


Tabla de Contenidos
En este artículo escribo acerca de AWS Quantum Ledger Database o QLDB. El nombre puede sonar algo complicado; pero espero que al concluir la lectura tengan una vision general de que es el servicio y cómo lo podrían incluir en otros desarrollos.
Libro Mayor
Pero antes de profundizar en el tema debemos repasar el concepto de ledger o libro mayor. Este tipo de instrumento ha sido empleado por la humanidad desde tiempo inmemoriables para documentar diferentes cosas como: nacimientos, transferencias, registros financieros y muchos más. En resumen son un registro histórico de todas las transacciones en el tiempo.
En la gran mayoría de los casos; hemos pasado de tener este tipo de registros en papel hacia tenerlos almacenados digitalmente en una base de datos relacional. Estas bases de datos se crean bajo la premisa de tener operaciones de actualización o updates sobre los registros para ahorrar espacio y no guardar todo el historial de transacciones en el tiempo.
Por supuesto hoy en día, con el advenimiento de la nube, el almacenamiento es muy costo efectivo y nos permite guardar cantidades enormes de información; prácticamente ilimitado. Y esto entonces nos lleva a decir que es posible guardar todo ese historial de nuestro libro en el tiempo en una base de datos.
Luego de este breve marco de referencia; en AWS se tienen múltiples tipos de bases de datos específicamente diseñadas para ciertos casos de uso. Por ejemplo: se tienen soluciones relacionales como Aurora y RDS; del tipo llave-valor como DynamoDB, en memoria como ElastiCache entre otros. Y por supuesto; del que escribimos hoy que es QLDB para casos en donde se tiene un ledger o libro.
¿Qué es Amazon QLDB?
Es un servicio administrado de una base de datos de tipo ledger que mantiene una historia completa y verificable de los cambios realizados en el tiempo. En este servicio no tenemos que preocuparnos por aprovisionar instancias o capacidad. La información es copiada entre zonas de disponibilidad para gozar de alta disponibilidad y durabilidad.
El hecho que QLDB tenga la característica de ser inmutable y verificable resulta de suma importancia para clientes que sean sujetos de escrutinio legal, regulatorio, auditoria o simplemente desee probar la integridad del historial de transacciones a terceras partes.
Por supuesto, varios de ustedes podrán decirme:
Nosotros si guardamos ese historial de cambios en una bitácora.
Ciertamente las bitácoras son el medio tradicional que se usa para eso; pero conlleva varios problemas por ejemplo: que están segmentados, son difíciles de unificar y no hablemos de la complejidad para consultar o acceder a esas bitácoras.
En QLDB se emplea el concepto de un diario o journal. Este diario es el corazón de esta base de datos; ya que nos brinda integridad transaccional, verificación criptográfica y determina el estado.
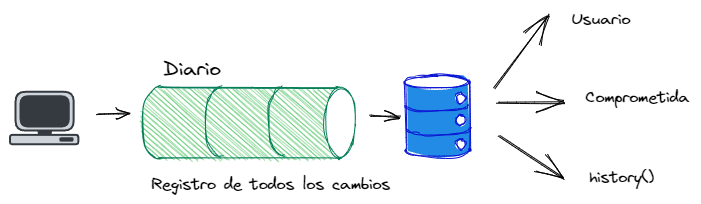
Es similar a una bitácora tradicional pues todas las escrituras van al diario. Y puede ser compleja de acceder; por lo cual se tiene varias vistas :
- La vista de usuario. Es la vista por omisión y corresponde a la última revisión de data de nuestra aplicación que no ha sido borrada.
- La vista comprometida. Es idéntica a la vista de usuario, pero contiene además metadata generada por el sistema para cada documento.
- La función history() provee acceso a las revisiones de los documentos, incluyendo los datos y su metadata.
En la parte práctica veremos el uso de estas vistas y función; pero en términos se tiene esto:
Algunas de la cualidades a resaltar son:
- Los datos no pueden ser alterados y el diario sólo permite que se le agregue al final. Esto quiere decir que se tiene la secuencia de todos los cambios a los datos. Estos no se pueden borrar, modificar o sobreescribir; a la vez que tenemos la posibilidad de consultar y analizar ese historial.
- El diario es un registro completo de todas las transacciones comprometidas (commit) y sus revisiones.
- Todas las operaciones comprometidas son escritas en el diario; incluso las lecturas.
Aclaro que esto no quiere decir que no podemos modificar los datos de nuestro negocio; pero en lugar de sobreescribir la información, una nueva versión es anexada al diario. Entonces con este tenemos que el diario es inmutable y completo.
Otra de las características que se tiene es la verificación criptográfica. Esta prueba que los datos no ha sido alterada en manera alguna. Esto por medio de un hash (sha256) que viene a ser como una huella digital de la data.
Los registros en el log contienen entradas como el comando de consulta en PartiQL (lo veremos más adelante) y los documentos manipulados; estas entradas se registran y se les aplica el hash y luego se encadenan. Internamente QLDB emplea árboles de Merkle para encadenar el hash de los nodos.
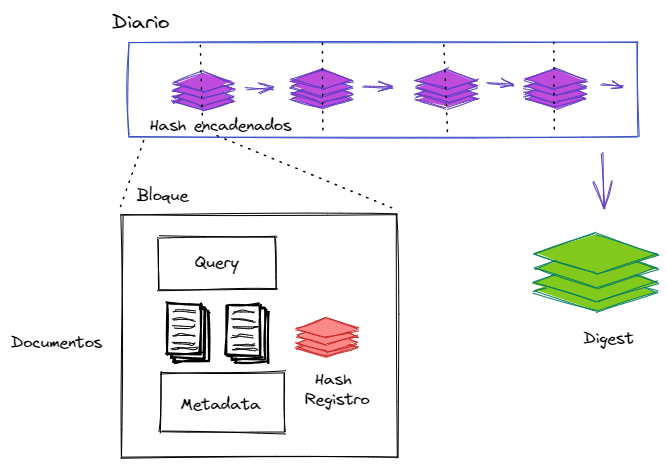
Es de hacer notar que cuando se calcula el hash de un nuevo bloque; se toma el hash del bloque previo y la data del nuevo bloque y se pasa esto por el algoritmo de SHA-256; a esto es a lo que se conoce como hash-chained.
La verificación requiere entonces recalcular el digest del diario. El digest es un hash 256-bit que representa de manera única el historial completo del diario en un punto de tiempo dado. El hash del digest es calculado a partir de la cadena completa de hash del diario hasta el último bloque comprometido en el diario.
Cabe señalar que un simple cambio de un caracter implica que el hash será diferente. De la misma manera, una función hash es de una vía; esto quiere decir que no es posible calcular la entrada con base en la salida.
En la siguiente imagen se ejemplifica como un sólo cambio genera un hash totalmente diferente.

Para este momento posiblemente esto les sea similar a un blockchain; pero no nos confundamos con el servicio AWS Managed Blockchain el cual es una solución descentralizada; QLDB es centralizada. Pero eso sería ya tema de otro artículo.
¿Cómo funciona QLDB?
A nivel general el flujo es el siguiente:
- Nuestra aplicación se conecta al diario para iniciar la ejecución de las transacciones.
- La data se escribe primero en el diario; que como indicamos es de modo append y mantiene el registro de todos los cambios realizados. Esas transacciones son secuenciadas, se les aplica un hash y se enlazan para garantizar la integridad e historial. El diario es lo que dicta el estado de nuestras tablas.
- Una vez que los datos se escriben en el diario, se materializan en nuestras tablas. Esto lo ilustraremos con un ejemplo más adelante.
- Cuando la aplicación lee la data, accesa las tablas e índices que se tienen almacenados.
Hay que recalcar que QLDS emplea transacciones ACID y con el máximo nivel de aislamiento; el cual es serializable. Esto nos evita tener que lidiar con lecturas fantasmas, lecturas sucias, entre otros casos comunes a otros tipos de aislamiento como: read committed, read uncommited, repeteable read. Si! los mismos temas que se estudian en los cursos de bases de datos relacionales.
Otro elemento a considerar es que QLDB emplea un modelo de concurrencia optimista. Esto quiere decir que opera bajo el principio que múltiples transacciones pueden completarse sin interferir una con la otra, puede desprenderse de lo anterior que no hay necesidad de adquirir un ‘lock’ sobre los datos; de hecho literalmente no hay ‘locks’ en QLDB.
Antes de comprometer una transacción QLDB ejecuta una validación para asegurarse que ninguna otra transacción comprometida ha modificado el ‘snapshot’ de los datos que esta leyendo y si esta falla se lanza una excepción.
En un motor relacional se hace necesario utilizar lock (FOR UPDATE por ejemplo) para evitar caer en errores en nuestros aplicativos (control de concurrencia pesimista); esto genera una sobrecaga en la base de datos. Si por alguna razón olvidamos tomar ese ‘lock’ y se da una situación de competencia transaccional, podemos obtener resultados incoherentes.
Amazon Ion
Amazon Ion es un formato de documento de código abierto. y un superset de JSON; por lo que cualquier documento JSON que sea válido es también un documento de Ion válido. El modelo abstracto permite almacenar información estructurada o no estructurada. Esto permite trabajar con texto, binario, números, null, etc. Además, un documento puede ser una estructura jerárquica compleja, no sólo filas.
Un ejemplo de un documento en Ion es este:
[
{
numero: "3-202020-1",
medidas: "250",
naturaleza: "BLOQUE E LOTE 3 TERRENO PARA CONSTRUIR",
plano: "00000100001",
linderos: [
{
descripcion: "LOTE 4 E",
puntoCardinal: "NORTE"
},
{
descripcion: "LOTE 2 E",
puntoCardinal: "SUR"
},
{
descripcion: "LOTE 16 D",
puntoCardinal: "ESTE"
},
{
descripcion: "CALLE 17",
puntoCardinal: "OESTE"
}
],
propietario: {
numIdentidad: "1-1111-1111",
fechaInscripcion: "20-DIC-2007",
nombre: "JUAN PEREZ",
citas-presentacion: "0001-00010000-01"
},
valorFiscal: "100 COLONES"
}
]
PartiQL
PartiQL tiene soporte para un subset de SQL que ha sido extendido para soportar documentos en Amazon Ion. Podemos hacer uso de los familiares comandos de SQL para un insert, update o select. La sintaxis al consultar documentos planos es la misma que al consultar tablas relacionales; es agnóstico al formato de la data y a su almacenamiento (por ejemplo S3, AWS Redshift, QLDB). También es un proyecto de código abierto.
Por ejemplo:
select numero, medidas, propietario from finca
where numero = '3-202020-1'
Hago una nota respecto al comando delete. Este crea un nuevo bloque, se agrega al journal y se encadena al bloque previo. Se remueve de la tabla, pero las versiones previas siguen siendo accesibles en la vista de historia adicional a un record que marca el borrado. La data nunca es removida del diario.
Intentar recrear un diario en una base de datos relacional no me parece viable. Las bases de datos relacionales no fueron creadas para ser inmutable o verificables criptográficamente. En algunos casos he visto clientes tratando de emular esto por medio de los audit trails o tablas de auditoria; pero son soluciones difíciles, muy complejas y costosas de construir y aún más de mantener en el tiempo.
La otra opción es emplear algún framework de blockchain, pero estos están diseñados para otro propósito: son de-centralizados y requieren de al menos dos participantes; agregando una complejidad que normalmente es innecesaria cuando se busca un diario centralizado.
Posibles Usos
Una manera de usar QLDB es escribir a ella de manera que sea la fuente de verdad de la información. Las aplicaciones hacen lecturas sobre QLDB y las actualizaciones del diario son transmitidas usando QLDB Streaming. Se pueden usar funciones Lambda para consumir ese flujo de información y enviarla a otras bases de datos que soporten otros tipos de casos de uso como analíticas, RDBMS, entre otros.
Otra posibilidad es escribir en QLDB cómo un paso posterior a escribir en una base de datos principal. En este escenario debemos tener una base de datos que tenga algún mecanismo de transmisión o ‘streaming’ para enviar eventos (por ejemplo DynamoDB o bien en RDS Aurora); de ahi una función Lambda puede consumir los eventos y escribirlos a QLDB.
Como ven, es posible integrar diferentes tipos de base de datos de acuerdo a las necesidades de nuestros sistemas; hay que buscar la herramienta adecuada para cada caso.
Exiten muchos otros tipos de arquitecturas para usar QLDB, por lo que les invito a que los investiguen para poder emplear el más adecuado para sus necesidades.
Ejemplo de Uso
Luego del abordaje previo, es momento de hacer una prueba de QLDB.
Nuestro primer paso es dirigirnos a la consola de QLDB y crear nuestro primer libro mayor o ledger. En nuestro ejemplo haremos un ejercicio sobre las fincas o propiedades de bienes inmuebles. Para el ejemplo dejaremos el atributo de permisos en el recomendado.
Luego de algunos minutos tendremos nuestro libro mayor preparado.
El siguiente paso es crear una tabla de fincas o propiedades. Para hacerlo haremos uso del PartiQL editor ubicado en el lado izquierdo de la consola.
Para crear esta tabla e indice haremos esto:
create table finca
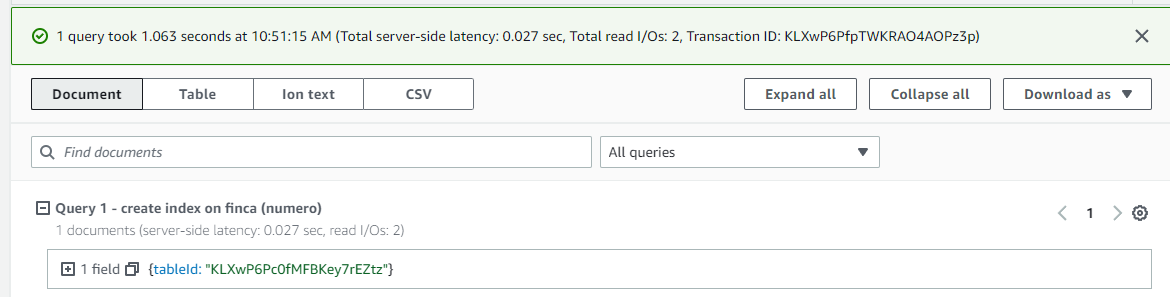
create index on finca (numero)
A diferencia de una tabla en RDBMS no necesitamos definir explicitamente cada atributo. Si indicamos para el indice cual sería el atributo que identifica cada propiedad que iremos registrando.
en la parte inferior podemos observar la métrica de tiempo de ejecución y número de transacción.
Vamos a cargar algunos datos en nuestra tabla.
INSERT INTO finca
<<
{
'numero': '3-202020-1',
'medidas': '250',
'naturaleza': 'BLOQUE E LOTE 3 TERRENO PARA CONSTRUIR',
'plano': '00000100001',
'valorFiscal': '100.00 COLONES',
'linderos': [{
'descripcion': 'LOTE 4 E',
'puntoCardinal': 'NORTE'
}, {
'descripcion': 'LOTE 2 E',
'puntoCardinal': 'SUR'
}, {
'descripcion': 'LOTE 16 D',
'puntoCardinal': 'ESTE'
}, {
'descripcion': 'CALLE 17',
'puntoCardinal': 'OESTE'
}],
'propietario': {
'numIdentidad': '1-1111-1111',
'fechaInscripcion': '20-DIC-2007',
'nombre': 'JUAN PEREZ',
'citas-presentacion': '0001-00010000-01'
}
} >>
y si hacemo un select podemos ver el resultado
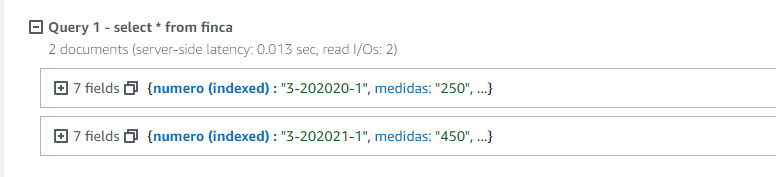
o incluso por medio de un where habitual.
select * from finca
where numero = '3-202020-1'
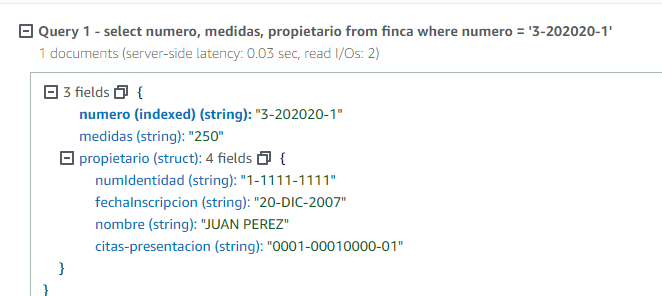
o algo como esto:
select numero, medidas, propietario from finca
where numero = '3-202020-1'
Se pueden preguntar si es posible tener llaves foráneas entre tablas; y la respuesta es que si. La mejor práctica dicta que se emplee el valor del campo de metada id. Este lo podemos ver con un select a vista _ql_committed_finca.
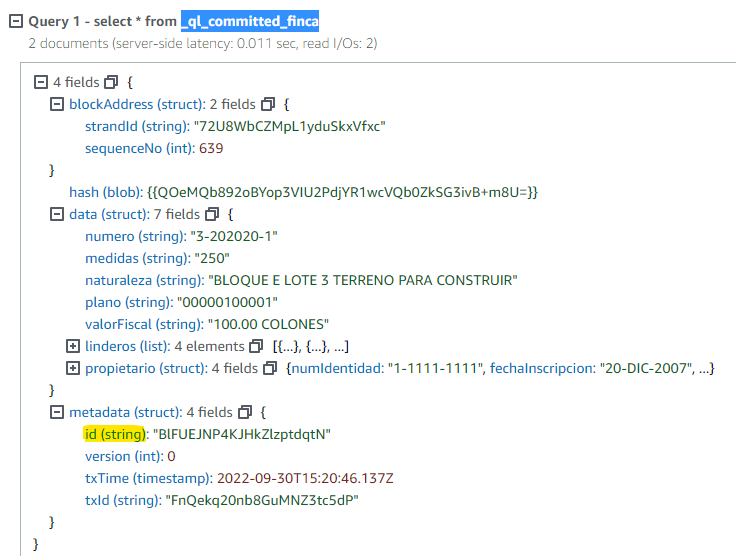
El prefijo _ql_committed_ es reservado y significa que deseas ver la vista comprometida de la tabla finca en este caso.
Es el momento de hacer algunos cambios en esta finca; en particular vamos a modificar el valor fiscal.
update finca
set valorFiscal='1000 COLONES'
where numero='3-202020-1'
si consultamos el documento veremos los datos actualizados correctamente.
Si queremos ver el historial de cambios sobre esta finca primero necesitamos saber el id que esta en la metadata; una manera es por medio de un select
SELECT f_id FROM finca AS f BY f_id
where numero = '3-202020-1'
y con este valor vemos la historia de la finca
select data.* from history(finca)
where metadata.id='BlFUEJNP4KJHkZlzptdqtN'
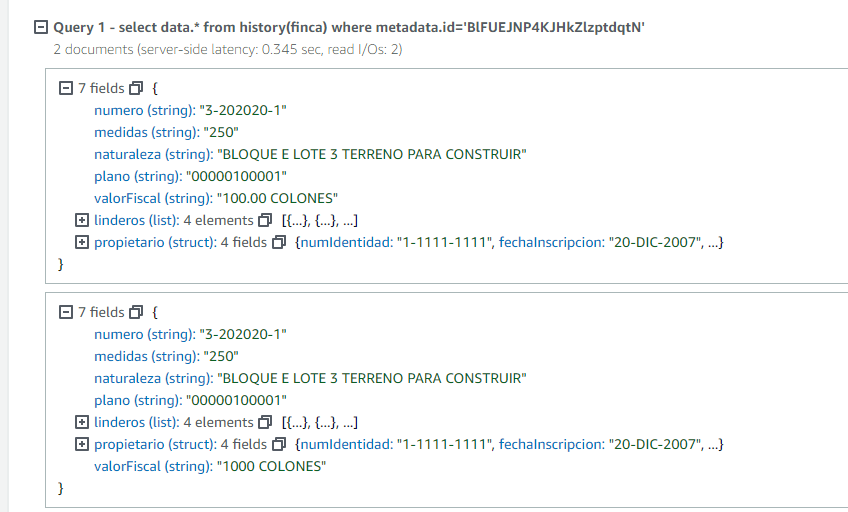
Vemos que regresa todas las revisiones del documento BlFUEJNP4KJHkZlzptdqtN; idealmente debemos filtrar además por un rango de tiempo pues si se tienen un número muy grande de revisiones podríamos llegar al timeout de la transacción.
Si revisamos la metadata en la historia; veremos la fecha de cada transacción junto con otros datos importantes.
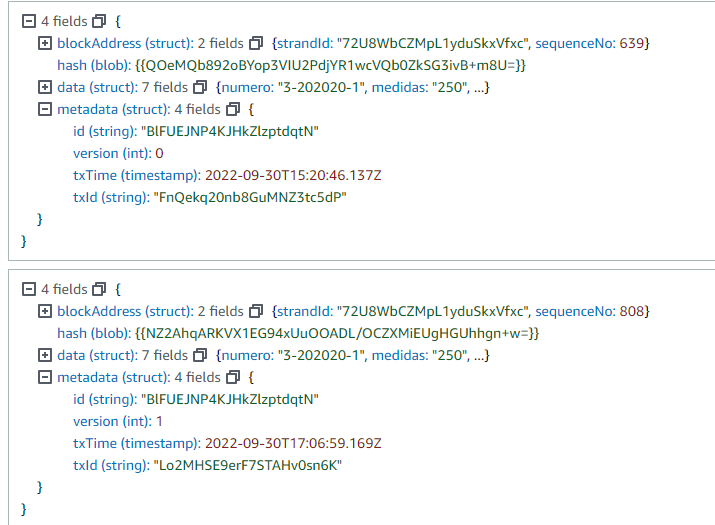
¿Cómo verificamos el diario y el documento?
Si vamos a nuestro diario y seleccionamos la opción Get Digest tendremos los siguientes detalles:
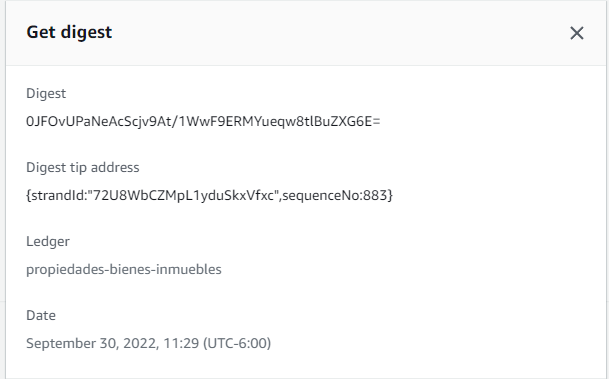
- Digest: Es el SHA-256 de este digest.
- Digest tip address: Es el último bloque en el diario cubierto por este digest.
- Ledger: el nombre del diario.
- Date: el timestamp del momento que solicitamos el digest.
Esto es un documento en formato Ion y en nuestro ejemplo es:
{
"digest": "0JFOvUPaNeAcScjv9At/1WwF9ERMYueqw8tlBuZXG6E=",
"digestTipAddress": "{strandId:\"72U8WbCZMpL1yduSkxVfxc\",sequenceNo:883}",
"ledger": "propiedades-bienes-inmuebles",
"date": "2022-09-30T17:30:49.868Z"
}
Lo que sigue es obtener el id y blockAddress de la revisión del documento que deseamos verificar. Esta info esta en la metadata dentro de la vista comprometida
SELECT metadata.id, blockAddress
FROM _ql_committed_finca
where data.numero = '3-202020-1'
el resultado en formato Ion es este
[
{
id: "BlFUEJNP4KJHkZlzptdqtN",
blockAddress: {
strandId: "72U8WbCZMpL1yduSkxVfxc",
sequenceNo: 808
}
}
]
Vamos a usar la consola para verificar este documento; en donde debemos brindar los datos del documento previo y los del digest como se muestra de seguido
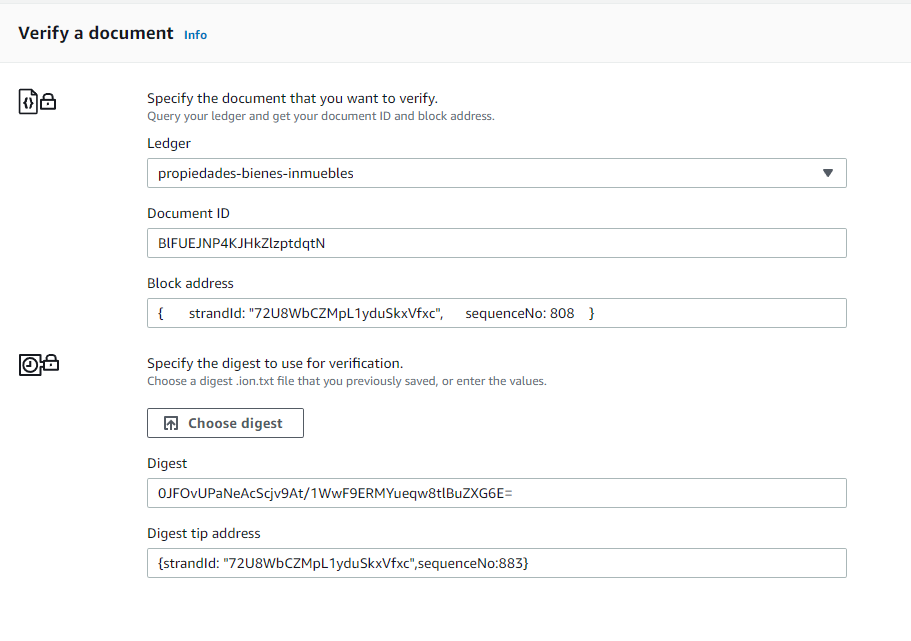
Además podemos tener el detalle precio de la revisión y su prueba.
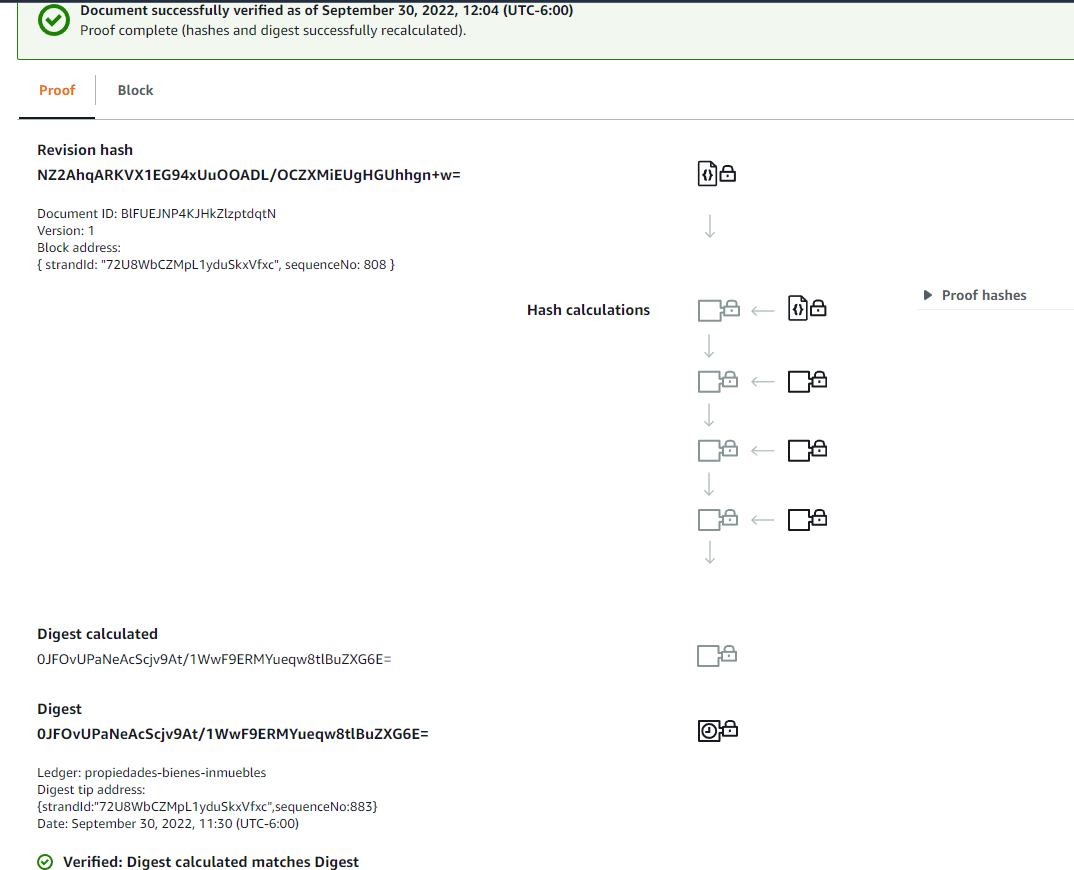
Si cambiase algo en el digest del documento, por ejemplo; la validación fallaría.

En este artículo hice uso de la consola para ejemplificar el uso; pero hay drivers para múltiples lenguajes de programación como Java, .NET, Go, Node.js y Python. A manera de ejemplo; obtener el digest en Java se hace de esta manera:
GetDigestRequest request = new GetDigestRequest()
.withName(ledgerName);
GetDigestResult result = client.getDigest(request);
log.info("Success. LedgerDigest: {}.",
QldbStringUtils.toUnredactedString(result));
Conclusión
QLDB es una herramienta muy interesante y aplicable a múltiples casos de uso en donde la idea de un diario o cobra significancia. Los puntos que resalto del servicio son:
- Inmutabilidad. Es sólo anexar al final de manera secuenciada.
- Fácil de Usar. Empleanos nuestro conocimiento actual de operadores de SQL
- Criptográficamente verificable. El encadenamiento del hash garantiza la integridad y verificación.
- Transacciones ACID. Con aislamiento completo serializable.
- Altamente escalable. Serverless y con alta disponibilidad.
- Diario o Journal. El diario es la base de datos.
- API. Se tiene un API en diversos lenguajes de programación.
- Integración; puedes usar QLDB en conjunto con motores relacionales tradicionales.
Espero que este artículo les haya sido de utilidad.



Inicia la conversación