

Tabla de Contenidos
- El costo real del agente duplicado
- AWS Agent Registry, en dos minutos
- Las cuatro personas: la espina dorsal del modelo
- Manos a la obra: el laboratorio de Aurora Capital
- El primer choque con IAM (que la documentación no anticipa)
- Cuatro descriptors, cuatro formas (y solo una está bien documentada)
- El flujo de aprobación real (con statusReason obligatorio)
- Búsqueda híbrida: la realidad detrás de la promesa “semántica”
- El cierre: Claude Code descubre tu organización
- Lecciones aprendidas
- Lo que todavía no está
- Conclusión
Hace dos semanas, en una llamada con un amigo, salió la frase que vengo escuchando en distintos formatos desde principios de año:
“Tengo cuatro equipos construyendo agentes en paralelo. Hace dos meses descubrí que dos de ellos estaban haciendo lo mismo. Lo peor: ninguno tiene los mismos guardrails.”
No es la primera vez. La conversación se repite con variaciones predecibles entre líderes de plataforma de varias empresas latinoamericanas con las que vengo trabajando: la primera ola de agentes corporativos llegó por iniciativa de cada squad, sin coordinación, y ahora alguien tiene que poner orden antes de que la lista pase de 8 agentes a 50.
Si estás del lado de “todavía no llegamos a 8”, buenas noticias: AWS sacó en preview el servicio que necesitabas hace seis meses. El 9 de abril de 2026 anunciaron AWS Agent Registry, un catálogo privado para tu organización donde se publican agentes, servidores MCP, skills y recursos personalizados con un flujo de aprobación enchufable. Si estás del lado de “tengo 50 agentes y un mapa hecho a mano en Confluence”, también buenas noticias: el camino para migrar al Registry empieza el día que tu organización entiende lo que viene a continuación.
Este post es el resultado de pasar la última semana levantando un laboratorio integral en mi cuenta — desde Terraform de IAM hasta Claude Code conectado al Registry vía MCP — y documentando las doce trampas reales que aparecieron en el camino (once de la API hoy más una de la spec A2A upstream que ya pinta en el horizonte). Algunas son sutiles. Cuatro de ellas van a hacer que tu primer create_registry_record falle de manera no obvia. Te las marco para que no pierdas el rato que perdí yo.
🎯 ProTip #1: La gobernanza de agentes es una decisión del día 1, no del día 100. La diferencia entre “qué bueno que pusimos un catálogo” y “ahora tenemos que migrar 47 agentes hacia el catálogo retroactivamente” se mide en semanas-persona perdidas. El servicio ya existe; el caso de adopción es contundente.
Si vienes de mi último post — el benchmark de las 5 estrategias de chunking en Bedrock Knowledge Bases — el ángulo de éste es distinto. Allá el lector ideal era el desarrollador iterando sobre RAG. Acá es quien pisa el freno antes de que la dispersión se vuelva irreversible: CTOs, líderes de plataforma y arquitectos que están viendo crecer el inventario de agentes y entienden que sin un catálogo van a terminar reinventando ServiceCatalog desde cero, peor.
El costo real del agente duplicado
Cuando escuchas “duplicación”, quizás te imaginas dos desarrolladores escribiendo el mismo código. La realidad de la duplicación de agentes es peor: dos pipelines distintos consumiendo presupuesto de Bedrock, dos conjuntos de roles IAM que nadie audita, dos integraciones con Jira que se contradicen entre sí cuando el mismo ticket viaja por ambas, y la incertidumbre de no saber cuál de los dos es el “oficial” cuando llega un incidente de producción.
Multiplícalo por una organización con siete squads y la primera ola de adopción de GenAI:
- Squad SRE construye un agente de triage de incidentes que llama a Jira.
- Squad Customer Lifecycle construye un agente de onboarding que también llama a Jira para crear tickets de KYC.
- Squad Billing construye un servidor MCP para Stripe que internamente reusa una función de redacción de PII que ya existía como herramienta aislada en el equipo de Compliance.
- Squad Data tiene un envoltorio de Athena que el equipo de Analytics no encuentra y reconstruye con SQL libre, abriendo un agujero de seguridad que el primero ya había cerrado.
Cada decisión individual fue racional. Sumadas, son una pesadilla de gobernanza. Y ningún ticket de Jira va a coordinar esto retroactivamente — para cuando el problema es visible, ya tienes que escribir un programa de migración con su propio backlog.
La pregunta no es si necesitas un catálogo de agentes. Es si lo estás poniendo cuando puedes (8 agentes) o cuando te toca (50).
AWS Agent Registry, en dos minutos
Agent Registry vive bajo la sección Discover en la consola de AgentCore — no bajo Build ni Test. Esa ubicación dice algo: AWS está marcando el Registry como un servicio de descubrimiento, no de construcción. Es un detalle de experiencia de usuario que predice cómo va a evolucionar el producto: la integración futura con Runtime y Gateway probablemente sea automática (un agente desplegado se autoindexa), pero hoy no lo es. Por ahora todo es manual.
Lo que catalogás:
- MCP servers — valida contra el schema oficial MCP. Los servidores MCP que tu agente cliente debe saber que existen.
- Agents — valida contra el schema A2A AgentCard. Agentes corporativos que otros agentes pueden invocar.
- Skills — capacidades reutilizables (paquetes Python, librerías) con su propia metadata más documentación markdown.
- Custom resources — cualquier JSON que definas. Es la salida de escape para herramientas Lambda, endpoints HTTPS internos o cualquier cosa que no encaje en MCP, A2A o Skill.
Cada record vive un ciclo de aprobación:

Solo los APPROVED aparecen en búsquedas. Los REJECTED y DEPRECATED se mantienen como historial pero son invisibles para los consumers.
Costo durante el preview: cero. Cuando salga a disponibilidad general (GA) el precio combina dos ejes: “Net Records” (registros vivos en cualquier momento; borrar uno descuenta) y API calls de discovery (Search, List, Get).
Regiones del preview (cinco): us-east-1, us-west-2, ap-southeast-2, ap-northeast-1, eu-west-1.
Superficie de API (control plane más data plane):
| Plano | Acciones clave |
|---|---|
bedrock-agentcore-control |
CreateRegistry, CreateRegistryRecord, SubmitRegistryRecordForApproval, UpdateRegistryRecordStatus |
bedrock-agentcore |
SearchRegistryRecords, MCP endpoint HTTP path-based |
boto3 ≥ 1.42.87 es requisito; si tu SDK es más antiguo, los métodos no existen. La AWS CLI llegó tarde: los servicios bedrock-agentcore-control y bedrock-agentcore aterrizaron en AWS CLI v2 ≥ 2.34.28. Si al ejecutar aws bedrock-agentcore-control list-registries recibes Found invalid choice, corre aws --version y sube a 2.34.28 o posterior. boto3 los tiene desde >= 1.42.87, así que para iterar rápido durante el preview lo más simple es Python.
Las cuatro personas: la espina dorsal del modelo
Lo que más me llamó la atención mientras leía la documentación de IAM del Registry fue que AWS nombra explícitamente cuatro personas. No es marketing — es un mapa directo a políticas IAM separadas, y es la primera vez en AgentCore que la separación de roles está tan limpia.

Administrator. El dueño de la infraestructura del Registry. Crea los registries, define la autenticación (IAM o JWT), conecta EventBridge para automatizar la aprobación, decide si la aprobación automática está activa (en producción siempre desactivada). Tiene acceso total — incluida la posibilidad de aprobar o rechazar manualmente cualquier record sin pasar por el Curator.
Publisher. El constructor dentro de los squads. Crea registry records que describen sus recursos, itera sobre ellos en estado DRAFT y los envía para aprobación cuando están listos. Lo que no puede hacer (y vas a ver AccessDenied real si lo intenta): aprobar sus propios records, borrar registries, ni siquiera borrar sus propios records publicados.
Curator (o Approver). El guardián de calidad. Recibe records en estado pending approval — vía correo, Slack o ticket según cómo conectes EventBridge — evalúa contra los estándares de la organización y aprueba o rechaza con razón obligatoria. También deprecia records que ya no se usan. Lo que no puede: crear ni modificar el contenido de un record. Su único superpoder es decidir transiciones de estado.
Consumer. Cualquiera que busque recursos para usar. Solo ve records APPROVED. Por defecto opera contra el data plane (Search más MCP endpoint). Su rol es el más restringido y el más interesante: cuando conectás Claude Code o cualquier agente cliente al Registry, las credenciales que firman cada request son las del rol Consumer.
Esta separación parece obvia hasta que tratas de implementarla. Cuando armas las políticas inline con alcance mínimo persona por persona, vas a chocar contra el primer hallazgo del laboratorio — y es uno que la documentación no anticipa.
Manos a la obra: el laboratorio de Aurora Capital
Para aterrizar todo esto armé un laboratorio que simula una fintech latinoamericana ficticia llamada Aurora Capital, con siete squads y la primera ola de agentes corporativos. La organización está construida con suficiente especificidad para que los demos no se sientan de juguete: monedas reales (MXN, COP, ARS, BRL, CLP, PEN), squads con dueños identificables y casos de uso plausibles donde la duplicación es inminente.

Los ocho records del catálogo:
| # | Tipo | Recurso | Owner |
|---|---|---|---|
| 1 | MCP server | jira-mcp-server |
Squad SRE |
| 2 | MCP server | stripe-payments-mcp |
Squad Billing |
| 3 | A2A Agent | incident-triage-agent |
Squad SRE |
| 4 | A2A Agent | customer-onboarding-agent |
Squad Customer Lifecycle |
| 5 | Skill | pii-redaction-skill |
Squad Compliance |
| 6 | Skill | currency-conversion-skill |
Squad Treasury |
| 7 | Custom | athena-query-tool |
Squad Data |
| 8 | Custom | slack-notifier-tool |
Squad Platform |
Y la dinámica del demo: el slack-notifier-tool lo va a rechazar el Curator porque su endpoint mTLS no está en el catálogo de herramientas internas documentado. Los otros siete pasan a APPROVED y se vuelven descubribles.
La pila técnica que armé tiene dos partes claras:
- Terraform crea los 4 roles IAM (uno por persona), un tópico SNS con suscripción por correo y una regla EventBridge que captura
SubmitRegistryRecordForApprovaly notifica al Curator. - Python (boto3) crea el registry y los records, y ejecuta los envíos, las aprobaciones y las búsquedas.
¿Por qué no Terraform para el Registry? Porque al 28 de abril de 2026, ni hashicorp/aws (v6.42.0) ni hashicorp/awscc (v1.81.0) tienen aws_bedrockagentcore_registry ni _record. El AWS Provider tiene 12 recursos AgentCore (runtime, gateway, browser, code interpreter, memory, etc.) pero el Registry no aparece todavía. Eso te dice exactamente qué tan nuevo es: la forma de la API se está estabilizando todavía.
🚨 ProTip #2: Si en tu organización la regla es “todo en Terraform o nada”, el Registry no califica todavía. La forma sana de adoptarlo durante el preview es dejar IAM y EventBridge en Terraform (donde son fundacionales y no van a cambiar) y manejar el Registry desde Python o desde la consola hasta que el provider lo soporte. No ensucies tu código base con un
local-execapurado.
El primer choque con IAM (que la documentación no anticipa)
Con los 4 roles armados con políticas inline que tienen exactamente los permisos de cada persona, lancé el primer create_registry:
control = boto3.client("bedrock-agentcore-control")
resp = control.create_registry(
name="aurora-capital-prod",
description="Aurora Capital — registry corporativo de agentes",
)
print(resp["registryArn"])
# → arn:aws:bedrock-agentcore:us-east-1:123456789012:registry/aurora-capital-prod
print(resp["status"])
# → CREATING
API response 200 OK. Status CREATING, esperable. Al minuto siguiente, get_registry:
{
"name": "aurora-capital-prod",
"status": "CREATE_FAILED",
"statusReason": "Unable to create workload identity because access was denied."
}
CREATE_FAILED. ¿Acceso denegado por qué? El registro de CloudTrail aclara: internamente, el Registry provisiona un workload identity asociado al registry, y esa creación se hace con las credenciales del caller (mi rol Admin). El rol Admin con una política inline de solo bedrock-agentcore:*Registry* no tiene los permisos suficientes — faltan acciones internas de AgentCore más IAM PassRole más algo de Secrets Manager y KMS para el workload identity.
El arreglo correcto es la política administrada oficial:
resource "aws_iam_role_policy_attachment" "admin_full_access" {
role = aws_iam_role.admin.name
policy_arn = "arn:aws:iam::aws:policy/BedrockAgentCoreFullAccess"
}
BedrockAgentCoreFullAccess incluye: bedrock-agentcore:* sobre cualquier ARN, IAM GetRole/ListRoles/PassRole (este último limitado a roles *BedrockAgentCore* con condición iam:PassedToService = bedrock-agentcore.amazonaws.com), Secrets Manager para secrets prefijados bedrock-agentcore*, y KMS condicionado a aws:CalledVia = bedrock-agentcore.amazonaws.com.
⚠️ ProTip #3: La política inline con alcance mínimo funciona perfecto para Publisher, Curator y Consumer — esos AccessDenied del demo de gobernanza son reales y se sostienen. Pero el rol que ejecuta
CreateRegistrynecesitaBedrockAgentCoreFullAccess. La documentación de “Get Started” usa esta política administrada en los ejemplos sin remarcar por qué; cuando intentas ser más restrictivo, la API responde 200 y el registry queda muerto enCREATE_FAILED. Es un patrón engañoso que vale la pena conocer de antemano.
Y una segunda sutileza relacionada, esta vez de Terraform y SSO:
data "aws_caller_identity" "current" {}
# Si corrés desde una sesión SSO, devuelve:
# arn:aws:sts::123456789012:assumed-role/AWSReservedSSO_AdministratorAccess_31df6209ac649496/gerardo.arroyo
Si usas ese ARN literal como Principal en la trust policy de tus 4 roles, IAM puede rechazarlo (MalformedPolicyDocument) o aceptarlo y dejarte con un principal atado a un session name que cambia entre inicios de sesión. Hay que derivar el rol IAM permanente del permission set de SSO. Yo lo resolví con un local de Terraform que detecta SSO y traduce:
locals {
_caller_arn = data.aws_caller_identity.current.arn
_is_sso = startswith(split("/", local._caller_arn)[1], "AWSReservedSSO_")
caller_role_arn = local._is_sso ? format(
"arn:aws:iam::%s:role/aws-reserved/sso.amazonaws.com/%s",
data.aws_caller_identity.current.account_id,
split("/", local._caller_arn)[1]
) : local._caller_arn
}
Con el Admin policy correcto y los trust policies apuntando al rol SSO permanente, create_registry ahora termina en READY en menos de un minuto:

Status Ready, auth type AWS_IAM, ARN visible. Ahora podemos publicar records.
Cuatro descriptors, cuatro formas (y solo una está bien documentada)
Llegamos al hallazgo más rico del laboratorio: ningún descriptor del Registry tiene la forma “obvia”. MCP es el único confirmado contra documentación oficial y funciona al primer intento. Los otros tres — A2A, Skill, Custom — tienen formas que solo descubres cuando tu primer create_registry_record falla. Tres iteraciones de error después, llegas a la forma correcta.
Acá van los cuatro, con la forma que funciona en producción y el error que ibas a comer si llegabas con la inferencia natural.
MCP — el único bien documentado
control.create_registry_record(
registryId=registry_id,
name="stripe-payments-mcp",
descriptorType="MCP",
descriptors={
"mcp": {
"server": {"inlineContent": json.dumps({
"name": "auroracapital/stripe-payments-mcp",
"description": "Operaciones de pagos contra Stripe",
"version": "2.1.0"
})},
"tools": {"inlineContent": json.dumps({
"tools": [
{"name": "create_payment_intent", "description": "...", "inputSchema": {...}},
{"name": "issue_refund", "description": "...", "inputSchema": {...}},
]
})}
}
},
recordVersion="2.1",
)
server es obligatorio, tools es opcional. Ambos van con inlineContent que es un string JSON serializado. Confirmado contra docs oficiales — no tuve sorpresas con MCP.
A2A — falta el protocolVersion
Mi inferencia inicial del A2A AgentCard no incluía un campo que el Registry exige. El error real:
ValidationException: a2a.agentCard inlineContent does not match any supported version
El mensaje no menciona qué campo falta, solo dice “does not match any supported version”. El campo es protocolVersion, va al inicio del AgentCard, y es obligatorio:
agent_card = {
"protocolVersion": "0.3.0", # ← obligatorio, fácil de olvidar
"name": "auroracapital/customer-onboarding-agent",
"description": "Onboarding end-to-end de nuevos clientes retail",
"version": "1.2.0",
"url": "https://agents.aurora-capital.internal/onboarding",
"capabilities": {"streaming": True, "pushNotifications": True},
"defaultInputModes": ["text", "image"],
"skills": [...],
}
descriptors = {"a2a": {"agentCard": {"inlineContent": json.dumps(agent_card)}}}
El Registry sigue la especificación abierta de A2A, donde protocolVersion es obligatorio. Si construyes el AgentCard a mano (en lugar de generarlo desde un SDK A2A oficial), es fácil saltarlo.
⏳ Detalle de versión que vale la pena conocer: la spec A2A upstream ya liberó v1.0.0 y movió
protocolVersiondel top level del AgentCard asupportedInterfaces[].protocolVersion. El Registry hoy valida contra el shape anterior (protocolVersionen el top level con valores tipo0.3.0), así que si copias un AgentCard generado con un SDK A2A v1.0 vas a comerValidationException. Hasta que AWS actualice el schema soportado, el camino que funciona es el de este post: top level +0.3.0.
Skill — cuatro sorpresas en un solo descriptor
Este es el campeón de los errores secuenciales. Mi inferencia inicial chocó cuatro veces antes de llegar a la forma correcta.
Sorpresa 1: la key NO se llama skill. Botocore te corta antes de llamar a la API:
ParamValidationError: Unknown parameter in descriptors: "skill",
must be one of: mcp, a2a, custom, agentSkills
La key correcta es agentSkills en plural. Bien.
Sorpresa 2: adentro no va inlineContent directo. Hay sub-keys específicas:
ParamValidationError: Unknown parameter in descriptors.agentSkills: "inlineContent",
must be one of: skillMd, skillDefinition
Las sub-keys válidas son skillDefinition (JSON estructurado con metadata y package info) y skillMd (markdown con la documentación). Y el descriptor acepta las dos a la vez — de hecho, lo recomendado es mandar ambas porque el search indexa los dos lados.
Sorpresa 3: el enum del descriptorType en la API también es distinto. Probé con descriptorType="SKILL":
ValidationException: Value at 'descriptorType' failed to satisfy constraint:
Member must satisfy enum value set: [A2A, CUSTOM, MCP, AGENT_SKILLS]
El enum es AGENT_SKILLS (plural, con guion bajo), no SKILL. La inconsistencia entre la sub-key (agentSkills, camelCase) y el enum del descriptorType (AGENT_SKILLS, mayúsculas con guion bajo) es desafortunada pero hay que conocerla.
Sorpresa 4: el skillMd requiere YAML frontmatter al inicio. Mandé markdown plano:
ValidationException: agentSkills.skillMd inlineContent must start with frontmatter
delimited by '---'
Tu skillMd tiene que empezar con ---\n<YAML>\n---\n antes del cuerpo markdown. Si vienes del mundo de Jekyll, te suena familiar — es exactamente el patrón.
La forma final que funciona, después de las cuatro iteraciones:
control.create_registry_record(
registryId=registry_id,
name="pii-redaction-skill",
descriptorType="AGENT_SKILLS", # ← plural y mayúsculas
descriptors={
"agentSkills": { # ← plural y camelCase
"skillDefinition": {
"inlineContent": json.dumps({
"name": "pii-redaction",
"title": "PII Redaction Skill",
"version": "1.0.0",
"owner": "compliance@aurora-capital.internal",
"tags": ["compliance", "privacy", "pii", "redaction", "latam"],
"package": {
"type": "python",
"name": "aurora-pii-redaction",
"registry": "https://artifactory.aurora-capital.internal/pypi/",
"version": "1.0.0",
},
})
},
"skillMd": {
"inlineContent": (
"---\n"
"name: pii-redaction\n"
"version: 1.0.0\n"
"---\n\n"
"# PII Redaction Skill\n\n"
"Librería que aplica reglas regex + ML..."
)
},
}
},
recordVersion="1.0",
)
🔧 ProTip #4: De los cuatro descriptors del Registry, solo MCP funciona al primer intento. A2A te pide
protocolVersioncon un error críptico, AGENT_SKILLS te tira cuatro errores secuenciales (key plural, sub-keys específicas, enum distinto, frontmatter YAML), y Custom es el más limpio pero rompe el patrón de los otros tres. Si vas a publicar muchos records, escribe una capa que normalice cada tipo — ahorra horas.
Custom — sin sub-key, el más simple
El último descriptor cierra el patrón rompiéndolo. Mi inferencia natural fue {"custom": {"schema": {"inlineContent": ...}}} siguiendo la lógica de MCP y AGENT_SKILLS. Error:
ParamValidationError: Unknown parameter in descriptors.custom: "schema",
must be one of: inlineContent
Custom es plano. Sin sub-key intermedia:
descriptors = {
"custom": {
"inlineContent": json.dumps(payload)
}
}
Después de pelearte con AGENT_SKILLS, esta forma se siente como un alivio. Pero el costo es la inconsistencia: tres patrones distintos para cuatro tipos de record. Si AWS estabiliza esto antes de GA, espero que homologuen — pero mientras tanto, asume que ninguna forma es trivial.
Con las cuatro formas resueltas, los 8 records de Aurora Capital se publican sin más drama. Pasan de DRAFT a PENDING_APPROVAL cuando los enviamos para aprobación, y EventBridge dispara la notificación al Curator.
El flujo de aprobación real (con statusReason obligatorio)
El Curator recibe el correo vía SNS y ejecuta:
control = boto3.client("bedrock-agentcore-control") # firmado como Curator
control.update_registry_record_status(
registryId=registry_id,
recordId=record_id,
status="APPROVED",
statusReason="Cumple estándares de seguridad y naming. Documentación clara.",
)
Mi inferencia inicial usaba newStatus. La API es estricta y te lo dice:
ParamValidationError:
Missing required parameter in input: "status"
Missing required parameter in input: "statusReason"
Unknown parameter in input: "newStatus"
Dos hallazgos en uno: el parámetro es status (no newStatus), y statusReason es obligatorio en cualquier transición, incluyendo APPROVED. No puedes aprobar sin razón. La documentación del SDK no lo aclara como required, pero la API sí lo aplica.
💡 ProTip #5: El
statusReasonobligatorio en cualquier transición — incluso APPROVED — es una política de gobernanza aplicada por la API. Es brillante: cada decisión de aprobación deja un rastro de auditoría estructurado. La razón “ok” parece tentadora cuando estás aprobando 50 records seguidos, pero es exactamente la actitud que el Registry está desarmando. Trata la razón como contrato con tu yo del futuro: en seis meses, cuando alguien pregunte “¿por qué se aprobó esto?”, la respuesta está ahí.
Para el demo, aprobé 7 de los 8 records y rechazé slack-notifier-tool con razón:
control.update_registry_record_status(
registryId=registry_id,
recordId=slack_record_id,
status="REJECTED",
statusReason=(
"El endpoint mTLS no está en el catálogo de tools internos. "
"Documentar en confluence/internal-tools antes de re-submitir."
),
)
Resultado en consola:
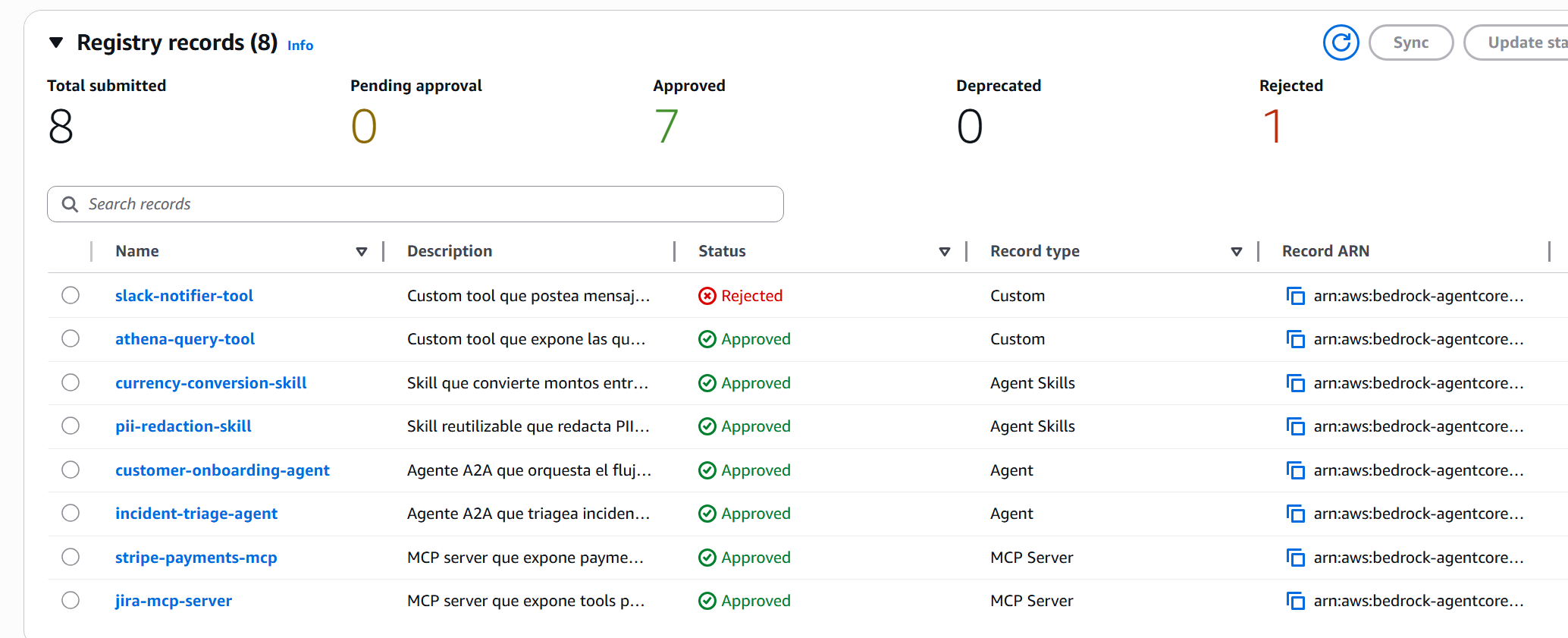
Los contadores de la consola — Total submitted 8, Approved 7, Rejected 1 — confirman el flujo. Y el slack-notifier-tool aparece como Rejected en la tabla con razón visible al hacer clic.
Acá vale destacar lo que pasa en negativo: el rol Publisher no puede ejecutar update_registry_record_status. El demo lo prueba explícitamente — intenté aprobar como Publisher y recibí AccessDeniedException. Cuando rompes la línea de las personas, el Registry te corta. Es exactamente el modelo que quieres en producción.
Búsqueda híbrida: la realidad detrás de la promesa “semántica”
Acá entramos en la sección donde el marketing y la ejecución divergen, y donde tu lectura honesta del producto vale más que la nota del anuncio. La documentación del Registry promete búsqueda híbrida: keyword y semántica corriendo en paralelo, con fusión de ranking, sobre los campos name, description y descriptors (incluyendo nombres de tools, descripciones, input schemas y capabilities).
Para entender qué hace la búsqueda en la práctica, probé 22 consultas distintas contra los 8 records aprobados; abajo muestro las 15 más reveladoras agrupadas por patrón. La conclusión es matizada y vale la pena documentarla.
Consultas cortas (1-3 palabras) → keyword puro de facto
| Consulta | Coincidencias | Comentario |
|---|---|---|
stripe |
stripe-payments-mcp |
✅ keyword en name |
payments |
stripe-payments-mcp |
✅ keyword en description |
payment (singular) |
— | ❌ sin stemming |
payment intent |
— | ❌ el orden de palabras importa |
payment processing |
— | ❌ |
cobrar (verbo) |
— | ❌ la descripción dice “cobro” (sustantivo), no “cobrar” |
issue refund |
jira-mcp-server |
🤔 “issue” es muy fuerte en jira |
Para consultas cortas, la parte semántica aporta poco. Stemming, expansión de sinónimos, separación de CamelCase — cosas que esperas de cualquier buscador moderno — no funcionan. El Registry te trata como grep.
Consultas naturales largas (5+ palabras) → ahí sí hay magia
| Consulta | Top hit | Comentario |
|---|---|---|
find me an agent that helps with new customer onboarding for retail clients |
customer-onboarding-agent |
✅ |
I want to redact PII from text before sending to an LLM |
pii-redaction-skill |
✅ |
tool to convert from MXN to USD |
currency-conversion-skill |
✅ |
agent for production incident triage and runbook suggestion |
incident-triage-agent |
✅ |
necesito procesar un pago en pesos mexicanos |
stripe-payments-mcp |
✅ multilingüe |
redactar información personal antes de pasarla a un LLM |
pii-redaction-skill |
✅ |
Acá sí: consultas largas en lenguaje natural — incluyendo las que están en español contra records descriptos mayormente en inglés — ranquean al record correcto. La búsqueda semántica multilingüe funciona y es el verdadero diferenciador del producto.
Pero el ranking se ensucia con keyword fuerte
| Consulta | Top hit obtenido | Top hit esperado |
|---|---|---|
I need to charge a customer in Mexican pesos |
jira-mcp-server |
stripe-payments-mcp |
how can I issue a refund to a customer |
jira-mcp-server |
stripe-payments-mcp |
Jira aparece primero en consultas de pagos porque las palabras issue y customer son muy frecuentes en las descripciones de sus tools, y el componente keyword del scoring las pesa demasiado. La parte semántica suma para Stripe pero no alcanza para superar el keyword en Jira.
🔍 ProTip #6: La “búsqueda semántica” del Registry es real pero condicional. Se activa de verdad solo con consultas naturales largas (5+ palabras) y se ensucia cuando dos records comparten palabras genéricas (
customer,issue,agent,tool). Eso define cómo describís tus records: haz descripciones específicas y evita vocabulario genérico que vaya a competir contra otros records de la organización. Y para los demos públicos, elige consultas deliberadamente largas — las cortas dan resultados que te van a hacer dudar del producto.
Hay un detalle adicional sobre consistencia eventual: durante el laboratorio vi cómo la consulta compliance pasaba de 1 a 2 coincidencias entre los primeros 3 minutos y los 15 minutos posteriores a la aprobación. El indexado de la búsqueda no es instantáneo. Si tu demo va a buscar inmediatamente después de aprobar, considera esperar un par de minutos antes de filmar.
La consola tiene su propia interfaz de búsqueda y muestra los 7 records aprobados con tarjetas visuales:
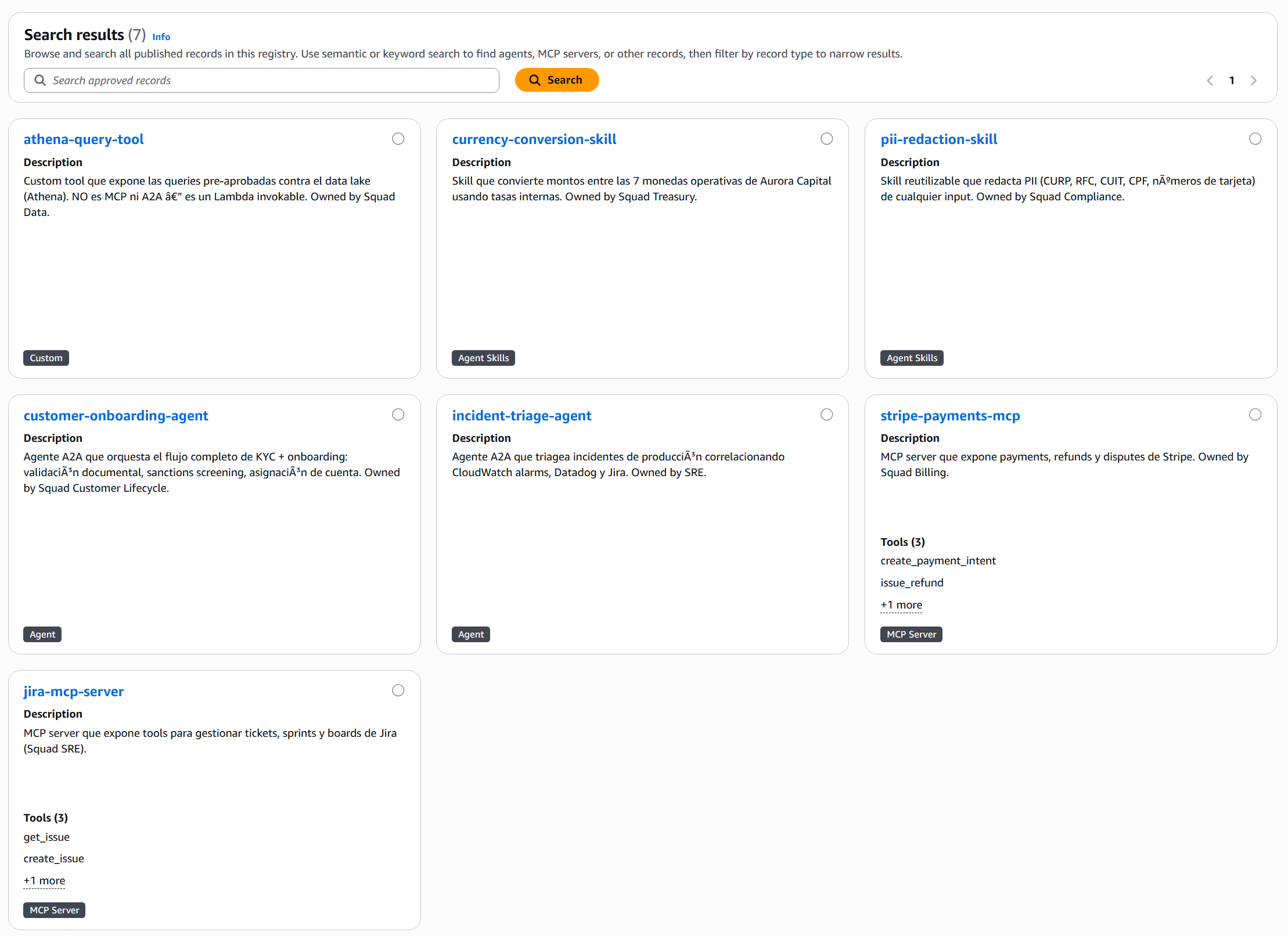
Notar que el slack-notifier-tool rechazado no aparece — es invisible para la búsqueda, exactamente como el modelo de gobernanza lo promete.
El cierre: Claude Code descubre tu organización
Hasta acá tenemos un catálogo construido, gobernanza aplicada por la API y búsqueda funcional. Falta la pregunta que importa: ¿cómo lo consume un desarrollador en su día a día? La respuesta es lo que hace popular al Registry: cualquier cliente MCP-compatible — incluido Claude Code — puede conectarse al Registry y descubrir agentes, tools y skills sin que el desarrollador abra la consola de AWS.
Hay tres pasos: (1) construir la URL del MCP endpoint, (2) firmar las requests con SigV4 porque el Registry usa AWS_IAM, (3) configurar el cliente MCP para que sepa hablar con eso.
La URL del endpoint, que la documentación no anuncia de forma obvia
get_registry() no devuelve un campo mcpEndpoint. La respuesta trae name, status, registryArn y poco más. El path del endpoint sigue una convención basada en path:
https://bedrock-agentcore.<region>.amazonaws.com/registry/<registryId>/mcp
Singular registry, no plural. Hay que construirlo a mano a partir del registryId. Verificable desde Python con requests + botocore.auth.SigV4Auth:
from botocore.auth import SigV4Auth
from botocore.awsrequest import AWSRequest
import boto3, requests, json
creds = boto3.Session().get_credentials().get_frozen_credentials()
endpoint = f"https://bedrock-agentcore.us-east-1.amazonaws.com/registry/{registry_id}/mcp"
payload = {"jsonrpc": "2.0", "id": 1, "method": "tools/list", "params": {}}
req = AWSRequest(method="POST", url=endpoint,
data=json.dumps(payload),
headers={"Content-Type": "application/json"})
SigV4Auth(creds, "bedrock-agentcore", "us-east-1").add_auth(req)
resp = requests.post(endpoint, data=req.body, headers=dict(req.headers))
Esto funciona desde Python. Pero Claude Code no soporta SigV4 nativo en transporte HTTP — espera stdio o HTTP simple sin firma AWS. Hay que poner un proxy en el medio.
El puente que faltaba: mcp-proxy-for-aws
AWS publicó un proxy oficial para este caso exacto: mcp-proxy-for-aws. Se ejecuta vía uvx, levanta un MCP server local en stdio y firma con SigV4 cada request al endpoint AWS. Eso lo vuelve invisible para el cliente MCP — Claude Code se conecta como si fuera cualquier MCP server stdio.
La configuración va en .mcp.json en la raíz del proyecto (alcance del proyecto):
{
"mcpServers": {
"aurora-capital-registry": {
"type": "stdio",
"command": "uvx",
"args": [
"mcp-proxy-for-aws@latest",
"https://bedrock-agentcore.us-east-1.amazonaws.com/registry/<registryId>/mcp",
"--service", "bedrock-agentcore",
"--region", "us-east-1"
]
}
}
}
Las credenciales las toma del entorno AWS estándar — un perfil que asume el rol Consumer del laboratorio. Si quieres blindar al cliente contra cualquier write accidental, agrégale --read-only a los args del proxy: deshabilita los tools que requieren permisos de escritura, lo cual encaja perfecto con la persona Consumer (descubre, consume, no muta). Reinicias Claude Code y el MCP server aurora-capital-registry aparece disponible con una única herramienta: search_registry_records.
🚀 ProTip #7:
mcp-proxy-for-awses la pieza que cierra el círculo entre AgentCore y los IDEs y agentes que hablan MCP. Sin él, conectar Claude Code a cualquier endpoint AgentCore que use AWS_IAM es manual y frágil. Con él, cualquier cliente MCP estándar se puede conectar de forma transparente. Vale la pena conocerlo aunque hoy no lo uses — es probable que cualquier integración futura entre AgentCore y herramientas externas pase por este proxy.
El momento que vale el viaje
Con la conexión activa, le tiré a Claude Code en el IDE:
“Find me an agent that helps with new customer onboarding for retail clients.”
Sin nombrar customer-onboarding-agent, sin saber qué Squad lo construyó, sin abrir Confluence. Claude consultó el Registry vía MCP y respondió:
Encontré exactamente lo que necesitas.
customer-onboarding-agentv1.2.0 (Aurora Capital, Squad Customer Lifecycle).
- Endpoint:
https://agents.aurora-capital.internal/onboarding- Capabilities: streaming + push notifications, input modes text + image (acepta foto del documento)
- Soporta: MX, CO, AR, BR, CL, PE
Tres skills disponibles:
kyc_document_validation— Valida cédula/INE/DNI según país, detecta forgery con OCRsanctions_screening— Cruza nombre + fecha de nacimiento contra OFAC, ONU, listas localesaccount_provisioning— Crea la cuenta en core banking, asigna producto inicialEs exactamente el flujo retail que pediste. Si quieres probarlo, manda un POST al endpoint A2A con un payload que invoque
kyc_document_validation.
Una sola pasada. El desarrollador recibió: el endpoint, las capacidades, los modos de entrada, las skills disponibles y una recomendación de cómo empezar. El Registry le devolvió el descriptor A2A completo embebido con todo el AgentCard, y Claude lo tradujo a una respuesta accionable.
Eso es lo que estoy llamando el “último kilómetro” del Registry: no es solo que el catálogo existe — es que el catálogo es consultable en el contexto donde el desarrollador ya está trabajando, en lenguaje natural, sin sobrecarga.
Esto es la imagen que te llevas del producto cuando funciona bien:
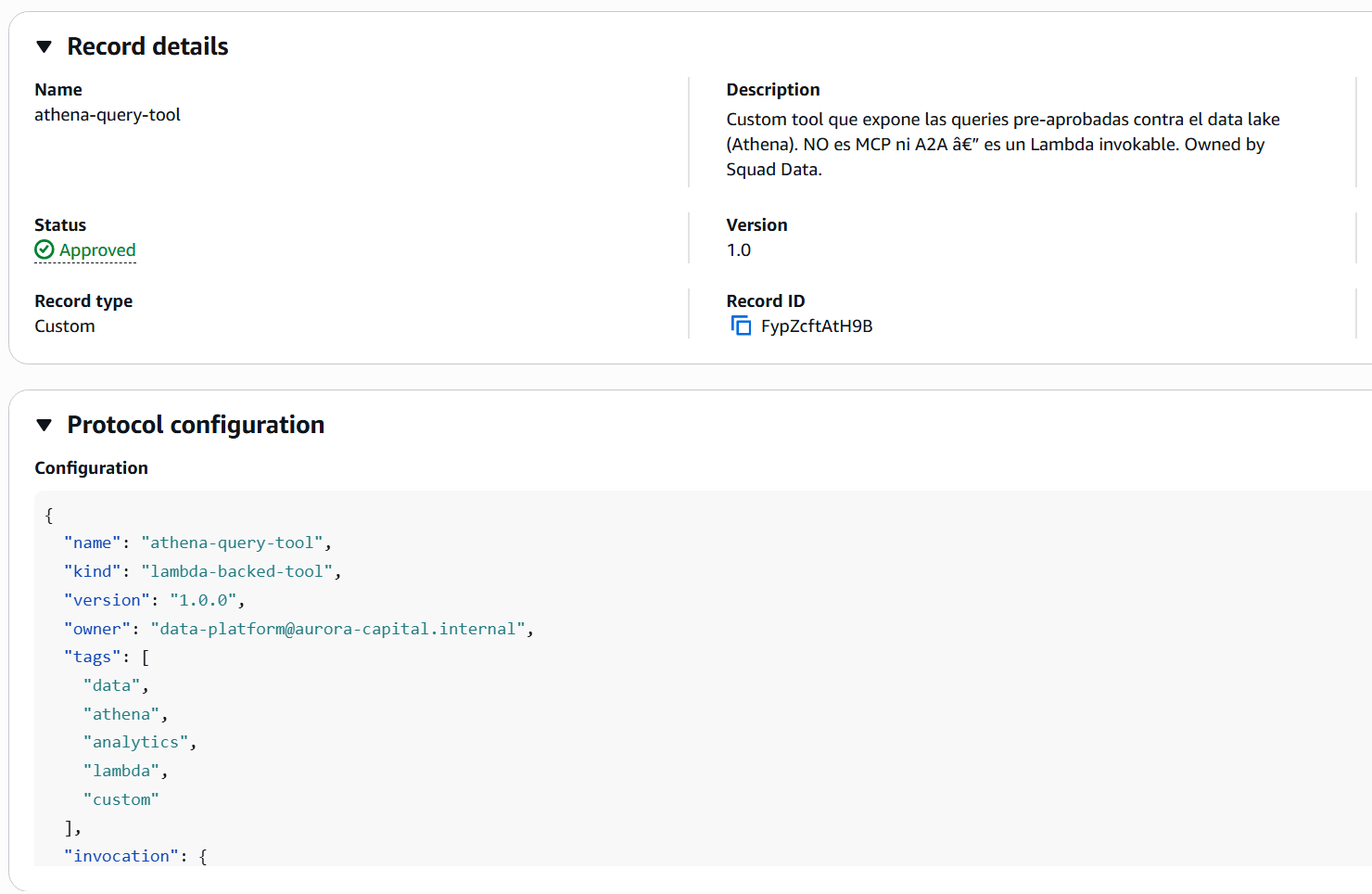
Cada record viene con todo lo que un consumer necesita — no solo nombre y descripción, sino el descriptor completo con schemas, endpoints e información del paquete. Una sola ida y vuelta, todo el contrato del recurso.
Lecciones aprendidas
Después de la semana del laboratorio, lo que me llevo en limpio sobre el producto y sobre cómo recomendarlo a clientes:
El modelo de las 4 personas es la decisión arquitectónica más fuerte del servicio. No es marketing — la separación se sostiene en IAM, los AccessDenied del demo son reales, y la disciplina que impone (Publisher no aprueba lo suyo, Curator no escribe contenido) mapea exactamente lo que quieres en gobernanza corporativa. Si tu organización ya tiene roles equivalentes para otros recursos AWS, mapearlos al Registry es directo.
Los descriptors no están listos para producción en preview. Tres de cuatro tipos requieren iteración a mano para descubrir la forma correcta. Vale la pena escribir una capa de envoltorio que normalice — vas a publicar los mismos tipos muchas veces y no quieres mantener cuatro patrones distintos en tu código base.
La búsqueda semántica tiene un punto óptimo estrecho. Funciona perfecto cuando el consumer hace consultas naturales largas (lo cual encaja bien con agentes conversacionales) y se rompe cuando le tiras palabras clave sueltas (lo cual descalifica buena parte del uso humano directo). Esa restricción está bien si el caso de uso primario es Claude Code, Kiro u otros agentes consultando el Registry. Es problemática si piensas en desarrolladores tirando grep desde la consola.
La brecha entre la API y la realidad de producción está en EventBridge y el SDK. EventBridge tiene el evento (Registry Record State Change) y la integración funciona, pero la documentación de la forma exacta del payload está rezagada respecto a la implementación. El SDK boto3 tiene los métodos pero la AWS CLI todavía está alcanzando el ritmo. El Terraform Provider no tiene los recursos. Estas tres brechas son típicas de servicios en preview — esperaría que se cierren antes de GA, pero hoy las tienes que sortear.
Costo cero durante el preview es el punto óptimo para empezar a adoptarlo ahora. Cuando Agent Registry pase a GA con precio por Net Records, vas a querer haberlo modelado y migrado tu inventario antes — no después. Esta ventana de meses sin costo es la oportunidad para que tu organización defina vocabulario, convenciones de nombres y disciplina de aprobación, sin presión financiera.
Lo que todavía no está
Para que tu mapa mental sea completo, esto no existe en el preview (aún) y vale la pena saber qué esperar:
- Auto-indexado de runtimes desplegados. Si tienes un agente en AgentCore Runtime, no se autopublica al Registry. Lo registras manualmente.
- Federación entre registries. Cada cuenta tiene sus propios registries; no hay forma nativa hoy de exponer un registry de la cuenta de Platform a las cuentas de los squads.
- Versionamiento avanzado. El Registry soporta
recordVersionpero no implementa diffing consciente de SemVer entre versiones. Tú marcas 1.0, 1.1, 2.0 — el Registry no te avisa si rompes compatibilidad. - Soporte completo en IaC. Ni Terraform, ni CDK, ni la AWS CLI tienen los recursos completos todavía. Solo SDK directo (Python/JS/Go) o consola.
- Métricas y tableros listos. CloudWatch tiene los logs pero no hay un tablero nativo del tipo “qué records son los más buscados, cuáles tienen más rechazos, etc.”.
La hoja de ruta obvia para AWS es cerrar todas estas brechas antes de GA. Si tu adopción depende de alguna de ellas, vale la pena planificar el piloto con eso en mente.
Conclusión
Si tienes más de tres equipos construyendo agentes en paralelo en tu organización, el momento para adoptar Agent Registry es exactamente este — antes de GA, mientras es gratis, mientras tu inventario es manejable. Cualquiera que llegue al Registry con 50 agentes va a tener que escribir un programa de migración antes de extraer valor; cualquiera que llegue con 8 lo va a integrar en un sprint.
El producto tiene aristas, sí. Cuatro descriptors con formas inconsistentes, una búsqueda semántica con punto óptimo estrecho, un Provider de Terraform que no llega todavía, un SDK que va por delante de la CLI. Pero el modelo conceptual — las 4 personas, el flujo de aprobación aplicado por la API, el MCP endpoint consumible desde cualquier cliente — es sólido y se siente como un servicio de plataforma, no como un experimento.
Y el cierre con Claude Code es el momento donde el retorno se vuelve obvio. Cuando un desarrollador puede preguntar en lenguaje natural “¿hay algún agente que haga X?” y recibir el contrato completo del recurso en una sola pasada, sin abrir Confluence ni preguntar en Slack, ahí es donde la inversión de gobernanza se paga sola.
🎓 ProTip #8: El catálogo previene la duplicación, pero solo si los Publishers son disciplinados al describir sus recursos. Haz descripciones específicas, usa vocabulario que tu Consumer ideal escribiría como consulta, evita palabras genéricas (
tool,agent,service) sin contexto. La búsqueda del Registry es tan buena como el peor descriptor que tengas indexado. Esa disciplina la imponen los Curators en la aprobación — usa el rechazo con razón concreta para enseñar a tus Publishers a escribir buenas descripciones.
El repositorio completo del laboratorio está en github.com/codecr/bedrock-agent-registry — Terraform para los 4 roles IAM y EventBridge, Python para registry y records, los 8 records de Aurora Capital con las formas corregidas, y la .mcp.json de Claude Code lista para usar. Si quieres reproducir el laboratorio en tu cuenta, necesitas boto3 ≥ 1.42.87 y BedrockAgentCoreFullAccess en el rol que ejecuta el primer create_registry.
Si te quedaste con ganas de algo más sobre la pila Bedrock + GenAI, te dejo mi post anterior — el benchmark real de las 5 estrategias de chunking en Bedrock Knowledge Bases — donde aplico el mismo patrón de “manos a la obra con todas las sutilezas honestas” pero del lado de RAG.
Y si estás del lado donde esto resuena — donde tienes varios equipos construyendo agentes en paralelo y no quieres esperar a tener 50 para empezar a poner orden — me encantaría escuchar tu caso. ¿Cómo se ve tu inventario de agentes hoy? ¿Quién tomaría el rol de Curator en tu organización? ¿Hay algún squad que ya esté duplicando capacidades sin darse cuenta?
Comenta abajo o escríbeme por LinkedIn.
¡Nos vemos en el próximo artículo! 🚀



Inicia la conversación