

Table of Contents
Curiosity as the Engine of Exploration
The arrival of Intelligent Prompt Routing in Amazon Bedrock sparked my technical curiosity. How does it actually decide which model to use? How effective are these decisions? Without a specific use case in mind, I decided to dive into a hands-on exploration from the AWS console to understand its capabilities and limitations.
What is Intelligent Prompt Routing?
Amazon Bedrock Intelligent Prompt Routing is a feature that provides a single serverless endpoint to efficiently route requests between different foundation models within the same family. The router predicts each model’s performance for each request and dynamically directs each query to the model most likely to deliver the desired response at the lowest cost.
During the preview phase, this feature is available for:
- Anthropic family (Claude 3.5 Sonnet and Claude 3 Haiku)
- Meta Llama family (70B and 8B)
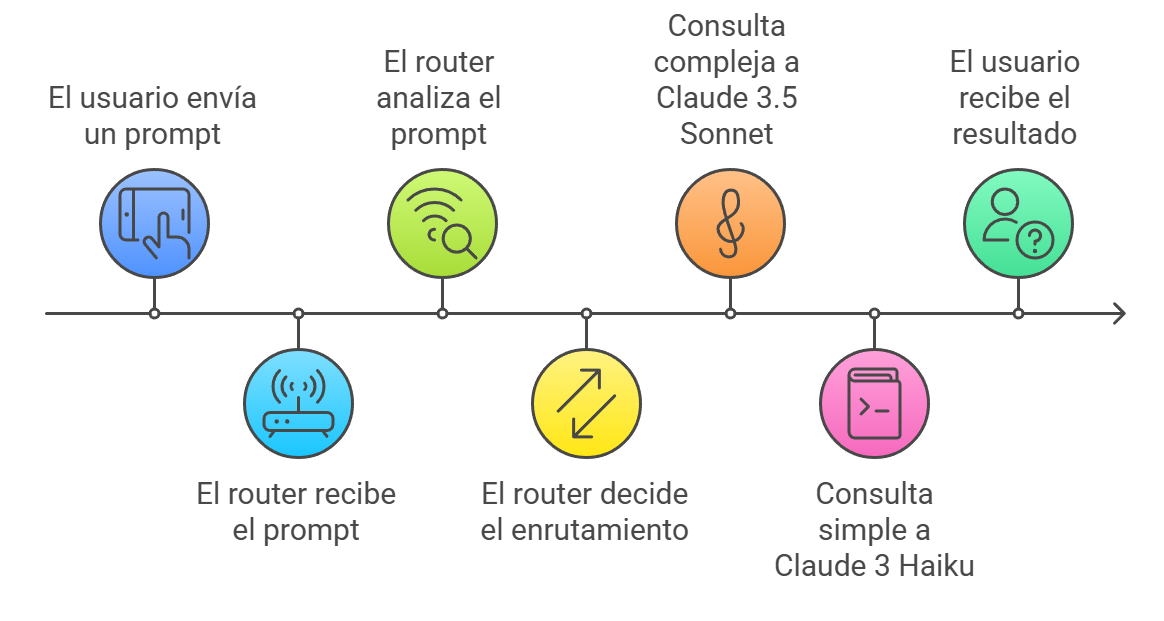 Figure 1: Diagram showing the Intelligent Prompt Routing decision flow. The router analyzes each request and directs it to the most appropriate model based on its performance and cost prediction.
Figure 1: Diagram showing the Intelligent Prompt Routing decision flow. The router analyzes each request and directs it to the most appropriate model based on its performance and cost prediction.
Setting the Stage: Initial Configuration
The first step is accessing the AWS console and navigating to Bedrock. During this exploration, we’ll work in the US East (N. Virginia) region, where we have access to the required models.
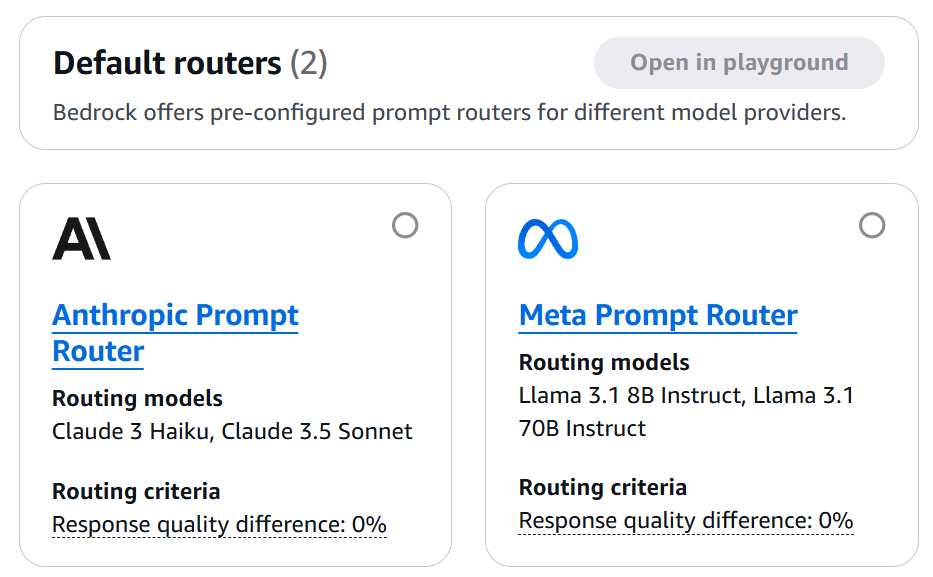 Figure 2: Amazon Bedrock main panel showing the Prompt Routers section. This is where our exploration begins.
Figure 2: Amazon Bedrock main panel showing the Prompt Routers section. This is where our exploration begins.
Accessing the Prompt Router
- In the left panel, select “Prompt routers”
- Locate the “Anthropic Prompt Router”
- Notice the available models:
- Claude 3.5 Sonnet
- Claude 3 Haiku
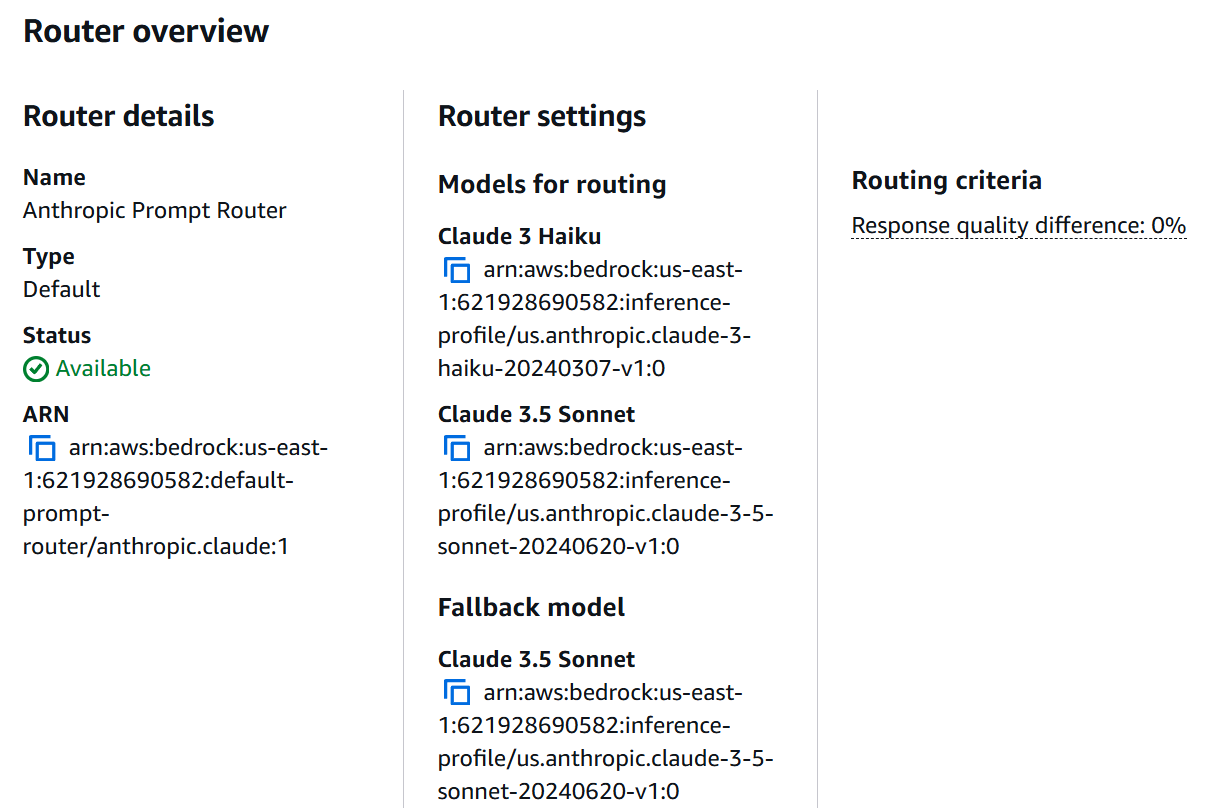 Figure 3: Anthropic Prompt Router configuration showing available models and their settings.
Figure 3: Anthropic Prompt Router configuration showing available models and their settings.
Hands-On: Practical Tests
To truly understand how routing works, I designed a set of tests that anyone can easily replicate from the console:
Scenario 1: Basic AWS Queries
Let’s start with simple questions about AWS:
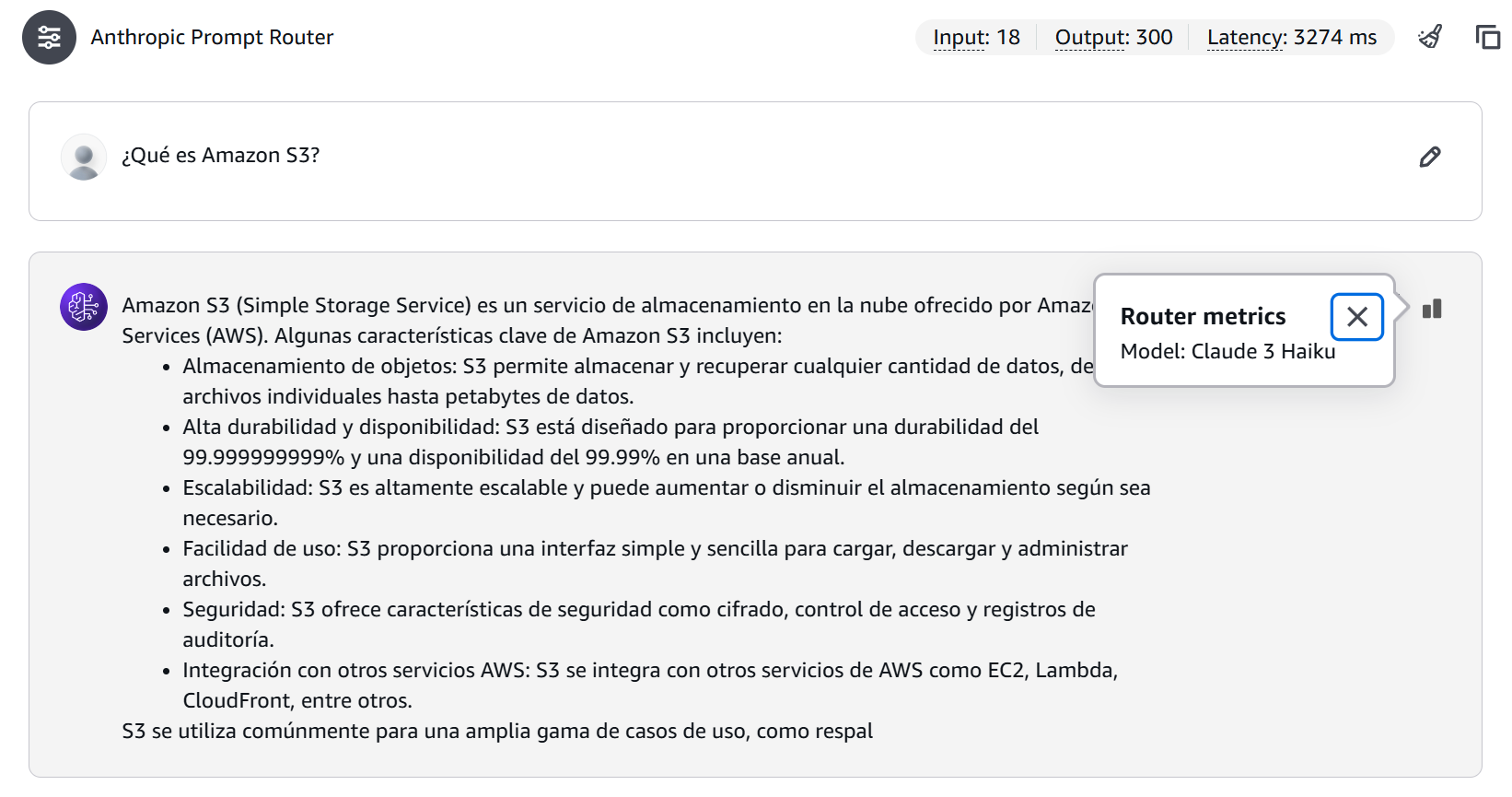 Figure 4: Simple query result showing Claude Haiku selection and token consumption.
Figure 4: Simple query result showing Claude Haiku selection and token consumption.
In this case the selected model was Claude 3 Haiku, with a total of 18 input tokens, 300 output tokens, and a latency of 3274 ms.
Scenario 2: Architectural Analysis
Now, let’s try something more complex:
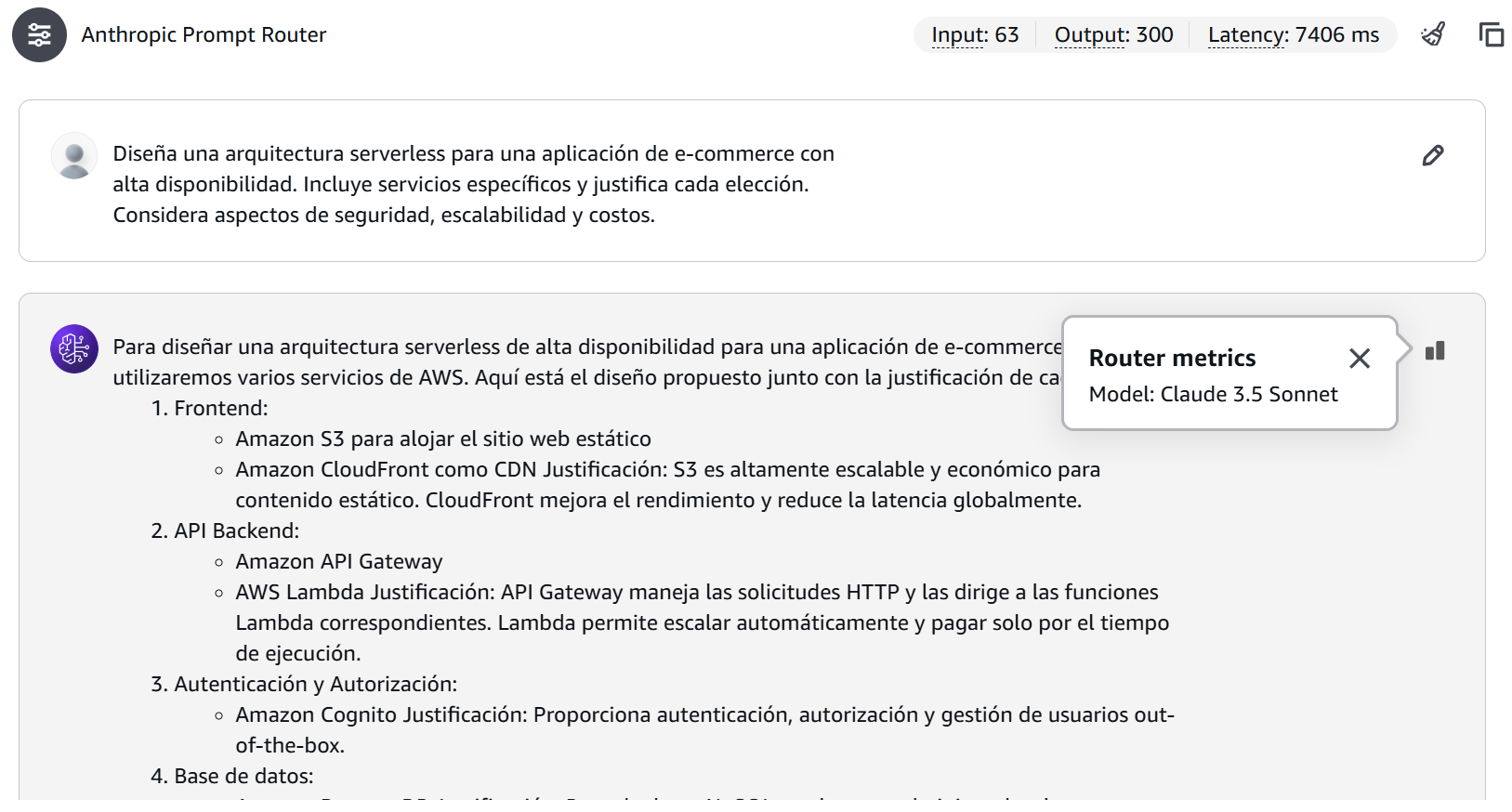 Figure 5: Complex query result showing Claude Sonnet selection and higher token consumption.
Figure 5: Complex query result showing Claude Sonnet selection and higher token consumption.
In this other scenario, the selected model was Claude Sonnet 3.5, with a total of 63 input tokens, 300 output tokens, and a latency of 7406 ms.
Observations and Patterns
During the tests, clear patterns emerged about when the router chooses each model:
Claude Haiku tends to be selected for:
- Direct questions and definitions
- Queries about specific services
- Responses requiring fewer output tokens
Claude Sonnet tends to be chosen for:
- Complex architectural designs
- Detailed analyses
- Responses requiring more output tokens
Cost and Performance Analysis
A crucial aspect when evaluating the Intelligent Prompt Router is understanding its cost impact. Let’s analyze the simple query case comparing Haiku vs Sonnet.
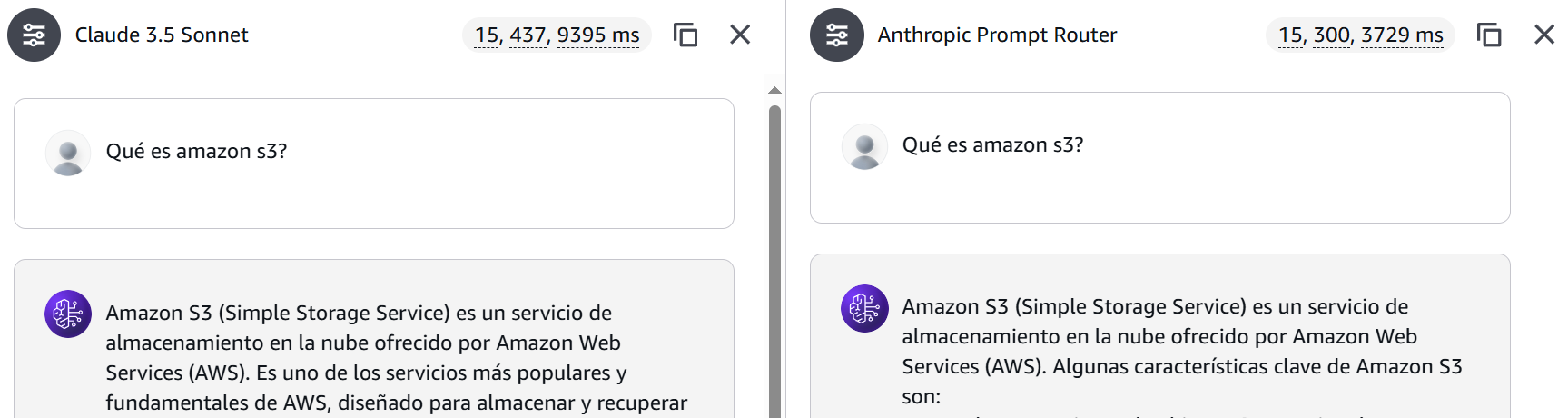 Figure 6: Simple query comparison.
Figure 6: Simple query comparison.
Scenario 1: Simple Query (Claude 3 Haiku)
- Input tokens: 15
- Output tokens: 300
- Latency: 3,729 ms
Cost calculation:
- Input cost: 15 * ($0.00025/1000) = $0.00000375
- Output cost: 300 * ($0.00125/1000) = $0.000375
- Total cost: $0.00037875
Scenario 2: Simple Query (Claude 3.5 Sonnet)
- Input tokens: 15
- Output tokens: 437
- Latency: 9,395 ms
Cost calculation:
- Input cost: 15 * ($0.003/1000) = $0.000045
- Output cost: 437 * ($0.015/1000) = $0.006555
- Total cost: $0.0066
Efficiency Comparison
| Claude 3 Haiku | Claude 3.5 Sonnet | |
|---|---|---|
| Total Cost | $0.00037875 | $0.0066 |
| Latency | 3,729 ms | 9,395 ms |
| Tokens Processed | 315 | 452 |
🔍 ProTip: The router appears to prioritize Haiku for simple queries, which is cost-effective considering it’s approximately 17.4 times cheaper than Sonnet for this type of interaction.
Production Implications
- Cost Optimization
- Simple queries processed by Haiku represent significant savings
- The per-query cost with Sonnet is justified for complex analyses
- Performance-Cost Balance
- Haiku offers better performance (~5 seconds faster) and lower cost
- The router’s selection of Sonnet is justified by complex analysis needs, not speed considerations
- Scalability Considerations
- At scale, the cost difference can be substantial
- For example, for 1 million simple queries:
- With Haiku: ~$378.75
- With Sonnet: ~$6,600.00
- Potential savings: $6,221.25
💰 Cost Impact: Using Haiku for simple queries represents a 94.26% savings compared to Sonnet. For one million similar queries, this could translate to savings of over $6,221.
This cost information highlights the importance of intelligent routing in resource and budget optimization, especially in large-scale implementations.
Programmatic Analysis
If you want to explore the router’s behavior more deeply, here’s a Python script you can use:
import boto3
import json
from datetime import datetime
class PromptRouterAnalyzer:
def __init__(self, region_name='us-east-1'):
self.bedrock_runtime = boto3.client('bedrock-runtime', region_name=region_name)
self.bedrock = boto3.client('bedrock', region_name=region_name)
self.router_arn = self._get_router_arn()
def _get_router_arn(self):
"""
Gets the ARN of the Anthropic Prompt Router.
"""
try:
response = self.bedrock.list_prompt_routers()
for router in response['promptRouterSummaries']:
if router['promptRouterName'] == 'Anthropic Prompt Router':
return router['promptRouterArn']
raise Exception("Anthropic Router not found")
except Exception as e:
print(f"Error getting router ARN: {str(e)}")
raise
def analyze_prompt(self, prompt):
request_body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": prompt
}
]
}
response = self.bedrock_runtime.invoke_model(
modelId=self.router_arn,
body=json.dumps(request_body)
)
response_body = json.loads(response['body'].read())
return {
'model_used': response_body.get('model', 'Unknown'),
'tokens': {
'input': response_body.get('usage', {}).get('input_tokens', 0),
'output': response_body.get('usage', {}).get('output_tokens', 0)
}
}
Conclusions and Reflections
After this hands-on exploration of Intelligent Prompt Routing, significant conclusions emerge across several aspects:
1. Model Selection Efficiency
- The router demonstrates precision in directing simple queries to Haiku and complex analyses to Sonnet
- The selection optimizes not only costs but also response times
- Routing decisions appear to consider both complexity and prompt length
2. Financial Impact
- Tests reveal a potential savings of 94.26% when using Haiku for appropriate queries
- At enterprise scale (1 million queries):
- Haiku scenario: $378.75
- Sonnet scenario: $6,600.00
- Potential savings: $6,221.25
- The cost difference is especially relevant in high-volume applications
3. Performance and Latency
- Haiku is not only cheaper but also faster for simple queries
- Haiku: ~3.7 seconds
- Sonnet: ~9.3 seconds
- The latency reduction can have a significant impact on user experience
4. Implementation Considerations
- Prompt Optimization:
- Structure queries clearly and concisely
- Use English to ensure optimal router functioning
- Usage Monitoring:
- Track model selection patterns
- Analyze costs and token consumption
- Continuously evaluate routing effectiveness
5. Limitations and Areas for Improvement
- Exclusive support for English prompts
- Limited visibility into the router’s decision criteria
- Limited set of available models during preview
🚀 Final ProTip: To maximize the benefits of Intelligent Prompt Routing, it’s crucial to analyze your application’s usage patterns. A 94.26% savings in operational costs can be the difference between a viable project and one that exceeds its budget.
Amazon Bedrock’s Intelligent Prompt Routing proves to be a valuable tool for optimizing both performance and costs in AI applications. Its ability to automatically direct queries to the most appropriate model not only simplifies architecture but can also result in significant savings at scale. For use cases requiring multi-step reasoning or external tool usage, consider complementing this strategy with Amazon Bedrock Agents, which adds orchestration capabilities on top of the selected model.
Have you implemented Intelligent Prompt Routing in your organization? What usage patterns and savings have you observed? Share your experiences in the comments.



Start the conversation