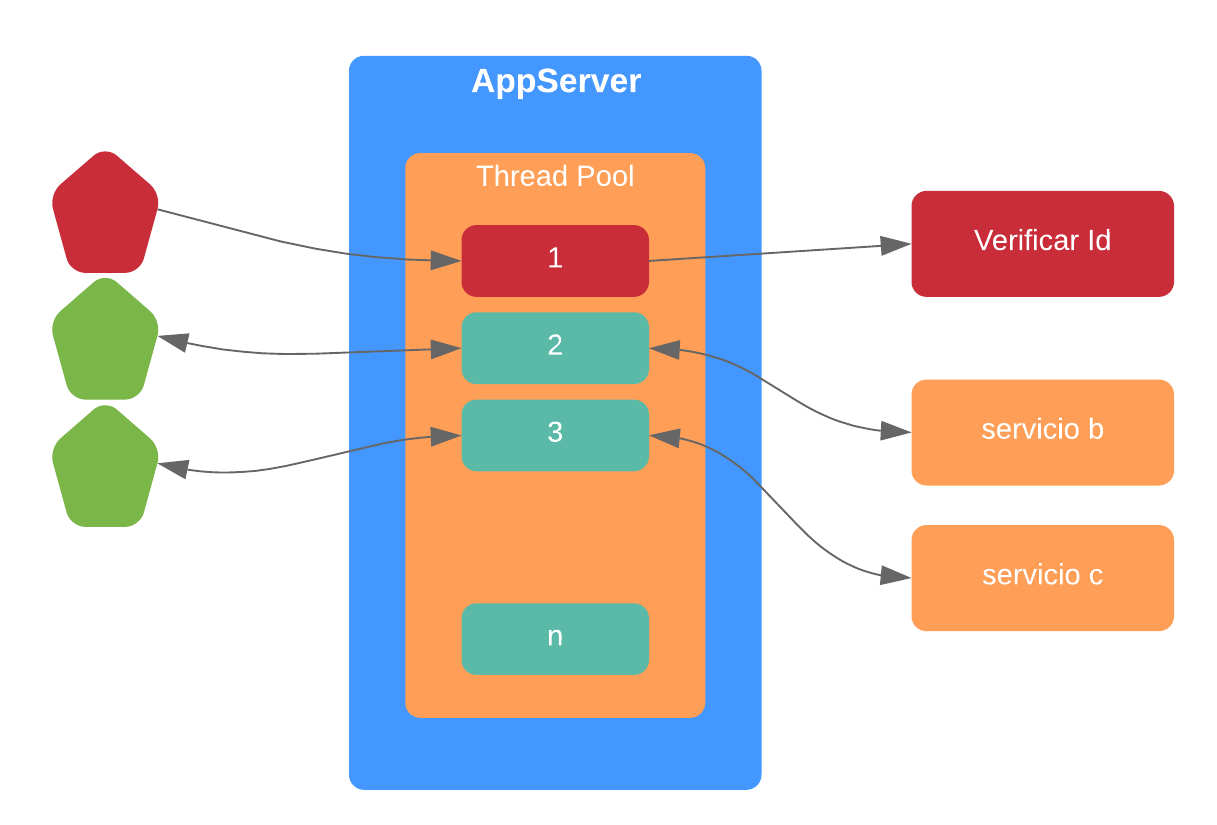
Tenemos un thread pool finito el cual es el que realiza -al final de cuentas- el trabajo que necesitamos. Cada vez que uno de ellos invoca al microservicio de ‘verificación’ queda en espera, bloqueado, y no puede atender nuevas peticiones. Y esto eventualmente desemboca en que la totalidad de threads están bloqueados y peor aún, se genera una cola de peticiones; tal y como se ilustra seguidamente.
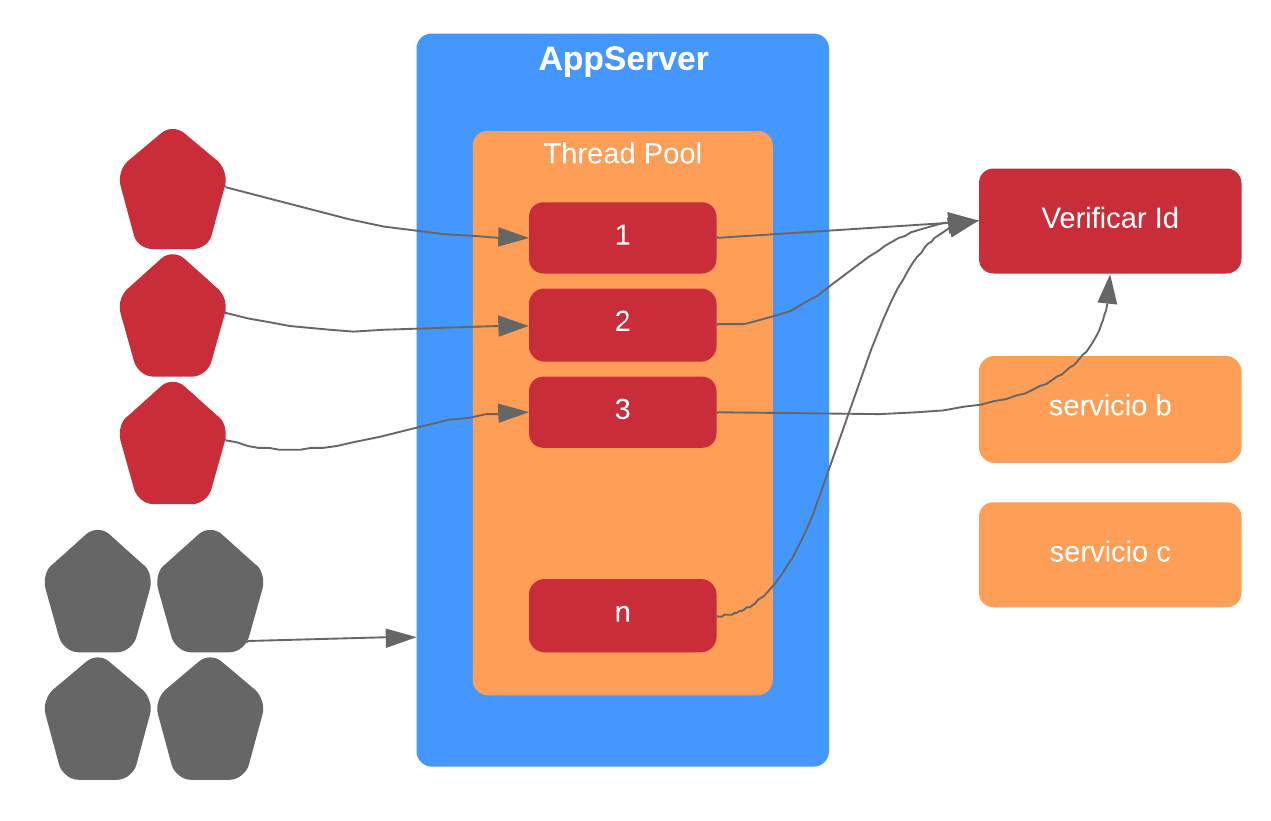
TimeOuts
Este primer patrón lo que nos permite es prevenir que los threads queden ‘bloqueados’. Una vez que se dispará el timeout, ese thread puede hacer otra cosa.
Veamos el siguiente extracto de código:
Client client = ClientBuilder.newClient();
WebTarget target = client.target(VALIDAR_URI).path(“check");
Invocation.Builder request = target.request();
¿Qué sucede si algo malo le ocurre a ese WS que consumimos?
Aquí es cuando debemos tomar en consideración que la tecnología fundamental para la comunicación es TCP/IP. Se preguntarán ¿cuál es el tiempo razonable para un timeout? La respuesta es que depende de su proveedor de JAX-RS. Si usamos Jersey, internamente utiliza HttpURLConnection y su timeout es 0 milisegundos.
¿Qué significa un timeout de 0 milisegundos? Lo que significa es espera infinita y eso es muy mala noticia, pues entonces ese thread se quedará bloqueado de manera infinita.
En JAX-RS 2 no hay una manera estandar de definir los timeouts, así que en el caso específico de Jersey sería así:
Client client = ClientBuilder.newClient();
client.property(ClientProperties.CONNECT_TIMEOUT, 2000);
client.property(ClientProperties.READ_TIMEOUT, 2000);
WebTarget target = client.target(VALIDAR_URI).path(“check");
Invocation.Builder request = target.request();
Algo que es importante de tomar en cuenta es que el tiempo que definamos debe ser agresivo. Es mucho mejor que algo responda en 0.5 segundos a que responda en 5 segundos. Si definimos esos tiempos de manera correcta será menos probable que lleguemos a tener bloqueos.
Además, los timeouts debemos establecerlos entre todos los participes. Es decir, si nuestro WS llama a otro WS, también debemos establecer su respectivo timeout.
Supongamos entonces que en nuestro sistema ya implementamos este patrón de estabilidad y todo marcha bien. Hasta que llega el día en que de nuevo nuestra aplicación comienza a tener un comportamiento degradado, el sistema se pone lento, hay encolamiento y eventualmente todo se cae.
Haciendo un análisis el equipo de desarrollo se da cuenta que un microservicio que antes se llamaba rara vez, ahora es llamado constantente desde la página principal de nuestro sistema. Y esto nos lleva a una conclusión importante:
“Si un servicio se llama frecuentemente, entonces los timeouts son insuficientes.”
Circuit Breakers
La situación previamente descrita nos llevan a este nuevo patrón de estabilidad. Este patrón es más proactivo, ya que al detectar una falla previene que una aplicación intente una acción que esta destinada al fracaso. En resumen, evita que sigamos enviandole carga a un servicio que tiene fallas y esto se logra decorando y monitoreando una llamada protegida a una función.
En detalle, un circuit breaker posee tres estados:
- Cerrado. Este es el estado inicial, las llamadas al WS destino son permitidas y se guardan métricas necesarias para implementar una política de salud.
- Abierto. Si se detecta una falla, todas las llamadas posteriores son rechazadas de manera inmediata. Esto da la posibilidad de que el servicio que esta atrás se recupere o se rectifique el problema.
- Semi abierto. Una vez que ha pasado un periodo de tiempo, se hacen ejecuciones ocasionales para determinar si el servicio se ha recuperado y de ser así, nuevamente se cierra el circuito.
Es importante tomar nota que podemos manejar elementos como:
- Timeouts sobre cierto umbral. Si tenemos un x% de timeouts, abrimos el circuito.
- Errores no manejados sobre cierto umbral. Si tenemos un x% de errores no manejados, abrimos el circuito.
- Errores conocidos que sabemos no son recuperables. Por ejemplo: si sabemos que un error es una falla seria en la base de datos, podemos abrir el circuito inmediatamente.
De igual manera, debemos considerar devolver valores por omisión en caso de problemas para evitar posteriores errores de tipo 50x. A manera de ilustración: si el WS que trae nuestro historial de compras está caído, podemos regresar una lista vacia de compras.
Una manera de implementar este patrón en JAX-RS es por medio de un filtro.
client.register(new CircuitBreakerFilter());
public class CircuitBreakerFilter implements ClientRequestFilter,
ClientResponseFilter
Este filtro implementa un metodo pre-exec y un post-exec. En el pre el sistema valida si se permite la ejecución, de permitirse se almacenan métricas de ejecución y en el post se determina si hay un error (por ejemplo un código de status 50x).
Con esas métricas se puede establecer una politica de salud y obtener datos como la tasa de éxito y fallos de los llamados y así determinar si el circuito se abre o no.
“Este patrón debe aplicarse tanto del lado del cliente como entre llamadas internas.”
Si deseamos usar una librería, podemos utilizar Resilience4J (cuya integración con Prometheus para métricas en producción exploro en este artículo), en cuyo caso el código resultante sería el siguiente:
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(20)
.ringBufferSizeInClosedState(5)
.build();
Hemos definido que se realizará al menos 5 llamadas al WS y que se pasará a un estado abierto tan pronto como el 20% de ellas fallen.
Nuevamente, el equipo de desarrollo ha implementando este patrón y por un tiempo todo marcha bien, hasta que de nuevo la aplicación comienza a tener un comportamiento degradado, el sistema se pone lento, hay encolamiento y eventualmente todo se cae.
El equipo analiza de nuevo la plataforma y encuentra que el problema es de nuevo nuestro microservicio de ‘verificación’, el cual responde lento; pero no lo suficiente para activar el timeout.
Entonces tenemos una situación en donde los timeouts y el circuit breaker no son suficiente.
Bulkheads
El tercer patrón del que hablaremos son ‘bulkheads’, el cuál constituye un mecanismo de particionamiento. Es decir, aisla componentes entre sí a fin de evitar que un componente afecte a otro y prevenir -por tanto- fallas en cascada. Ejemplos tradicionales de esto es:
- Tener clusters separados por tipo de cliente (ejemplo: mobile y webapp).
- Tener clusters separados por aplicación.
En nuestro caso, a nivel de código la idea fundamental es limitar el número de llamadas concurrentes a un servicio. Veamos la siguiente ilustración:
En este ejemplo, tenemos un ‘bulkhead’ en donde en el peor escenario solo tendríamos dos threads en espera y el resto de peticiones fallarían de manera inmediata. Esto nos protege cuando un servicio presenta lentitud, pero no al nivel de disparar un timeout.
Este patrón tiene varias características interesantes, pues es un excelente elemento contra fallas en cascada. Pero sólo si el tamaño del bulkhead es significativamente más pequeño que el request pool size. En caso contrario, tendríamos potencialmente a todos los threads en espera.
Además, es importante establecer un valor adecuado para el mismo, lo cual nos lleva a tomar métricas durante cargas pico de nuestro sistema y de esta manera lograr proteger a nuestro servicios ante escenarios de sobrecarga.
Dicho esto, ¿cómo podemos implementarlo? Es sencillo, empleando un semáforo. Por ejemplo:
Semaphore bulkhead = new Semaphore(2);
Validacion protectedGetValidacion() {
if (bulkead.tryAcquire(0, TimeUnit.SECONDS)) {
try {
return validador.getValidacion();
} finally {
bulkhead.release();
}
} else {
throw new RechazoPorBulkheadException();
}
Como se observa, tenemos un bulkhead de 2 espacios, si alguno está libre se adquiere el semáforo para hacer la invocación y luego se libera. Si ambos están en uso, se falla de manera inmediata.
En el caso de Resilience4J se haría lo siguiente:
BulkheadConfig config = BulkheadConfig.custom()
.maxConcurrentCalls(2).build();
Monitoreo
Como hemos visto, existe un elemento fundamental para estos tres patrones y es el monitoreo. Es necesario poder tener al menos las siguiente métricas:
- Llamadas a los servicios
- Tasa de timeouts
- Tasa de llamadas rechazadas
- Tasa de circuit break
- Tasa de éxito/fallas
- Tiempo de Respuesta
Pues todas ellas nos permiten determinar si hemos configurado de manera adecuada estos patrones y poder optimizarlos a lo largo del tiempo. Además de poder identificar un punto de falla de una manera muy rápida.
Conclusión
Esperamos que con este artículo los lectores tengan conciencia que debemos diseñar nuestros sistemas para afrontar fallas y que al menos debemos implementar algunos de estos patrones para lograr que nuestras aplicaciones sean más resilientes. Por último, el contrar con un monitoreo sobre los mismos es fundamental para poder optimizarlos y comprender como se comporta cada uno de nuestros sistemas ante diferentes cargas de trabajo. Estos principios aplican también a sistemas modernos de IA en producción; por ejemplo, Amazon Bedrock Agents orquesta llamadas a herramientas externas donde los timeouts y el manejo de fallos son igualmente críticos.
Inicia la conversación