


Tabla de Contenidos
Al hablar de Lambdas en AWS y mencionar particularmente Java como lenguaje para escribirlas; me ha sido normal escuchar comentarios respecto a que el arranque en frío o cold start puede ser excesivo para que tenga un valor real en cargas de trabajo productivas.
Previamente he escrito respecto al éxito que he tenido en varios proyectos usando Lambdas en Java con Quarkus, logrando tiempos de respuesta de milisegundos.
Hoy nos toca escribir de Lambda SnapStart.
¿Qué es un arranque en frío?
Antes de profundizar en SnapStart, es conveniente que todos tengamos claro qué es un arranque en frío o un cold start. Debemos empezar por saber que AWS Lambda es un servicio serverless que reacciona antes eventos o disparadores. Y la palabra clave es serverless: nosotros no aprovisionamos ningún servidor para ejecutar nuestro código.
Sabiendo lo anterior, la primera vez que ejecutamos nuestra función Lambda, AWS necesita disponer de los recursos de computo para que pueda ser ejecutada. Este proceso es lo que se llama arranque en frío. Durante este cold start AWS inicializa los recursos de cómputo requeridos para ejecutar la función, carga nuestro código, configura las variables de ambiente, entre otros pasos.
Todo este proceso puede demorar algunos cientos de milisegundos o incluso segundos; dependiendo de factores como el tamaño del código, cantidad de memoria asignada, etc.
Una vez que esos recursos están inicializados, las invocaciones subsiguientes a esa misma función -que se den en un corto periodo de tiempo- hacen reuso de los mismos; y esto se llama warn start. Este tipo de arranque es mucho más rápido que uno en frío pues los recursos ya estaban inicializados.
Y esto se puede probar de una manera sencilla; invoquen un Lambda la primera vez. Verán que tarda un poco en responder; al tener la respuesta invoquen de nuevo y notarán que responde sumamente rápido.
¿Qué podemos hacer para mejorar esos arranques en frío?
Tradicionalmente los mecanismos que se tienen para lidiar con estos arranques en frío consisten en el uso de Provisioned Concurrency. Con esta funcionalidad uno puede asociar a una versión específica de un Lambda la cantidad de concurrencia aprovisionada que uno desea.
Esto se traduce en que Lambda tiene preparados los recursos de computo e inicializados para nuestra función de antemano, listos para ser invocados con una latencia de unos pocos milisegundos. De esta manera nuestras funciones serverless pueden gozar del warn start que mencione previamente.
Para tener provisioned concurrency activo via la consola, se debe tener una versión y aplicar lo que se ve de seguido.
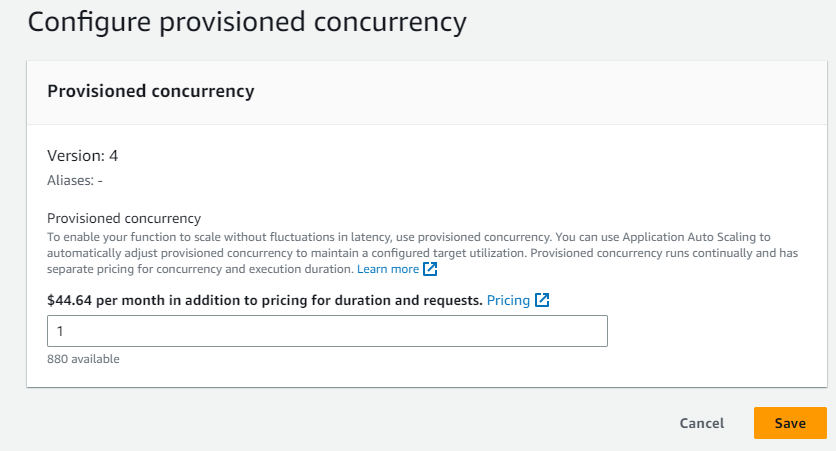
Pero como pueden ver; esto beneficio no es gratis. AWS tiene un cobro separado por este servicio basado en la configuración del Lambda (cuanto RAM tiene asociado, la arquitectura y la cantidad de concurrencia reservada que deseamos).
¿Qué más podemos hacer?
Por la naturaleza de AWS Lambda y serverless en general; no es posible evitar completamente los arranques en frío. Lo que si podemos hacer es aplicar algunas estrategias que nos pueden ayudar a lidiar con ella de la mejor manera posible; entre ellas podemos citar:
-
Quarkus Si podemos generar versiones nativas de nuestro código en Java usando frameworks como Quarkus; podemos reducir dramaticamente el impacto de los cold starts. Sin embargo, soy el primero en decir que no podemos convertir todas nuestras funciones a modo native de Quarkus. La razón más simple: usamos dependencias que no fueron creadas para un entorno como Quarkus y simplemente deben correr en un JVM.
-
Optimizar Código Si logramos reducir el tamaño de nuestro código y sus dependencias vamos a ganar unos milisegundos valiosos en los arranques frios.
-
Incrementar la memoria El rendimiento de un Lambda va directamente ligado a la cantidad de memoria que le asignemos. A mayor cantidad de memoria, mayor rendimiento.
-
Provisioned Concurrency Nos permite tener a nuestros Lambdas precalentados; a expensas de un costo adicional.
-
Peticiones de Calentamiento Podemos usar por ejemplo EventBridge para que cada X cantidad de minutos haga un hit a nuestros lambdas. Estas invocaciones podemos hacerlas de manera tal que no ejecuten el código completo; pero si permite inicializar los recursos.
Lambda Snap Start
Durante ReInvent 2022 se anunció Lambda SnapStart el cual promete eliminar el proceso de cold start descrito con anterioridad al crear un snapshot de nuestra función y así “brincarnos” el proceso de inicialización habitual. Basados en los datos brindados en el keynote; se habla de hasta un 90% de mejora.
En términos generales, lo que hace SnapStart es que al crear una nueva versión de la función procede a tomar un snapshot encriptado del estado de la función y tenerlo en cache para uso posterior. Cuando la función es ejecutada posteriormente, SnapStart toma el snapshot en lugar de correr el proceso tradicional.
Antes de empezar con los resultados de las pruebas; debo mencionar las limitaciones que se tienen a la fecha de escribir este artículo:
- Tiene soporte únicamente en Java 11
- No tiene soporte para usarlo en conjunto con provisioned concurrency
- No tiene soporte en ARM64
- No tiene soporte para Amazon Elastic File System (Amazon EFS)
- No tiene soporte para AWS X-Ray
- No puede tener almacenamiento efimero superior a 512 MB
Existen también tres consideraciones de compatibilidad debidamente documentadas en el sitio de AWS.
- Singularidad o Unicidad: Si nuestro código de inicialización genera contenido único; este estaría en el snapshot y entonces se reusaría.
- Conexiones de red: El estado de las conexiones que establezcamos en la fase de inicialización no están garantizadas cuando se resuma una ejecución del snapshot.
- Data temporal: Cualquier data temporal que necesitamos debe ser descargada antes de usarla.
Pruebas
El código del Lambda es sencillo y para que fuese más similar a un caso de la vida real; agregue un RDS PostgreSQL para poder retornar el contenido de una tabla. A su vez esta Lambda es expuesto por medio de API Gateway como una integración de tipo Lambda Proxy.
Para poder tener métricas de los arranques en frío; utilice Logs Insight con la siguiente consulta en donde buscamos por el Init Duration que nos señala que esa invocación al Lambda fue en frio.
filter @type = "REPORT"
| parse @log /\d+:\/aws\/lambda\/(?<function>.*)/
| stats
count(*) as invocations,
pct(@duration+coalesce(@initDuration,0), 50) as p50,
pct(@duration+coalesce(@initDuration,0), 90) as p90,
pct(@duration+coalesce(@initDuration,0), 99) as p99
group by function, (ispresent(@initDuration)) as coldstart
| sort by coldstart desc
Para las pruebas utilice JMeter con un total de 100 invocaciones al API; sin ramp up y el Lambda configurado con 512 MB. Los resultados de la prueba fueron estos:
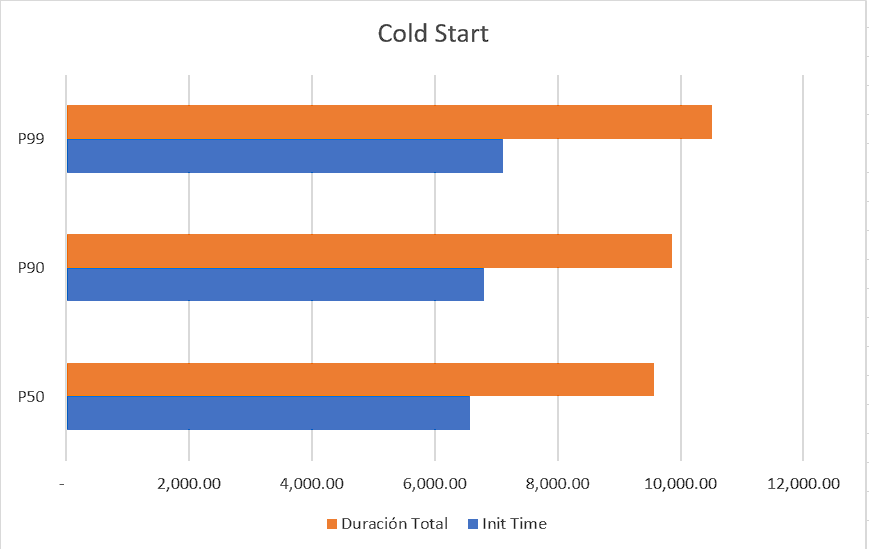
Como observamos la media de tiempo del cold start fue de 6,577 ms y la media de la duración completa de una petición fue de 9,571.13 ms
Ahora, activaremos el SnapStart en nuestra Lambda. Eso se hace en la configuración general y se selecciona “PublishedVersions””.
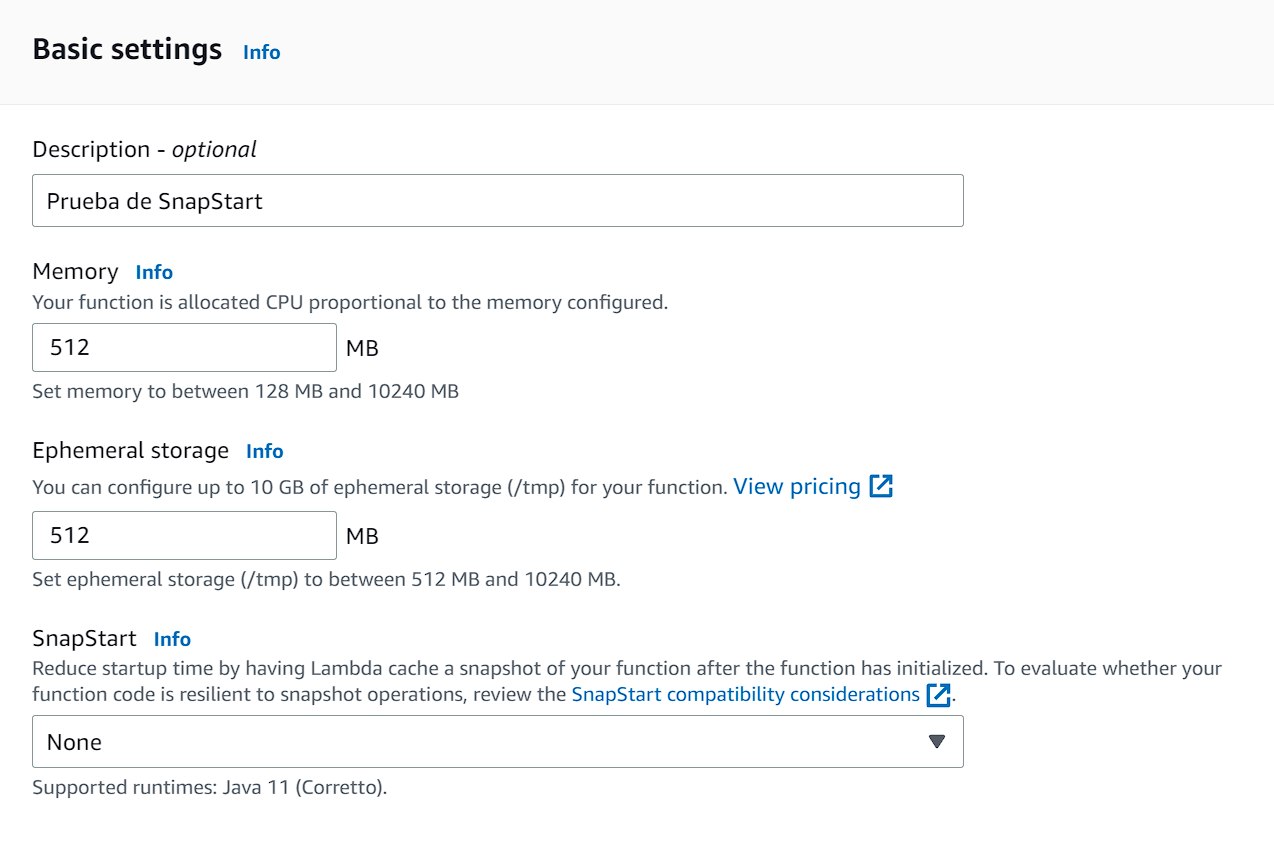
Esto lo que indica es que las versiones que publiquemos, Lambda tomara un snapshot de la memoria y estado de almacenamiento del ambiente una vez inicializado.
Si creamos una nueva versión del Lambda veremos esto:
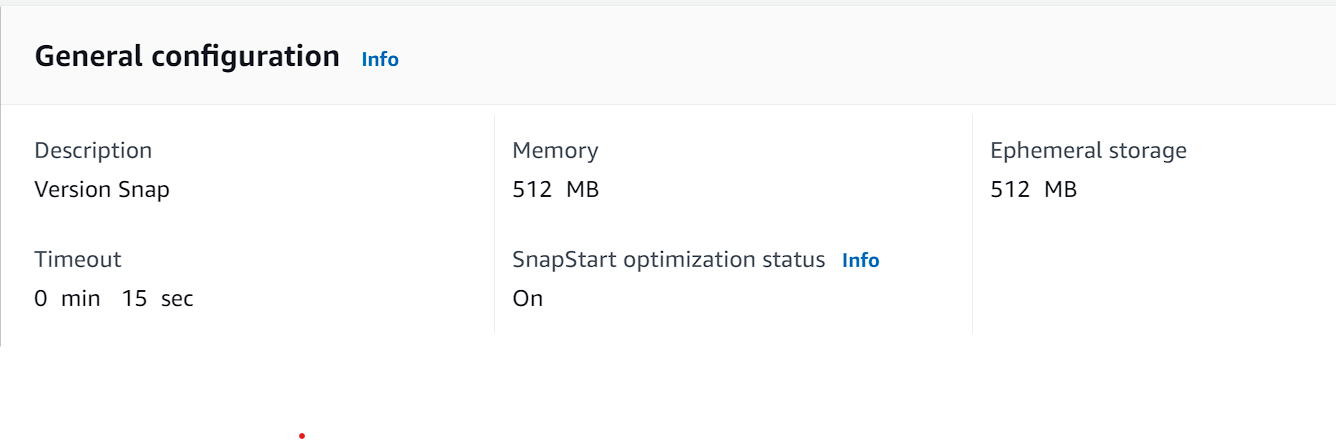
Vemos que indica que la optimización de SnapStart esta vigente.
Ahora emplee otra consulta de Logs Insight, buscando por el Restore Duration. Importante, en estos casos el ‘Init Duration’ será siempre 0.
filter @type = "REPORT"
| parse @log /\d+:\/aws\/lambda\/(?<function>.*)/
| parse @message /Restore Duration: (?<restoreDuration>.*?) ms/
| stats
count(*) as invocations,
pct(@duration+coalesce(@initDuration,0)+coalesce(restoreDuration,0), 50) as p50,
pct(@duration+coalesce(@initDuration,0)+coalesce(restoreDuration,0), 90) as p90,
pct(@duration+coalesce(@initDuration,0)+coalesce(restoreDuration,0), 99) as p99
group by function, (ispresent(@initDuration) or ispresent(restoreDuration)) as coldstart
| sort by coldstart desc
Al repetir la misma prueba con Power JMeter nos encontramos con estos resultados:
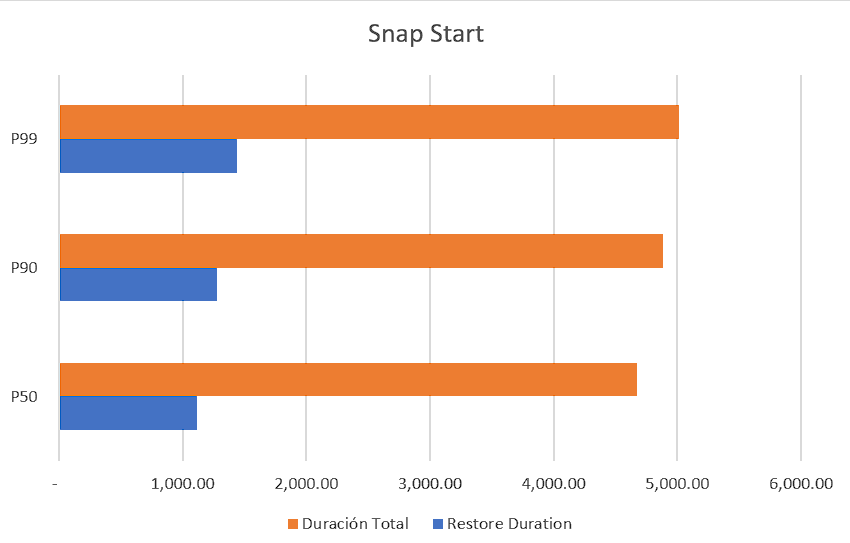
Ahora tenemos que la media del restore time fue de 1,113 ms, una diferencia nada despreciable de 6x respecto al cold start. Y la media del tiempo de respuesta total fue de 4,673.29 ms que es un 2x respecto al ejercicio previo.
Vale destacar que una vez que el Lambda esta caliente, las peticiones duran menos de 100 ms en responder en cualquiera de los casos.
Conclusión
El empleo de SnapStart resulta en una importante mejora en el tiempo de atención de las peticiones en frío; en nuestro ejemplo llegamos a una mejora de 6x.
A diferencia de Provisioned Concurrency no hay un cargo adicional por activarla; aunque debemos validar nuestra función para confirmar que cumplimos con los requisitos que demanda SnapStart o bien hacer ajustes menores al código (lo más común son las relacionadas a las conexiones a la base de datos).
Existen otras técnicas que no debemos olvidar, como la optimización de código y de dependencias. Y por supuesto, el RAM que asignamos al Lambda, el empleo de AWS Lambda Power Tuning no puede ser dejado de lado.
Si empleamos Lambda, debemos tener claro siempre que impacto tienen los cold start y evaluar que proceso emplearemos para mitigarlo; esto desde la fase de diseño de nuestras soluciones.
Espero que este artículo les haya sido de utilidad.



Inicia la conversación