

Table of Contents
- The Fundamental Problem: When Creativity Becomes Dangerous
- The Automated Reasoning Revolution: Beyond Probabilities
- Setting Up Our Testing Lab
- Step-by-Step Implementation: From Policies to Formal Logic
- Step 1: Creating the Base Guardrail
- Step 2: Configuring the Automated Reasoning Policy
- Loading Policy Documents
- The Automatic Extraction Process: From Natural Language to Formal Logic
- Navigating the Extracted Definitions
- Formal Logic Rules in Action
- Variables and Custom Types
- Critical Warning: Non-If-Then Rules Can Cause Unintended Consequences
- The Power of Mathematical Verification
- Integrated Testing System
- Advanced Configuration in Guardrails
- Step 3: Implementing and Testing the Python Client
- Step 4: Refinement with Annotations - Correcting Policies Through Iterative Testing
- Step 5: Additional Test Cases
- Validation Result Types 📋
- Results Analysis: Verifiable Precision vs Probabilities 📊
- Current Limitations and Considerations 🚧
- When Automated Reasoning is NOT Effective
- Final Reflections: The Future of Verifiable AI 🔮
Amazon Bedrock Guardrails Automated Reasoning Checks: When Mathematics Defeats Hallucinations
A few months ago, while presenting a demo of an AI assistant for financial processes, I experienced one of those moments every generative AI developer dreads: the model, with absolute confidence, informed me that “according to company policies, employees can take up to 45 consecutive vacation days without prior approval.”
The problem was obvious to anyone familiar with the real policies: the maximum allowed was 10 days. But the model had “hallucinated” a response that sounded perfectly reasonable, following corporate language patterns, yet was completely incorrect.
That frustrating experience led me to search for solutions that could improve factual accuracy in critical applications. And that search brought me to Amazon Bedrock Guardrails Automated Reasoning Checks — a feature that promises something revolutionary: formal mathematical verification with high precision to eliminate LLM hallucinations.
The Fundamental Problem: When Creativity Becomes Dangerous
The Dual Nature of LLMs
Large language models have demonstrated extraordinary capabilities for generating coherent and contextually relevant content. Their strength lies precisely in their ability to predict text sequences based on probabilistic patterns learned during training.
However, this same creative capability becomes a critical weakness when we need precise and verifiable answers. The model doesn’t “know” when it’s inventing information; it simply generates the most likely text sequence based on its training.
Real Examples of Costly Hallucinations
Over my years working with generative AI, I’ve documented common patterns of hallucinations that can have serious consequences:
Invented Business Policies:
- “New employees are entitled to 6 months of paid medical leave”
- “Purchases over $500 require 3 executive approvals”
- “The standard probation period is 180 days”
Incorrect Financial Regulations:
- “International transactions are exempt from reporting up to $25,000”
- “VIP customers can exceed credit limits by up to 300%”
- “Interest rates can be retroactively modified up to 6 months”
Altered Security Procedures:
- “In emergencies, two-factor authentication can be skipped”
- “Sensitive data can be temporarily stored without encryption”
- “Access keys automatically expire after 12 months”
Each of these responses sounded plausible, followed correct linguistic patterns, but was factually incorrect and potentially dangerous.
🔍 ProTip: The most dangerous hallucinations are not obviously wrong responses, but those that sound so plausible they go unnoticed until they cause real problems.
Critical Security Warning:
Automated Reasoning Checks do NOT protect against prompt injection attacks.
According to official AWS documentation:
“Automated Reasoning checks in Amazon Bedrock Guardrails validate exactly what you send them - if malicious or manipulated content is provided as input, the validation will be performed on that content as-is (garbage-in, garbage-out).”
What does this mean?
- Automated Reasoning validates the mathematical accuracy of content
- It does NOT validate whether content was maliciously manipulated
- An attacker could inject prompts that pass mathematical verification but contain malicious instructions
Required Protection:
You must use Content Filters in combination with Automated Reasoning for complete protection:
- Content Filters: Detect and block prompt injection and malicious content
- Automated Reasoning: Verify factual accuracy against formal policies
Never use Automated Reasoning as your only line of defense in production.
The Automated Reasoning Revolution: Beyond Probabilities
What is Automated Reasoning Checks?
Amazon Bedrock Guardrails Automated Reasoning Checks represents a paradigm shift in AI safety. Instead of relying solely on traditional probabilistic methods, it uses formal mathematical verification to validate LLM responses against defined business policies.
The fundamental difference is extraordinary:
- Traditional methods: “I have 85% confidence in this response”
- Automated Reasoning: “This response is mathematically verifiable as correct or incorrect”
📚 What is SMT-LIB?: It’s a standard language for expressing formal logic problems that can be solved by mathematical “solvers.” Think of it as the SQL of formal verification — a structured language that enables representing and solving complex logical problems through precise mathematical techniques.
Verifiable Data on LLM Precision
Recent research documents the actual hallucination rates in different contexts:
Top Models in Summarization Tasks (Vectara Hallucination Leaderboard, updated September 2025):
- GPT-5: ~1-2% hallucination rate
- Gemini-2.5 Pro: ~1-2% hallucination rate
- Claude 4: ~1-2% hallucination rate
Medical Reference Generation (JMIR, 2025):
- GPT-4: 28.6% hallucination rate
- GPT-3.5: 39.6% hallucination rate
Open Domain Questions (HaluEval, 2025):
- Gemini-2.0-Flash-001: 0.7% hallucination rate
- ChatGPT/Claude (recent versions): 40-50% hallucination rate
Automated Reasoning with well-structured policies: Up to 99% mathematically verifiable accuracy, according to official AWS announcements from the AWS blog.
🔍 ProTip: This 99% figure comes from AWS data; in real testing, it varies based on policy quality. Always verify in your own environment.
The Hybrid Architecture
The feature combines two worlds that have traditionally operated separately:
-
Natural Language Understanding: LLMs process and understand queries in natural human language.
-
Formal Mathematical Verification: Symbolic reasoning engines mathematically validate content against formal logical rules.
This hybrid architecture allows the system to:
- Automatically extract policies from business documents
- Translate natural language rules into formal logical representations
- Generate verifiable mathematical proofs
- Provide understandable explanations of why responses are correct or incorrect
Validation Process:
AWS uses multiple LLMs to translate natural language to formal logic. It only returns ‘findings’ where a significant percentage of LLMs agree on the translation, ensuring greater precision.
 Figure 1: Hybrid architecture combining LLMs with formal mathematical verification
Figure 1: Hybrid architecture combining LLMs with formal mathematical verification
Setting Up Our Testing Lab
Prerequisites
To follow this practical implementation, you’ll need:
- Access to Amazon Bedrock with Guardrails enabled
- Permissions to create and manage guardrails
- A foundation model of your choice (we’ll use Claude Sonnet)
- Business policy documents in PDF format
- AWS CLI or boto3 configured with appropriate credentials
Initial Configuration
First, we access the Amazon Bedrock console, where you’ll notice that Automated Reasoning appears as a standalone service in the Bedrock menu, under the “Build” section. This reflects the strategic importance AWS places on this feature, positioning it alongside Agents, Flows, and Knowledge Bases.
 Figure 2: Automated Reasoning as a standalone service in the Bedrock console
Figure 2: Automated Reasoning as a standalone service in the Bedrock console
 Figure 3: Automated Reasoning initial screen showing configured policies
Figure 3: Automated Reasoning initial screen showing configured policies
Cross-Region Inference: Transparent Performance Optimization
Before diving into implementation, it’s important to understand how Automated Reasoning optimizes policy processing through cross-region inference.
Automated Reasoning automatically distributes certain operations across multiple AWS regions within your geographic boundary to ensure availability and optimal performance.
Two specific API operations use this mechanism:
StartAutomatedReasoningPolicyBuildWorkflow: During policy creation and compilation from source documentsStartAutomatedReasoningPolicyTestWorkflow: During policy validation and testing
🔒 Important: Your data remains within the geographic boundary of origin (United States or European Union). Cross-region inference only routes requests within the same geographic boundary to optimize performance — it never crosses between US and EU.
Step-by-Step Implementation: From Policies to Formal Logic
Step 1: Creating the Base Guardrail
We start by creating a new guardrail that will serve as the container for our automated reasoning policies:
 Figure 4: Base Guardrail definition
Figure 4: Base Guardrail definition
Make sure Cross Region inference is enabled — it’s a requirement for using automated reasoning.
Step 2: Configuring the Automated Reasoning Policy
The core of the feature lies in configuring automated reasoning policies. This is where we define the rules the system must mathematically verify.
Loading Policy Documents
I’ve prepared three complete business policy documents you can use for testing. They’re available in my GitHub repository:
- Vacation & Leave Policy: Vacation, leave, and holiday policies
- Expense & Procurement Policy: Expense rules and approval workflows
- Remote Work & Security Policy: Remote work and security policies
For this example, we’ll use the Vacation & Leave Policy.
💡 ProTip: Policy documents can have up to 122,880 tokens (approximately 100 pages). The system will automatically extract variables, rules, and custom types from the text to create formal logical representations.
The Automatic Extraction Process: From Natural Language to Formal Logic
Once we upload our PDF document to Bedrock, something very interesting happens:
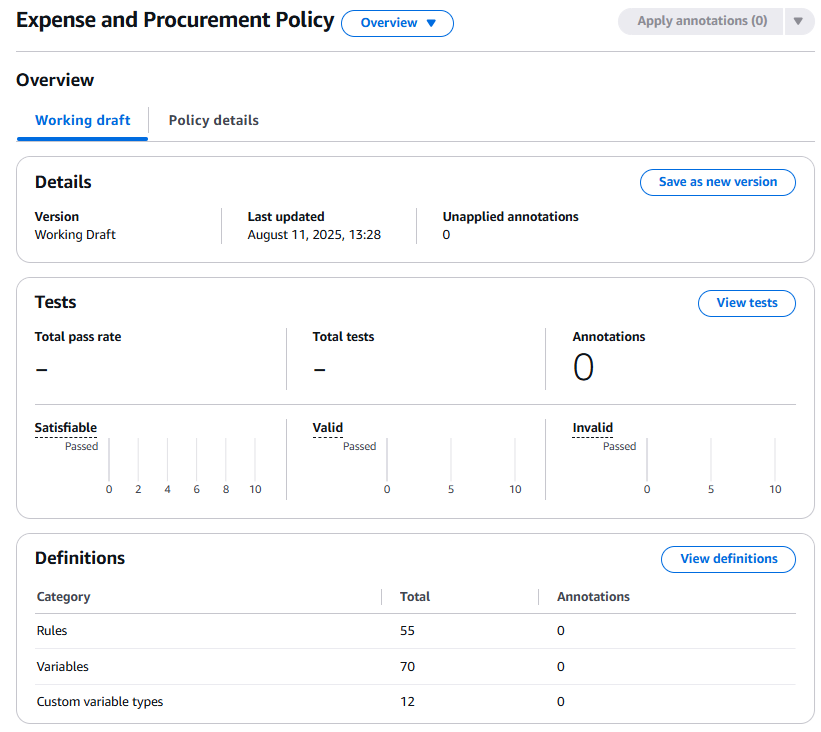 Figure 5: Policy overview showing automatic extraction of rules
Figure 5: Policy overview showing automatic extraction of rules
Automatic Extraction Analysis:
The image shows that Bedrock automatically processed our “Expense and Procurement Policy” document and extracted:
- 55 formal logic rules — Each business policy converted to verifiable logic
- 70 variables — Elements like
accommodationCostPerNight,accommodationType, etc. - 12 custom variable types — Categories like
AccommodationType,FlightClass,MealType
Navigating the Extracted Definitions
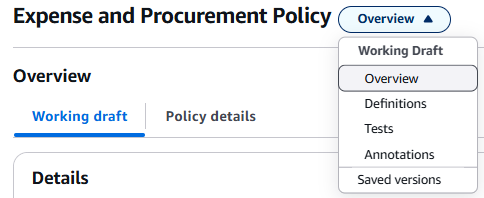 Figure 6: Navigation menu showing available sections for analysis
Figure 6: Navigation menu showing available sections for analysis
The system organizes extracted information into clearly defined sections:
- Overview: General extraction statistics
- Definitions: Extracted rules and variables
- Tests: Automatically generated validation scenarios
- Annotations: Manual annotations and improvements
- Saved versions: Policy version control
Formal Logic Rules in Action
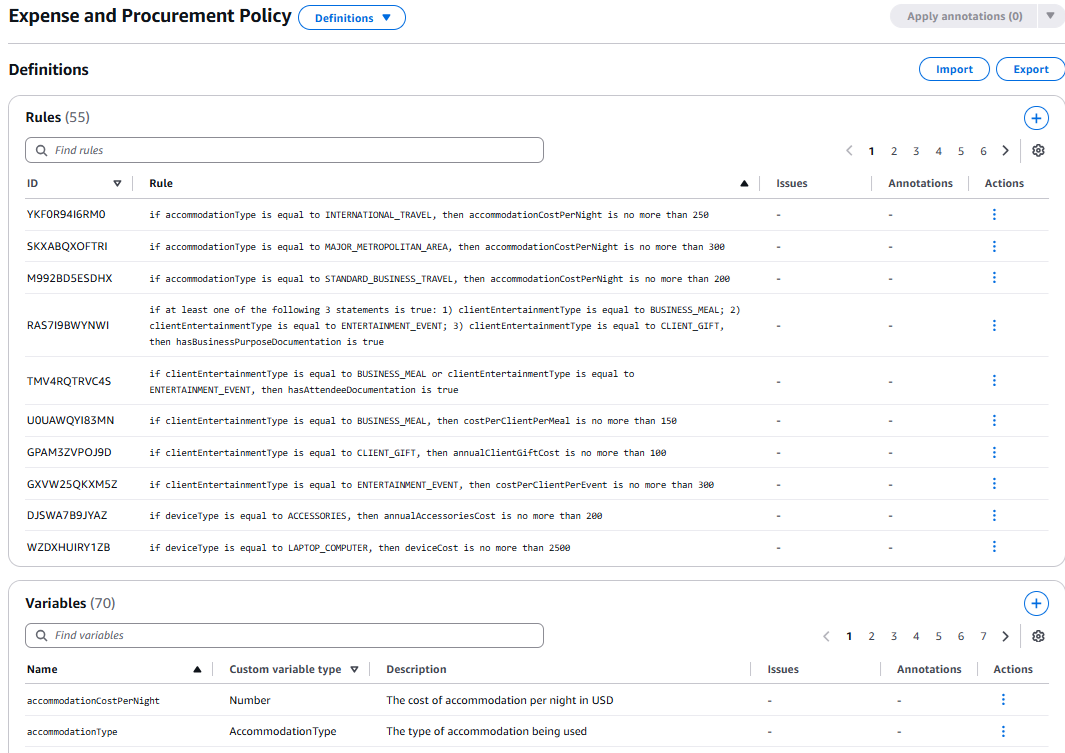 Figure 7: Formal logic rules automatically extracted from the document
Figure 7: Formal logic rules automatically extracted from the document
Here we see the true magic of the system. Each rule shows how natural language text was converted to formal logic:
Texto original: "International travel accommodation: Maximum $250 per night"
Regla extraída:
if accommodationType is equal to INTERNATIONAL_TRAVEL,
then accommodationCostPerNight is no more than 250
Examples of Rules Extracted from Our Document:
-
YKFOR94I6RMO:
if accommodationType is equal to INTERNATIONAL_TRAVEL, then accommodationCostPerNight is no more than 250 -
SKXABQXOFTRI:
if accommodationType is equal to MAJOR_METROPOLITAN_AREA, then accommodationCostPerNight is no more than 300 -
M992BD5ESDHX:
if accommodationType is equal to STANDARD_BUSINESS_TRAVEL, then accommodationCostPerNight is no more than 200
These rules correspond exactly to our document where we specified:
- Standard accommodation: $200/night
- Major metropolitan areas: $300/night
- International travel: $250/night
Variables and Custom Types
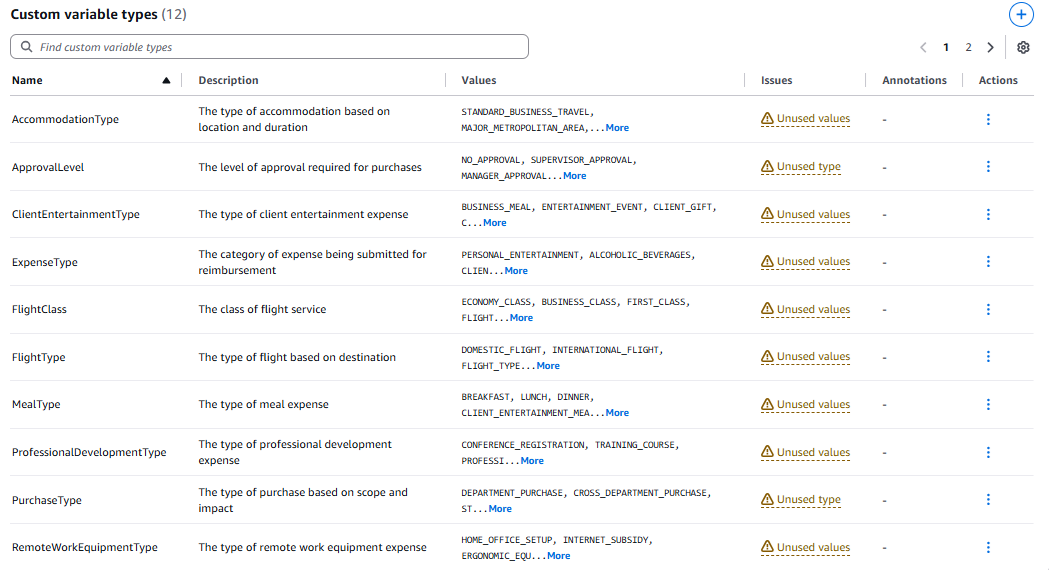 Figure 8: Variables and custom types extracted from business context
Figure 8: Variables and custom types extracted from business context
The system automatically identified business variable types like:
- AccommodationType:
STANDARD_BUSINESS_TRAVEL,MAJOR_METROPOLITAN_AREA,INTERNATIONAL_TRAVEL - FlightClass:
ECONOMY_CLASS,BUSINESS_CLASS,FIRST_CLASS - MealType:
BREAKFAST,LUNCH,DINNER,CLIENT_ENTERTAINMENT_MEAL
🔍 Technical Insight: This automatic extraction demonstrates that the system doesn’t just identify numbers and rules — it understands the semantic context of business policies, creating a complete domain ontology.
Critical Warning: Non-If-Then Rules Can Cause Unintended Consequences
During rule extraction, it’s crucial to understand a fundamental limitation that can cause unexpected results:
Rules that are NOT in if-then format can have unintended consequences by establishing absolute axioms about the world.
The problem:
❌ REGLA PELIGROSA (no if-then):
accountBalance > 5
Consecuencia: Se vuelve LÓGICAMENTE IMPOSIBLE que el balance de una cuenta
sea 5 o menos, sin importar qué dice el contenido a validar.
This rule establishes an axiom — an absolute truth in the logical model. If your policy contains accountBalance > 5 as an absolute rule, the system will treat any mention of a balance ≤5 as a logical contradiction, even if the user legitimately asks about accounts with low balances.
Correct format:
✅ REGLA CONDICIONAL (if-then):
if accountType is equal to PREMIUM, then accountBalance is greater than 5
Esto describe una RELACIÓN, no un axioma absoluto.
Always structure rules as conditional (if-then) statements that describe relationships between variables, not absolute restrictions on individual values.
The Power of Mathematical Verification
The most interesting part of this process is that each extracted rule can now be mathematically verified. When a user asks:
“What’s the maximum hotel cost for international travel?”
The system:
- Identifies that it refers to
accommodationType = INTERNATIONAL_TRAVEL - Looks up rule
YKFOR94I6RMO - Returns mathematically:
accommodationCostPerNight ≤ 250 - Provides the answer: “$250 per night” with 99% certainty
Integrated Testing System
One of the most powerful features is the integrated testing system that allows validating extracted policies:
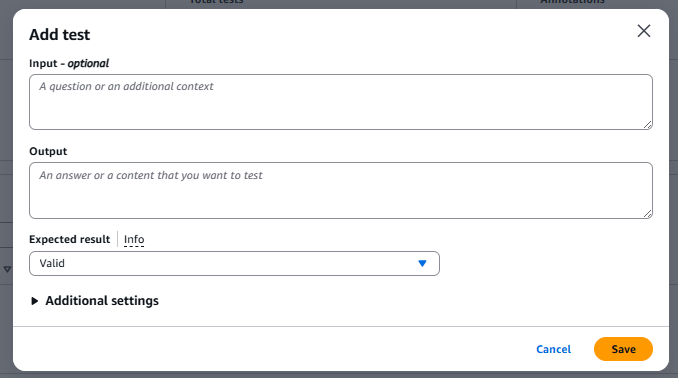 Figure 9: Testing interface for validating policies with confidence threshold
Figure 9: Testing interface for validating policies with confidence threshold
Testing System Components:
- Input (optional): A question or additional context
- Output: The content we want to validate
- Expected Result: Whether we expect it to be “Valid” or “Invalid”
- Confidence Threshold: The confidence threshold for validation
Automatic Test Scenario Generation
This system has the capability to automatically generate test scenarios based on the extracted rules:
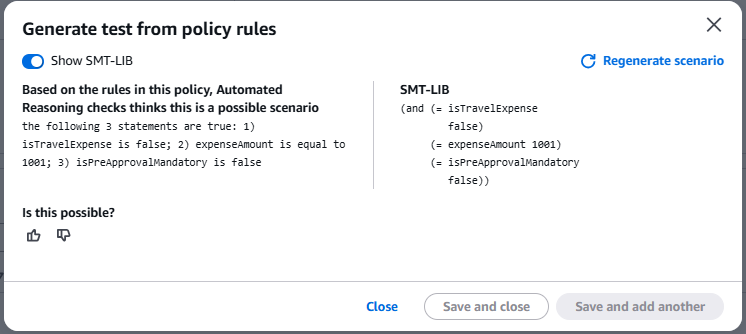 Figure 10: Automatic test scenario generation with SMT-LIB logic
Figure 10: Automatic test scenario generation with SMT-LIB logic
Automatic Generation Analysis:
The system analyzes the extracted policy rules and proposes realistic scenarios for validation:
Escenario Generado:
"The following 3 statements are true:
1) isTravelExpense is false;
2) expenseAmount is equal to 1001;
3) isPreApprovalMandatory is false"
Pregunta del Sistema: "Is this possible?"
Handling Issues: Unused Variables and Types
During automatic extraction, the system identifies issues that require attention:
 Figure 11: Extracted variables showing issues with unused elements
Figure 11: Extracted variables showing issues with unused elements
Types of Issues Identified:
- Unused Variable: Variables extracted but not referenced in any rule
- Impact: Doesn’t affect functionality but indicates potentially disconnected information
- Unused Values: Values in custom types not used in rules
- Impact: Incomplete policies or obsolete values
- Unused Type: Complete custom types not referenced in any validations
- Impact: Indicates extracted categories not used in validations
Validating the Scenario Against Our Real Policies
This automatically generated scenario reveals something extraordinary: the system detected a real ambiguity in our policy document.
Scenario Analysis:
- NOT a travel expense (
isTravelExpense = false) - Amount: $1,001 (
expenseAmount = 1001) - NO pre-approval required (
isPreApprovalMandatory = false)
Reviewing Our Policies:
According to our “Expense and Procurement Policy” document:
Approval Matrix (Section 3.1):
- $501-$2,000: Department manager approval required
Pre-Approval Requirements (Section 3.2):
- “Travel expenses exceeding $1,000” (but this is NOT travel)
- “Technology purchases exceeding $1,000”
- “Conference and training expenses”
- “Any expense exceeding daily/event limits”
The Automatically Detected Problem:
The system identified a potential inconsistency that we as humans overlooked:
According to our document as written: IT IS POSSIBLE that a non-travel expense of $1,001 would NOT require pre-approval.
The Critical Question Revealed: “Do we really want someone to be able to spend $1,001 on office supplies without pre-approval?”
The business answer is probably NO, but the written document technically allows it.
Recommended Resolution:
To eliminate this ambiguity, the policy should be clarified:
Regla Clarificada Sugerida:
"Any single expense exceeding $1,000, regardless of category,
requires mandatory pre-approval AND department manager approval."
Nueva Regla SMT-LIB:
(assert (=> (> expenseAmount 1000) (= isPreApprovalMandatory true)))
🔍 ProTip: The system isn’t “wrong” — it’s being mathematically precise according to the written document. This is exactly what we want: automatic detection of gaps between business intent and actual documentation. It’s automated policy auditing that finds problems before they cause real issues.
The Visible Power of SMT-LIB
The “Show SMT-LIB” option reveals the underlying formal logical representation. According to official AWS documentation, SMT-LIB (Satisfiability Modulo Theories Library) is the industry standard for formal verification.
Translation example:
Política Original: "Travel expenses over $1,000 require pre-approval"
SMT-LIB Generado:
(assert (=> (and (= isTravelExpense true) (> expenseAmount 1000))
(= isPreApprovalMandatory true)))
The Confidence Threshold: Granular Precision Control
The Confidence Threshold is one of the most sophisticated aspects of Automated Reasoning and works in a fundamentally different way than you might expect:
🎯 How the Confidence Threshold Really Works
According to official AWS documentation:
“Automated Reasoning uses multiple large language models (LLMs) to translate natural language tests into findings. It returns only ‘confident’ findings that are supported by a significant percentage of the LLM translations. The confidence threshold defines the minimum percentage of support needed for a translation to become a finding with a validity result.”
What this means in practice:
Automated Reasoning doesn’t use a single LLM to translate natural language to formal logic. Instead:
- Multiple LLMs process independently the same input
- Each LLM attempts to translate natural language to formal SMT-LIB logic
- The system compares translations from all LLMs
- It only returns findings where enough LLMs agree
Threshold Configuration:
- Threshold = 0.5 (50%): At least half the LLMs must agree on the translation
- Threshold = 0.8 (80%): At least 4 out of 5 LLMs must agree
- Threshold = 1.0 (100%): All LLMs must agree (maximum precision)
Trade-offs:
| Threshold | Precision | Coverage | Best For |
|---|---|---|---|
| 0.5-0.7 | Moderate | High | General validations, prototyping |
| 0.8-0.9 | High | Moderate | Standard production applications |
| 1.0 | Maximum | Lower | Critical applications (finance, health, legal) |
Practical recommendation:
# Para aplicaciones críticas donde la precisión es paramount
confidence_threshold = 1.0 # Todos los LLMs deben concordar
# Para aplicaciones de producción balanceadas
confidence_threshold = 0.8 # 80% de LLMs deben concordar
# Para prototipado y exploración
confidence_threshold = 0.5 # 50% de LLMs deben concordar
🔍 Technical Insight: The confidence threshold is NOT a measure of “how confident the model is” — it’s a measure of how many independent models reached the same conclusion. It’s verification through distributed consensus, analogous to how blockchain works but applied to logical reasoning.
Implication for TRANSLATION_AMBIGUOUS: When you receive this result, it means the LLMs couldn’t reach the threshold of agreement. This may indicate genuinely ambiguous language, multiple valid interpretations, insufficient variable descriptions, or inherent complexity requiring clarification.
The correct response is to improve the clarity of the input or variable descriptions, not simply lower the threshold.
Best Practices to Minimize Issues
1. Post-Extraction Review:
- Review ‘Unused’ variables and determine if additional rules are needed
- Validate that all custom type values are used in policies
- Create specific rules for unused approval variables
2. Iterative Refinement:
- First iteration: Accept the initial automatic extraction
- Second iteration: Create additional rules for unused variables
- Third iteration: Optimize custom types by removing obsolete values
- Fourth iteration: Validate full policy coverage
🔍 ProTip: Issues are not errors, but optimization opportunities. “Unused” variables often indicate policies that could benefit from additional rules for greater coverage and precision.
Advanced Configuration in Guardrails
Now that we’ve seen how extraction works, let’s look at how to optimize this process by extending our Guardrail to use the policies we’ve created.
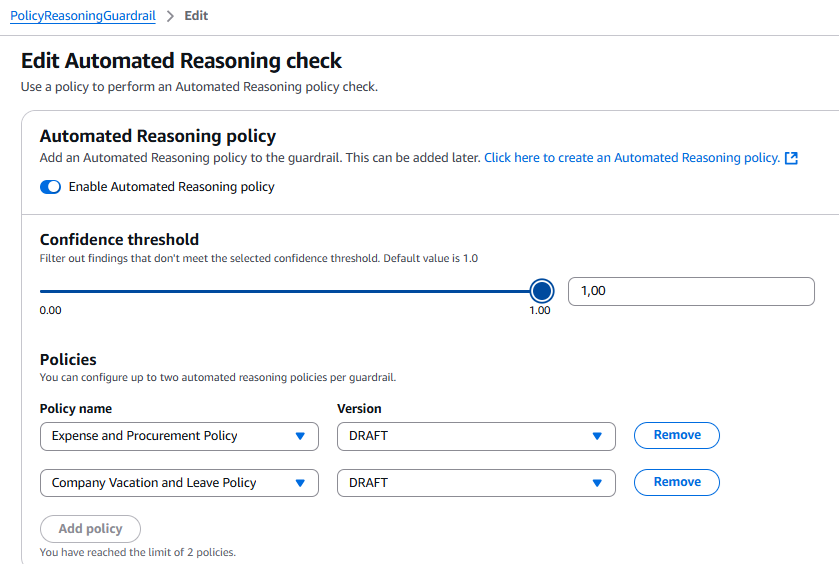 Figure 12: Integration of Guardrails and Automated Reasoning
Figure 12: Integration of Guardrails and Automated Reasoning
This configuration shows:
- Automated Reasoning policy enabled
- Confidence threshold set to 1.0 (maximum precision)
- Policies configured: Expense and Procurement Policy + Company Vacation and Leave Policy
- Limit of 2 policies per guardrail clearly visible
Step 3: Implementing and Testing the Python Client
Now we’ll implement a Python client that validates responses in real time against our policies with mathematical verification.
Implementation Code
The full code is available in my GitHub repository: bedrock-automated-reasoning/test_automated_reasoning.py
Here are the key components:
1. Initial Configuration:
import boto3
import json
# Configuración
REGION = "us-east-1"
MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0"
GUARDRAIL_ID = "tu-guardrail-id" # Reemplaza con tu ID
GUARDRAIL_VERSION = "DRAFT" # Es recomendable que uses versiones
client = boto3.client("bedrock-runtime", region_name=REGION)
2. Invocation with Guardrail:
response = client.converse(
modelId=MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
guardrailConfig={
"guardrailIdentifier": GUARDRAIL_ID,
"guardrailVersion": GUARDRAIL_VERSION,
"trace": "enabled", # CRÍTICO para ver verificación
}
)
3. Findings Analysis (Excerpt):
for finding in findings:
# SATISFIABLE: Lógicamente consistente
if 'satisfiable' in finding:
print("✅ SATISFIABLE")
print(f"Confidence: {finding['satisfiable']['translation']['confidence']}")
# VALID: Matemáticamente correcto
elif 'valid' in finding:
print("✅ VALID")
# CRÍTICO: Revisar untranslatedClaims
if 'untranslatedClaims' in finding['valid']['translation']:
print("⚠️ ADVERTENCIA: Claims NO verificados matemáticamente")
# INVALID: Contradicción detectada
elif 'invalid' in finding:
print("❌ INVALID - Contradicción con políticas")
💻 Full Code: The complete script with handling for all finding types is available on GitHub.
Running the Test
From your AWS CloudShell or local environment with configured credentials (make sure boto3 is up to date):
# Ejecutar script
python test_automated_reasoning.py
Analysis of Real Results
Here’s the actual output from running with our Guardrail:
Enviando prompt al modelo con Guardrail habilitado...
================================================================================
=== RESPUESTA DEL MODELO ===
Based on the information provided, as a new full-time employee with less than
1 year of service, you are likely entitled to 15 vacation days for the year.
However, here are a few key points to keep in mind:
1. Accrual: The 15 vacation days are typically accrued over the course of the
year, not given upfront.
2. Waiting period: There may be a waiting period, often around 90 days.
3. Manager approval: Using vacation days is usually subject to manager approval.
4. Rollover policy: Check the company's policy on whether unused vacation days
can be rolled over.
================================================================================
=== ANÁLISIS DE VERIFICACIÓN MATEMÁTICA ===
================================================================================
📊 MÉTRICAS DE RENDIMIENTO:
Latencia total: 11423ms (11.4s)
Automated Reasoning Units: 2
Políticas evaluadas: 1
Caracteres verificados: 1181
🔍 FINDINGS DETECTADOS: 4
================================================================================
────────────────────────────────────────────────────────────────────────────────
FINDING #1
────────────────────────────────────────────────────────────────────────────────
✅ Tipo: SATISFIABLE (lógicamente consistente)
Confidence: 1.00
📋 PREMISAS EXTRAÍDAS:
• employmentType is equal to FULL_TIME
• yearsOfService is less than 1
✓ CLAIMS VERIFICADOS:
• fullTimeVacationEntitlement is equal to 15
💡 Escenario donde los claims son VERDADEROS:
• fullTimeVacationEntitlement is equal to 15
• employmentType is equal to FULL_TIME
• yearsOfService is equal to -1
Critical Observation about yearsOfService = -1:
────────────────────────────────────────────────────────────────────────────────
FINDING #2
────────────────────────────────────────────────────────────────────────────────
✅ Tipo: VALID (matemáticamente correcto)
Confidence: 1.00
✓ CLAIMS VERIFICADOS:
• true
⚠️ ADVERTENCIA: CLAIMS NO TRADUCIDOS
======================================================================
El siguiente contenido NO fue verificado matemáticamente:
======================================================================
📝 "Vacation time is usually accrued over the course of the year..."
📝 "There may be a waiting period, like 90 days..."
📝 "Usage of vacation days is often subject to manager approval..."
📝 "Unused vacation days may or may not rollover..."
⚠️ IMPLICACIÓN:
Estas afirmaciones podrían ser alucinaciones. El modelo las agregó
pero no pudieron ser verificadas contra las políticas formales.
────────────────────────────────────────────────────────────────────────────────
FINDING #3
────────────────────────────────────────────────────────────────────────────────
✅ Tipo: VALID (matemáticamente correcto)
Confidence: 1.00
⚠️ DESCUBRIMIENTO PRÁCTICO: untranslatedPremises
======================================================================
Además de claims no traducidos, también detectamos PREMISAS no traducidas:
======================================================================
📝 "There may be a waiting period, like 90 days..."
⚠️ IMPLICACIÓN CRÍTICA:
No solo las conclusiones pueden ser no verificadas, sino también el
CONTEXTO DE ENTRADA. Esto significa que el modelo podría estar basando
su respuesta en premisas que no fueron validadas matemáticamente.
Finding #1: SATISFIABLE con Confidence 1.0
Premisas: employmentType = FULL_TIME AND yearsOfService < 1
Claim verificado: fullTimeVacationEntitlement = 15
Automated Reasoning Units: 2
Critical Interpretation of Results
This real trace reveals fundamental insights about how Automated Reasoning works:
1. The Main Claim Was Mathematically Verified
Finding #1: SATISFIABLE with Confidence 1.0 — All LLMs agreed (confidence 1.0) that 15 days is correct according to the policy.
2. untranslatedClaims: The Critical Limitation
Findings #2 and #3 reveal that the model added information that could not be mathematically verified:
- ✅ “15 vacation days” → Verified (100% of LLMs agreed)
- ⚠️ “Accrual of 1.25 days per month” → NOT verified
- ⚠️ “90-day waiting period” → NOT verified
- ⚠️ “Manager approval required” → NOT verified
3. untranslatedPremises: Practical Discovery
Finding #3 reveals something not officially documented by AWS but critical: premises can also be unverified. This means not just conclusions can be hallucinations, but also the context they’re based on.
4. Real Latency: 11.4 seconds
This latency is typical and varies with policy complexity. For production applications:
- Implement caching for frequent queries
- Design UX that handles variable latency gracefully
- Consider asynchronous processing for non-critical queries
Step 4: Refinement with Annotations - Correcting Policies Through Iterative Testing
After running tests and detecting problems, the next critical step is refining your policy through annotations.
What are Annotations?
Annotations are corrections or improvements you apply to your policy when tests reveal problems or gaps in the initial automatic extraction. They’re the primary mechanism for iterating and perfecting policies.
According to official AWS documentation:
“Annotations are corrections you apply to repair your policy when tests fail. If a test doesn’t return your expected result, you can modify the test conditions, rerun it, and apply the successful modification as an annotation to update your policy.”
When to Use Annotations:
- Correcting incorrect rules: When Automated Reasoning misinterpreted your source document
- Adding missing variables: When important concepts weren’t extracted
- Improving variable descriptions: When translations are inconsistent or ambiguous
- Resolving translation ambiguities: When tests frequently return TRANSLATION_AMBIGUOUS
- Filling coverage gaps: When policies have uncovered cases
🔍 ProTip: Annotations are the “fine-tuning” mechanism for your Automated Reasoning policy. The quality of your annotations directly determines the final accuracy of the system. Invest time in well-thought-out, documented annotations — it’s the difference between a mediocre and an excellent policy.
Step 5: Additional Test Cases
To fully understand the system’s behavior, here are additional scenarios documented in the repository:
Case 1: Direct Policy Violation
Query: “I want to take 16 consecutive vacation days next week.” Expected result: INVALID finding detecting that 16 consecutive days require Director approval.
Case 2: Edge Case - Policy Boundary
Query: “I have exactly 2 years of service. How many vacation days do I get?” Challenge: The policy says “0-2 years: 15 days” vs “3-5 years: 20 days”. Does exactly 2 years = 15 or 20?
Case 3: IMPOSSIBLE Finding
Query: “What benefits do employees get if they work negative hours?” Result: IMPOSSIBLE - premises are logically incorrect.
Case 4: TOO_COMPLEX Finding
Query: Extremely long response with hundreds of interconnected claims. Result: TOO_COMPLEX - exceeds processing limits.
Validation Result Types 📋
The official AWS documentation defines 7 possible result types. It’s critical to understand each:
VALID: Claims are mathematically correct per policies. Warning: Always check the untranslatedClaims field.
INVALID: Claims contradict policies. The response is demonstrably incorrect.
SATISFIABLE: Claims are consistent with at least one interpretation of policies, but may not address all relevant rules.
IMPOSSIBLE: A statement cannot be made about the claims. Occurs when premises are logically incorrect or the policy has internal conflicts.
TRANSLATION_AMBIGUOUS: LLMs couldn’t agree on how to translate natural language to formal logic.
TOO_COMPLEX: Input exceeds processing limits.
NO_TRANSLATIONS: Some or all input could not be translated to formal logic.
Results Analysis: Verifiable Precision vs Probabilities 📊
Validation Method Comparison
| Aspect | Traditional Methods (LLMs) | Automated Reasoning |
|---|---|---|
| Precision | Variable by context | Up to 99% verifiable |
| Explainability | Confidence scores | Verifiable logic proofs |
| Hallucination Detection | Reactive (post-generation) | Proactive (during generation) |
| Policy Handling | Semantic embeddings | Extracted formal logic |
| Traceability | Limited | Complete with justifications |
| Latency | ~100-500ms | ~1-15 additional seconds |
Sources:
- Vectara Hallucination Leaderboard (updated September 2025)
- Journal of Medical Internet Research - JMIR (various 2025 studies)
- HaluEval Study (referenced in 2025 benchmarks)
- Nature Digital Medicine (2025 studies)
Current Limitations and Considerations 🚧
Technical Restrictions
Language and Region Limitations:
- English (US) support only
- Available in regions: US East (N. Virginia), US East (Ohio), US West (Oregon), EU (Frankfurt), EU (Paris), EU (Ireland)
Functionality Limitations:
- Maximum 2 policies per guardrail
- Incompatibility with streaming APIs
- Variable latency: 1-15 additional seconds typical (our example: 11.4s)
- PDF and plain text only
- CloudFormation currently not supported
Content Limitations:
- Policy documents limited to 122,880 tokens (~100 pages)
- Policies must be in formal, structured language
- Doesn’t support images, diagrams, or complex tables within PDFs
Important Notes
1. Does Not Replace Human Review
Automated Reasoning provides mathematical verification, but:
- Doesn’t understand broader business context
- Cannot evaluate legal or ethical implications
- Doesn’t replace professional expert judgment
Recommendation: Use AR as a first line of defense, but maintain human review for critical decisions.
2. Requires Well-Structured Policies
The system is only as good as the policies it processes:
- Ambiguous policies generate poor extractions and low confidence
- Well-structured policies consistently produce confidence 1.0 results
3. Significant Variable Latency
Typical latency: 1-15 additional seconds (confirmed in our trace: 11.4s)
Recommendation: Implement caching for frequent queries; design UX that handles variable latency gracefully; consider asynchronous processing where possible.
When Automated Reasoning is NOT Effective
Cases Where Translation to Formal Logic Fails
1. Ambiguous or context-dependent policies:
# ❌ MAL - No se puede traducir a lógica formal
policy_text = """
Managers may use reasonable judgment to approve travel expenses
that exceed standard limits if business circumstances warrant it.
"""
# ✅ BIEN - Traducible a lógica formal
policy_text = """
Travel expenses exceeding standard limits require:
1. Manager approval if amount is $200-$500 over limit
2. Director approval if amount is $501-$1000 over limit
3. VP approval if amount exceeds limit by more than $1000
"""
2. Rules requiring subjective interpretation:
# ❌ MAL - "Exceptional circumstances" no es verificable matemáticamente
"Managers may approve in exceptional circumstances"
# ✅ BIEN - Condiciones específicas y verificables
"Managers may approve if: employee tenure > 5 years AND
previous year utilization < 80% AND business criticality = LOW"
3. Complex temporal dependencies:
# ❌ MAL - Lógica temporal compleja difícil de extraer
"Employees hired after Q3 must wait 90 days, unless hired in December,
in which case eligibility starts January 1st"
# ✅ BIEN - Reglas temporales simplificadas
"Employees eligible for benefits after 90 days of employment"
Final Reflections: The Future of Verifiable AI 🔮
Transformational Impact
After implementing and thoroughly testing Amazon Bedrock Guardrails Automated Reasoning Checks, it’s clear we’re witnessing a fundamental evolution in generative AI. This isn’t just an incremental improvement in accuracy; it’s a paradigm shift toward verifiable AI.
The ability to provide mathematically verifiable proofs instead of simple probabilities completely transforms the value proposition of LLMs for critical enterprise applications.
Key Lessons Learned
1. Policy Quality is Fundamental
The system is only as good as the policies it processes. During my implementation, I discovered that:
- Ambiguous policies generate poor extractions and low confidence
- Well-structured policies consistently produce confidence 1.0 results
- The initial investment in formally structuring policies pays off later
2. The Multi-LLM Approach is Revolutionary
Using multiple LLMs for consensus is what differentiates Automated Reasoning:
- Doesn’t trust a single model
- Requires agreement between models
- Achieves up to 99% precision through mathematical voting
3. Monitoring Unverified Content is CRITICAL
Our real example demonstrated that:
- Models can add reasonable but unverified information
- This includes
untranslatedClaimsanduntranslatedPremises - In critical contexts, this content must be explicitly handled
4. Variable Latency Requires Specific UX Design
Latencies of 11-14 seconds require:
- UX that handles waits gracefully
- Strategic caching
- Asynchronous processing where possible
5. ROI is Real for Appropriate Use Cases
In regulated industries (finance, healthcare, legal) where errors have costly consequences, the value in legal and reputational risk reduction is incalculable.
🚀 Final ProTip: Automated Reasoning Checks is not just a security feature; it’s a platform for building truly trustworthy generative AI applications. The investment in: properly structuring policies, implementing monitoring for untranslatedClaims/untranslatedPremises, designing UX for variable latency …will pay exponential dividends long-term.
An Invitation to Experiment
The future of generative AI is not just more creative or faster — it’s mathematically verifiable through multi-LLM consensus. And that future begins with the decision to formally structure the knowledge you already have.
Do you dare to experiment with Automated Reasoning Checks in your organization? What business policies would you like to verify mathematically? The technology is ready, and the possibilities are endless.
Additional Resources
Official Documentation:
- AWS Bedrock Guardrails - Automated Reasoning
- Bedrock API Reference - Guardrail Configuration
- SMT-LIB Standard
The revolution of verifiable AI is a journey worth taking together. Every successful implementation brings us closer to AI systems we can truly trust for critical decisions.



Start the conversation